 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture Dynamic 3D Reconstruction: A 3D World Model with Disentangled Ego-Motion
Jun 16, 2026Forecasting the evolution of dynamic environments is crucial for autonomous agents. While generative world models have recently achieved high photorealism in 2D video synthesis by mixing ego-motion and environmental dynamics within the image plane, they exhibit physical inconsistencies, such as morphing or vanishing objects, especially over long time horizons. In this paper, we propose FR3D, a world model that predicts a persistent 3D latent representation for future dynamic 3D reconstruction. Unlike prior works that treat the world as a sequence of image-based features, FR3D explicitly decouples the 3D evolution of the scene from the agent's trajectory, treating the inferred ego-motion as a latent proxy for action. This disentanglement resolves the ambiguities between self-motion and world-motion, ensuring geometric consistency into the future. Furthermore, we introduce a teacher-student distillation strategy that leverages the spatial "common sense" of off-the-shelf foundation models, leading to robust zero-shot generalization. Extensive experiments demonstrate FR3D's strong performance for future dynamic 3D reconstruction from monocular observations across multiple datasets, even 2 seconds into the future. Project page: https://fr3d-wm.github.io.
Unsupervised Traffic Scene Generation with Synthetic 3D Scene Graphs
Mar 15, 2023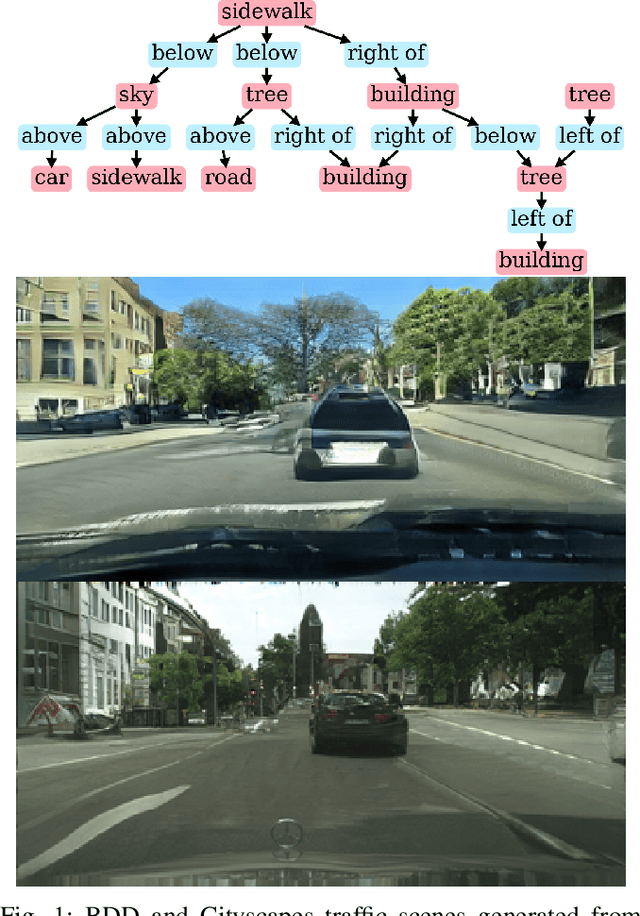
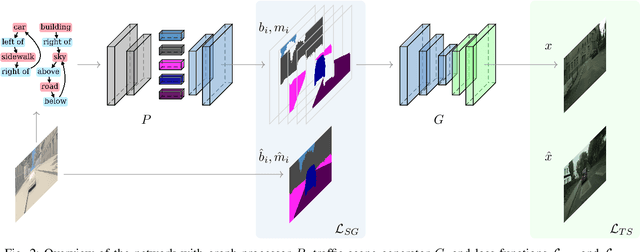
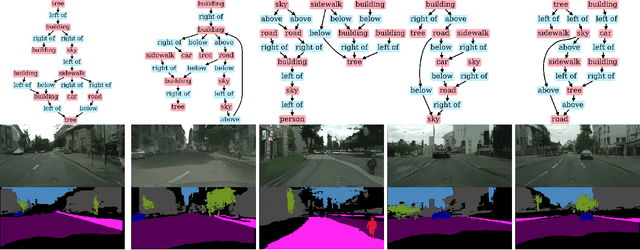

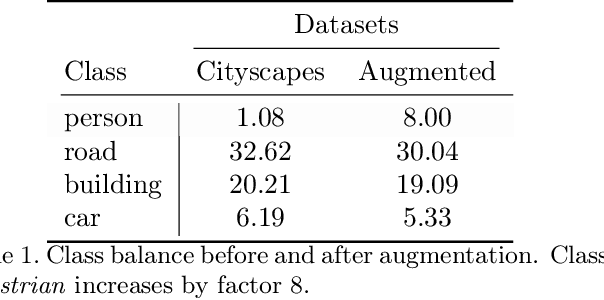
Image synthesis driven by computer graphics achieved recently a remarkable realism, yet synthetic image data generated this way reveals a significant domain gap with respect to real-world data. This is especially true in autonomous driving scenarios, which represent a critical aspect for overcoming utilizing synthetic data for training neural networks. We propose a method based on domain-invariant scene representation to directly synthesize traffic scene imagery without rendering. Specifically, we rely on synthetic scene graphs as our internal representation and introduce an unsupervised neural network architecture for realistic traffic scene synthesis. We enhance synthetic scene graphs with spatial information about the scene and demonstrate the effectiveness of our approach through scene manipulation.
Lidar Upsampling with Sliced Wasserstein Distance
Jan 31, 2023



Lidar became an important component of the perception systems in autonomous driving. But challenges of training data acquisition and annotation made emphasized the role of the sensor to sensor domain adaptation. In this work, we address the problem of lidar upsampling. Learning on lidar point clouds is rather a challenging task due to their irregular and sparse structure. Here we propose a method for lidar point cloud upsampling which can reconstruct fine-grained lidar scan patterns. The key idea is to utilize edge-aware dense convolutions for both feature extraction and feature expansion. Additionally applying a more accurate Sliced Wasserstein Distance facilitates learning of the fine lidar sweep structures. This in turn enables our method to employ a one-stage upsampling paradigm without the need for coarse and fine reconstruction. We conduct several experiments to evaluate our method and demonstrate that it provides better upsampling.
Attention-based Adversarial Appearance Learning of Augmented Pedestrians
Jul 06, 2021
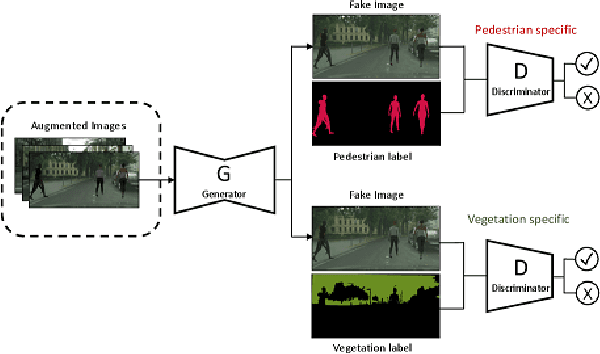
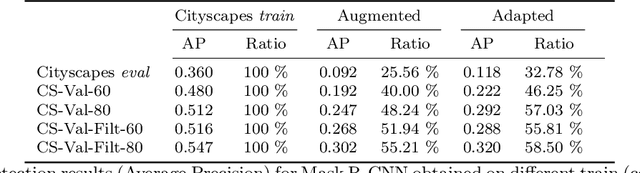
Synthetic data became already an essential component of machine learning-based perception in the field of autonomous driving. Yet it still cannot replace real data completely due to the sim2real domain shift. In this work, we propose a method that leverages the advantages of the augmentation process and adversarial training to synthesize realistic data for the pedestrian recognition task. Our approach utilizes an attention mechanism driven by an adversarial loss to learn domain discrepancies and improve sim2real adaptation. Our experiments confirm that the proposed adaptation method is robust to such discrepancies and reveals both visual realism and semantic consistency. Furthermore, we evaluate our data generation pipeline on the task of pedestrian recognition and demonstrate that generated data resemble properties of the real domain.
Content Disentanglement for Semantically Consistent Synthetic-to-Real Domain Adaptation
May 27, 2021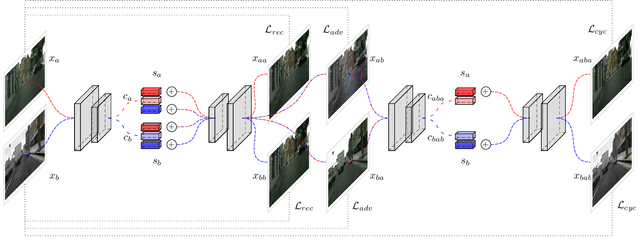



Synthetic data generation is an appealing approach to generate novel traffic scenarios in autonomous driving. However, deep learning techniques trained solely on synthetic data encounter dramatic performance drops when they are tested on real data. Such performance drop is commonly attributed to the domain gap between real and synthetic data. Domain adaptation methods have been applied to mitigate the aforementioned domain gap. These methods achieve visually appealing results, but the translated samples usually introduce semantic inconsistencies. In this work, we propose a new, unsupervised, end-to-end domain adaptation network architecture that enables semantically consistent domain adaptation between synthetic and real data. We evaluate our architecture on the downstream task of semantic segmentation and show that our method achieves superior performance compared to the state-of-the-art methods.
KLIEP-based Density Ratio Estimation for Semantically Consistent Synthetic to Real Images Adaptation in Urban Traffic Scenes
May 26, 2021

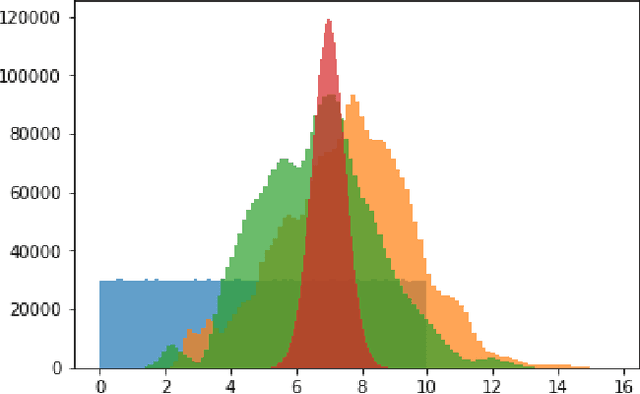

Synthetic data has been applied in many deep learning based computer vision tasks. Limited performance of algorithms trained solely on synthetic data has been approached with domain adaptation techniques such as the ones based on generative adversarial framework. We demonstrate how adversarial training alone can introduce semantic inconsistencies in translated images. To tackle this issue we propose density prematching strategy using KLIEP-based density ratio estimation procedure. Finally, we show that aforementioned strategy improves quality of translated images of underlying method and their usability for the semantic segmentation task in the context of autonomous driving.
Automated Scene Flow Data Generation for Training and Verification
Aug 31, 2018
Scene flow describes the 3D position as well as the 3D motion of each pixel in an image. Such algorithms are the basis for many state-of-the-art autonomous or automated driving functions. For verification and training large amounts of ground truth data is required, which is not available for real data. In this paper, we demonstrate a technology to create synthetic data with dense and precise scene flow ground truth.