 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Fusion Transformer for Visual Question Answering in Remote Sensing
Paper and Code
Oct 10, 2022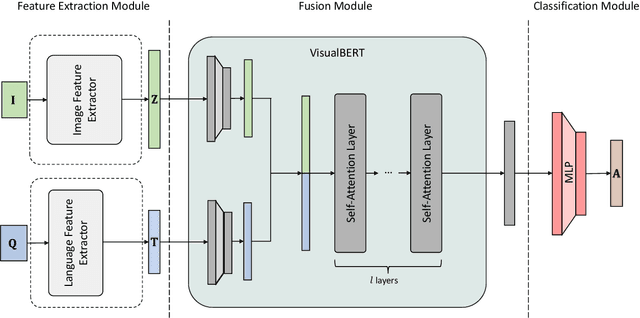
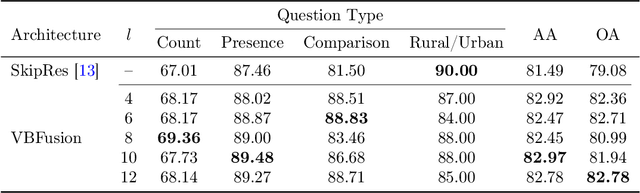
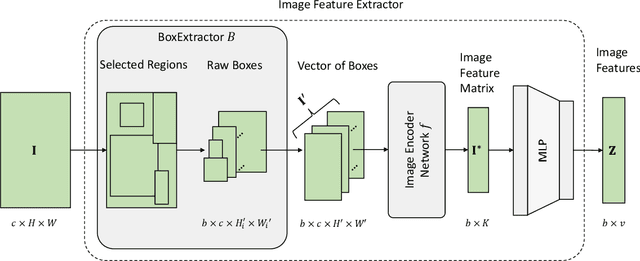
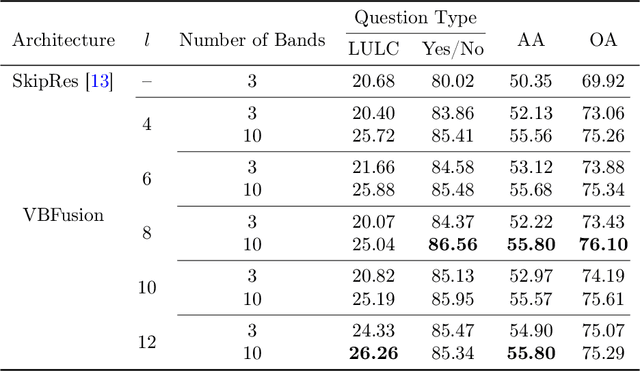
With the new generation of satellite technologies, the archives of remote sensing (RS) images are growing very fast. To make the intrinsic information of each RS image easily accessible, visual question answering (VQA) has been introduced in RS. VQA allows a user to formulate a free-form question concerning the content of RS images to extract generic information. It has been shown that the fusion of the input modalities (i.e., image and text) is crucial for the performance of VQA systems. Most of the current fusion approaches use modality-specific representations in their fusion modules instead of joint representation learning. However, to discover the underlying relation between both the image and question modality, the model is required to learn the joint representation instead of simply combining (e.g., concatenating, adding, or multiplying) the modality-specific representations. We propose a multi-modal transformer-based architecture to overcome this issue. Our proposed architecture consists of three main modules: i) the feature extraction module for extracting the modality-specific features; ii) the fusion module, which leverages a user-defined number of multi-modal transformer layers of the VisualBERT model (VB); and iii) the classification module to obtain the answer. Experimental results obtained on the RSVQAxBEN and RSVQA-LR datasets (which are made up of RGB bands of Sentinel-2 images) demonstrate the effectiveness of VBFusion for VQA tasks in RS. To analyze the importance of using other spectral bands for the description of the complex content of RS images in the framework of VQA, we extend the RSVQAxBEN dataset to include all the spectral bands of Sentinel-2 images with 10m and 20m spatial resolution.