 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountGD++: Generalized Prompting for Open-World Counting
Dec 29, 2025The flexibility and accuracy of methods for automatically counting objects in images and videos are limited by the way the object can be specified. While existing methods allow users to describe the target object with text and visual examples, the visual examples must be manually annotated inside the image, and there is no way to specify what not to count. To address these gaps, we introduce novel capabilities that expand how the target object can be specified. Specifically, we extend the prompt to enable what not to count to be described with text and/or visual examples, introduce the concept of `pseudo-exemplars' that automate the annotation of visual examples at inference, and extend counting models to accept visual examples from both natural and synthetic external images. We also use our new counting model, CountGD++, as a vision expert agent for an LLM. Together, these contributions expand the prompt flexibility of multi-modal open-world counting and lead to significant improvements in accuracy, efficiency, and generalization across multiple datasets. Code is available at https://github.com/niki-amini-naieni/CountGDPlusPlus.
Open-World Object Counting in Videos
Jun 18, 2025
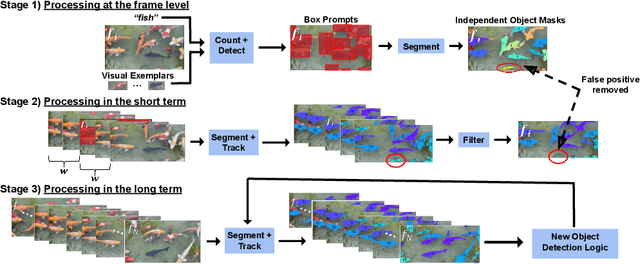
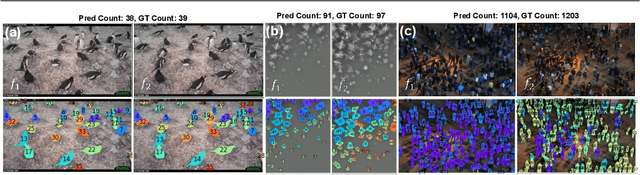
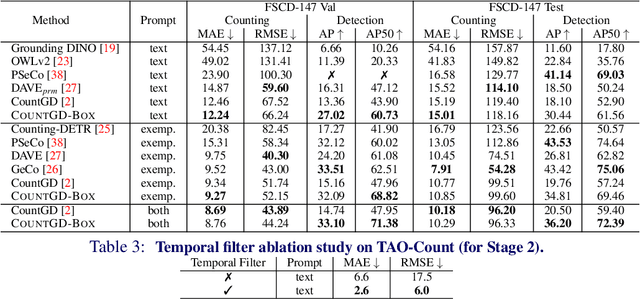
We introduce a new task of open-world object counting in videos: given a text description, or an image example, that specifies the target object, the objective is to enumerate all the unique instances of the target objects in the video. This task is especially challenging in crowded scenes with occlusions and similar objects, where avoiding double counting and identifying reappearances is crucial. To this end, we make the following contributions: we introduce a model, CountVid, for this task. It leverages an image-based counting model, and a promptable video segmentation and tracking model to enable automated, open-world object counting across video frames. To evaluate its performance, we introduce VideoCount, a new dataset for our novel task built from the TAO and MOT20 tracking datasets, as well as from videos of penguins and metal alloy crystallization captured by x-rays. Using this dataset, we demonstrate that CountVid provides accurate object counts, and significantly outperforms strong baselines. The VideoCount dataset, the CountVid model, and all the code are available at https://github.com/niki-amini-naieni/CountVid/.
Benchmarking Vision Foundation Models for Input Monitoring in Autonomous Driving
Jan 14, 2025Deep neural networks (DNNs) remain challenged by distribution shifts in complex open-world domains like automated driving (AD): Absolute robustness against yet unknown novel objects (semantic shift) or styles like lighting conditions (covariate shift) cannot be guaranteed. Hence, reliable operation-time monitors for identification of out-of-training-data-distribution (OOD) scenarios are imperative. Current approaches for OOD classification are untested for complex domains like AD, are limited in the kinds of shifts they detect, or even require supervision with OOD samples. To prepare for unanticipated shifts, we instead establish a framework around a principled, unsupervised, and model-agnostic method that unifies detection of all kinds of shifts: Find a full model of the training data's feature distribution, to then use its density at new points as in-distribution (ID) score. To implement this, we propose to combine the newly available Vision Foundation Models (VFM) as feature extractors with one of four alternative density modeling techniques. In an extensive benchmark of 4 VFMs against 20 baselines, we show the superior performance of VFM feature encodings compared to shift-specific OOD monitors. Additionally, we find that sophisticated architectures outperform larger latent space dimensionality; and our method identifies samples with higher risk of errors on downstream tasks, despite being model-agnostic. This suggests that VFMs are promising to realize model-agnostic, unsupervised, reliable safety monitors in complex vision tasks.
Unveiling Ontological Commitment in Multi-Modal Foundation Models
Sep 25, 2024



Ontological commitment, i.e., used concepts, relations, and assumptions, are a corner stone of qualitative reasoning (QR) models. The state-of-the-art for processing raw inputs, though, are deep neural networks (DNNs), nowadays often based off from multimodal foundation models. These automatically learn rich representations of concepts and respective reasoning. Unfortunately, the learned qualitative knowledge is opaque, preventing easy inspection, validation, or adaptation against available QR models. So far, it is possible to associate pre-defined concepts with latent representations of DNNs, but extractable relations are mostly limited to semantic similarity. As a next step towards QR for validation and verification of DNNs: Concretely, we propose a method that extracts the learned superclass hierarchy from a multimodal DNN for a given set of leaf concepts. Under the hood we (1) obtain leaf concept embeddings using the DNN's textual input modality; (2) apply hierarchical clustering to them, using that DNNs encode semantic similarities via vector distances; and (3) label the such-obtained parent concepts using search in available ontologies from QR. An initial evaluation study shows that meaningful ontological class hierarchies can be extracted from state-of-the-art foundation models. Furthermore, we demonstrate how to validate and verify a DNN's learned representations against given ontologies. Lastly, we discuss potential future applications in the context of QR.
CountGD: Multi-Modal Open-World Counting
Jul 05, 2024



The goal of this paper is to improve the generality and accuracy of open-vocabulary object counting in images. To improve the generality, we repurpose an open-vocabulary detection foundation model (GroundingDINO) for the counting task, and also extend its capabilities by introducing modules to enable specifying the target object to count by visual exemplars. In turn, these new capabilities - being able to specify the target object by multi-modalites (text and exemplars) - lead to an improvement in counting accuracy. We make three contributions: First, we introduce the first open-world counting model, CountGD, where the prompt can be specified by a text description or visual exemplars or both; Second, we show that the performance of the model significantly improves the state of the art on multiple counting benchmarks - when using text only, CountGD is comparable to or outperforms all previous text-only works, and when using both text and visual exemplars, we outperform all previous models; Third, we carry out a preliminary study into different interactions between the text and visual exemplar prompts, including the cases where they reinforce each other and where one restricts the other. The code and an app to test the model are available at https://www.robots.ox.ac.uk/~vgg/research/countgd/.
Calibrated Uncertainties for Neural Radiance Fields
Dec 04, 2023Neural Radiance Fields have achieved remarkable results for novel view synthesis but still lack a crucial component: precise measurement of uncertainty in their predictions. Probabilistic NeRF methods have tried to address this, but their output probabilities are not typically accurately calibrated, and therefore do not capture the true confidence levels of the model. Calibration is a particularly challenging problem in the sparse-view setting, where additional held-out data is unavailable for fitting a calibrator that generalizes to the test distribution. In this paper, we introduce the first method for obtaining calibrated uncertainties from NeRF models. Our method is based on a robust and efficient metric to calculate per-pixel uncertainties from the predictive posterior distribution. We propose two techniques that eliminate the need for held-out data. The first, based on patch sampling, involves training two NeRF models for each scene. The second is a novel meta-calibrator that only requires the training of one NeRF model. Our proposed approach for obtaining calibrated uncertainties achieves state-of-the-art uncertainty in the sparse-view setting while maintaining image quality. We further demonstrate our method's effectiveness in applications such as view enhancement and next-best view selection.
Open-world Text-specified Object Counting
Jun 02, 2023Our objective is open-world object counting in images, where the target object class is specified by a text description. To this end, we propose CounTX, a class-agnostic, single-stage model using a transformer decoder counting head on top of pre-trained joint text-image representations. CounTX is able to count the number of instances of any class given only an image and a text description of the target object class, and can be trained end-to-end. To the best of our knowledge, we are the first to tackle the open-world counting problem in this way. In addition to this model, we make the following contributions: (i) we compare the performance of CounTX to prior work on open-world object counting, and show that our approach exceeds the state of the art on all measures on the FSC-147 benchmark for methods that use text to specify the task; (ii) we present and release FSC-147-D, an enhanced version of FSC-147 with text descriptions, so that object classes can be described with more detailed language than their simple class names. FSC-147-D is available at https://github.com/niki-amini-naieni/CounTX/.