 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Embedding Analysis: A Review
Paper and Code
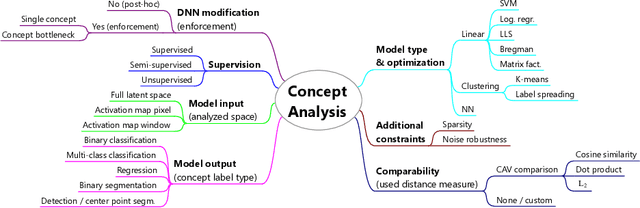



Deep neural networks (DNNs) have found their way into many applications with potential impact on the safety, security, and fairness of human-machine-systems. Such require basic understanding and sufficient trust by the users. This motivated the research field of explainable artificial intelligence (XAI), i.e. finding methods for opening the "black-boxes" DNNs represent. For the computer vision domain in specific, practical assessment of DNNs requires a globally valid association of human interpretable concepts with internals of the model. The research field of concept (embedding) analysis (CA) tackles this problem: CA aims to find global, assessable associations of humanly interpretable semantic concepts (e.g., eye, bearded) with internal representations of a DNN. This work establishes a general definition of CA and a taxonomy for CA methods, uniting several ideas from literature. That allows to easily position and compare CA approaches. Guided by the defined notions, the current state-of-the-art research regarding CA methods and interesting applications are reviewed. More than thirty relevant methods are discussed, compared, and categorized. Finally, for practitioners, a survey of fifteen datasets is provided that have been used for supervised concept analysis. Open challenges and research directions are pointed out at the end.