 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiT-4-RSVQA: Lightweight Transformer-based Visual Question Answering in Remote Sensing
Paper and Code
Jun 02, 2023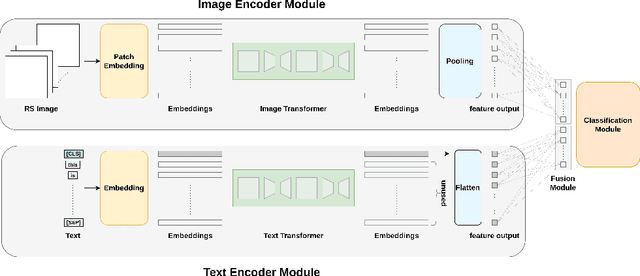
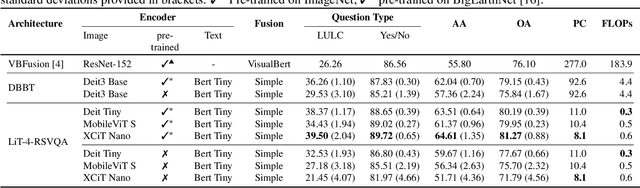
Visual question answering (VQA) methods in remote sensing (RS) aim to answer natural language questions with respect to an RS image. Most of the existing methods require a large amount of computational resources, which limits their application in operational scenarios in RS. To address this issue, in this paper we present an effective lightweight transformer-based VQA in RS (LiT-4-RSVQA) architecture for efficient and accurate VQA in RS. Our architecture consists of: i) a lightweight text encoder module; ii) a lightweight image encoder module; iii) a fusion module; and iv) a classification module. The experimental results obtained on a VQA benchmark dataset demonstrate that our proposed LiT-4-RSVQA architecture provides accurate VQA results while significantly reducing the computational requirements on the executing hardware. Our code is publicly available at https://git.tu-berlin.de/rsim/lit4rsvqa.