 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Image Editing Foundation Models for Data-Efficient CT Metal Artifact Reduction
Apr 07, 2026Metal artifacts from high-attenuation implants severely degrade CT image quality, obscuring critical anatomical structures and posing a challenge for standard deep learning methods that require extensive paired training data. We propose a paradigm shift: reframing artifact reduction as an in-context reasoning task by adapting a general-purpose vision-language diffusion foundation model via parameter-efficient Low-Rank Adaptation (LoRA). By leveraging rich visual priors, our approach achieves effective artifact suppression with only 16 to 128 paired training examples reducing data requirements by two orders of magnitude. Crucially, we demonstrate that domain adaptation is essential for hallucination mitigation; without it, foundation models interpret streak artifacts as erroneous natural objects (e.g., waffles or petri dishes). To ground the restoration, we propose a multi-reference conditioning strategy where clean anatomical exemplars from unrelated subjects are provided alongside the corrupted input, enabling the model to exploit category-specific context to infer uncorrupted anatomy. Extensive evaluation on the AAPM CT-MAR benchmark demonstrates that our method achieves state-of-the-art performance on perceptual and radiological-feature metrics . This work establishes that foundation models, when appropriately adapted, offer a scalable alternative for interpretable, data-efficient medical image reconstruction. Code is available at https://github.com/ahmetemirdagi/CT-EditMAR.
Edit2Interp: Adapting Image Foundation Models from Spatial Editing to Video Frame Interpolation with Few-Shot Learning
Mar 16, 2026Pre-trained image editing models exhibit strong spatial reasoning and object-aware transformation capabilities acquired from billions of image-text pairs, yet they possess no explicit temporal modeling. This paper demonstrates that these spatial priors can be repurposed to unlock temporal synthesis capabilities through minimal adaptation - without introducing any video-specific architecture or motion estimation modules. We show that a large image editing model (Qwen-Image-Edit), originally designed solely for static instruction-based edits, can be adapted for Video Frame Interpolation (VFI) using only 64-256 training samples via Low-Rank Adaptation (LoRA). Our core contribution is revealing that the model's inherent understanding of "how objects transform" in static scenes contains latent temporal reasoning that can be activated through few-shot fine-tuning. While the baseline model completely fails at producing coherent intermediate frames, our parameter-efficient adaptation successfully unlocks its interpolation capability. Rather than competing with task-specific VFI methods trained from scratch on massive datasets, our work establishes that foundation image editing models possess untapped potential for temporal tasks, offering a data-efficient pathway for video synthesis in resource-constrained scenarios. This bridges the gap between image manipulation and video understanding, suggesting that spatial and temporal reasoning may be more intertwined in foundation models than previously recognized
Real-World Point Tracking with Verifier-Guided Pseudo-Labeling
Mar 12, 2026Models for long-term point tracking are typically trained on large synthetic datasets. The performance of these models degrades in real-world videos due to different characteristics and the absence of dense ground-truth annotations. Self-training on unlabeled videos has been explored as a practical solution, but the quality of pseudo-labels strongly depends on the reliability of teacher models, which vary across frames and scenes. In this paper, we address the problem of real-world fine-tuning and introduce verifier, a meta-model that learns to assess the reliability of tracker predictions and guide pseudo-label generation. Given candidate trajectories from multiple pretrained trackers, the verifier evaluates them per frame and selects the most trustworthy predictions, resulting in high-quality pseudo-label trajectories. When applied for fine-tuning, verifier-guided pseudo-labeling substantially improves the quality of supervision and enables data-efficient adaptation to unlabeled videos. Extensive experiments on four real-world benchmarks demonstrate that our approach achieves state-of-the-art results while requiring less data than prior self-training methods. Project page: https://kuis-ai.github.io/track_on_r
Track-On: Transformer-based Online Point Tracking with Memory
Jan 30, 2025



In this paper, we consider the problem of long-term point tracking, which requires consistent identification of points across multiple frames in a video, despite changes in appearance, lighting, perspective, and occlusions. We target online tracking on a frame-by-frame basis, making it suitable for real-world, streaming scenarios. Specifically, we introduce Track-On, a simple transformer-based model designed for online long-term point tracking. Unlike prior methods that depend on full temporal modeling, our model processes video frames causally without access to future frames, leveraging two memory modules -- spatial memory and context memory -- to capture temporal information and maintain reliable point tracking over long time horizons. At inference time, it employs patch classification and refinement to identify correspondences and track points with high accuracy. Through extensive experiments, we demonstrate that Track-On sets a new state-of-the-art for online models and delivers superior or competitive results compared to offline approaches on seven datasets, including the TAP-Vid benchmark. Our method offers a robust and scalable solution for real-time tracking in diverse applications. Project page: https://kuis-ai.github.io/track_on
Robust Bird's Eye View Segmentation by Adapting DINOv2
Sep 16, 2024



Extracting a Bird's Eye View (BEV) representation from multiple camera images offers a cost-effective, scalable alternative to LIDAR-based solutions in autonomous driving. However, the performance of the existing BEV methods drops significantly under various corruptions such as brightness and weather changes or camera failures. To improve the robustness of BEV perception, we propose to adapt a large vision foundational model, DINOv2, to BEV estimation using Low Rank Adaptation (LoRA). Our approach builds on the strong representation space of DINOv2 by adapting it to the BEV task in a state-of-the-art framework, SimpleBEV. Our experiments show increased robustness of BEV perception under various corruptions, with increasing gains from scaling up the model and the input resolution. We also showcase the effectiveness of the adapted representations in terms of fewer learnable parameters and faster convergence during training.
Can Visual Foundation Models Achieve Long-term Point Tracking?
Aug 24, 2024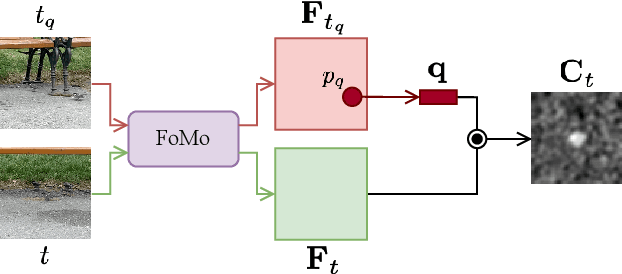
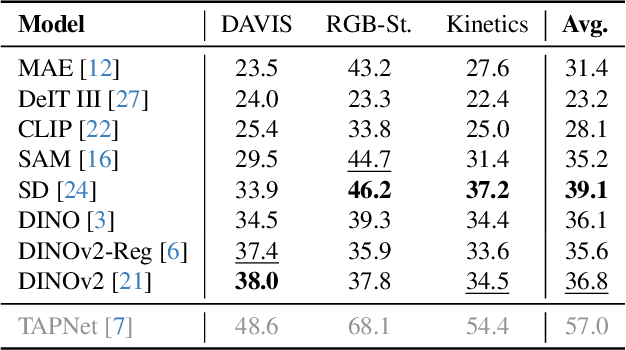
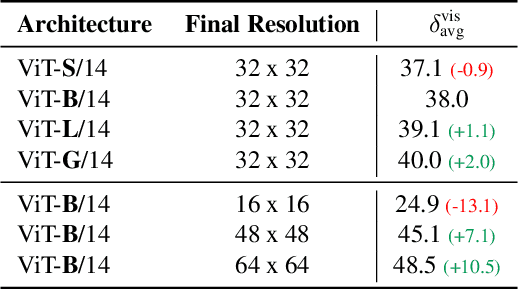
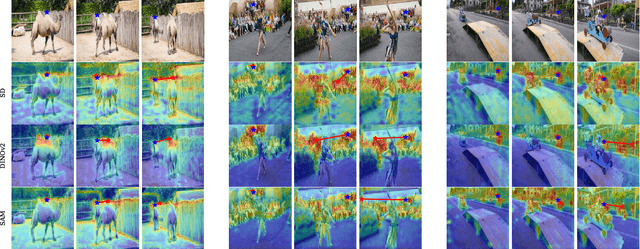
Large-scale vision foundation models have demonstrated remarkable success across various tasks, underscoring their robust generalization capabilities. While their proficiency in two-view correspondence has been explored, their effectiveness in long-term correspondence within complex environments remains unexplored. To address this, we evaluate the geometric awareness of visual foundation models in the context of point tracking: (i) in zero-shot settings, without any training; (ii) by probing with low-capacity layers; (iii) by fine-tuning with Low Rank Adaptation (LoRA). Our findings indicate that features from Stable Diffusion and DINOv2 exhibit superior geometric correspondence abilities in zero-shot settings. Furthermore, DINOv2 achieves performance comparable to supervised models in adaptation settings, demonstrating its potential as a strong initialization for correspondence learning.
Self-supervised Object-Centric Learning for Videos
Oct 10, 2023Unsupervised multi-object segmentation has shown impressive results on images by utilizing powerful semantics learned from self-supervised pretraining. An additional modality such as depth or motion is often used to facilitate the segmentation in video sequences. However, the performance improvements observed in synthetic sequences, which rely on the robustness of an additional cue, do not translate to more challenging real-world scenarios. In this paper, we propose the first fully unsupervised method for segmenting multiple objects in real-world sequences. Our object-centric learning framework spatially binds objects to slots on each frame and then relates these slots across frames. From these temporally-aware slots, the training objective is to reconstruct the middle frame in a high-level semantic feature space. We propose a masking strategy by dropping a significant portion of tokens in the feature space for efficiency and regularization. Additionally, we address over-clustering by merging slots based on similarity. Our method can successfully segment multiple instances of complex and high-variety classes in YouTube videos.
ADAPT: Efficient Multi-Agent Trajectory Prediction with Adaptation
Jul 26, 2023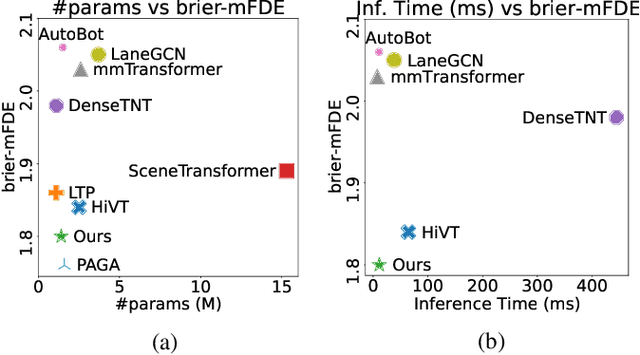
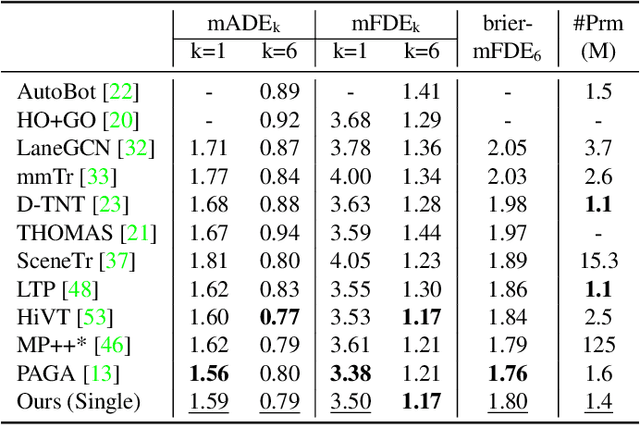

Forecasting future trajectories of agents in complex traffic scenes requires reliable and efficient predictions for all agents in the scene. However, existing methods for trajectory prediction are either inefficient or sacrifice accuracy. To address this challenge, we propose ADAPT, a novel approach for jointly predicting the trajectories of all agents in the scene with dynamic weight learning. Our approach outperforms state-of-the-art methods in both single-agent and multi-agent settings on the Argoverse and Interaction datasets, with a fraction of their computational overhead. We attribute the improvement in our performance: first, to the adaptive head augmenting the model capacity without increasing the model size; second, to our design choices in the endpoint-conditioned prediction, reinforced by gradient stopping. Our analyses show that ADAPT can focus on each agent with adaptive prediction, allowing for accurate predictions efficiently. https://KUIS-AI.github.io/adapt
Trajectory Forecasting on Temporal Graphs
Jul 01, 2022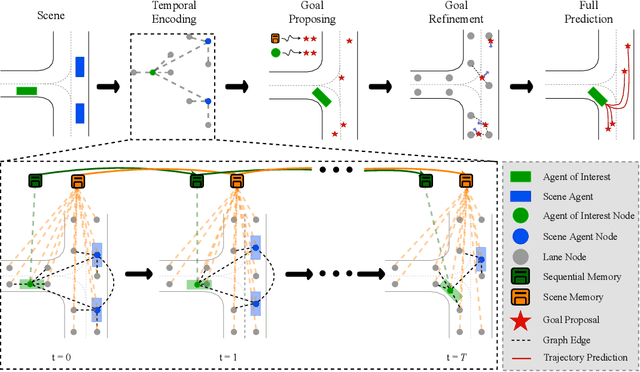
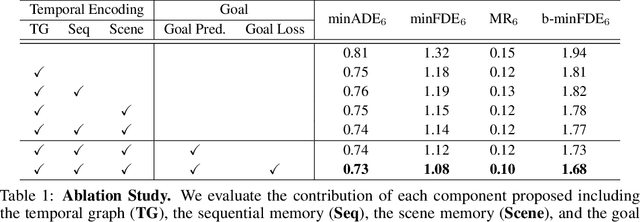
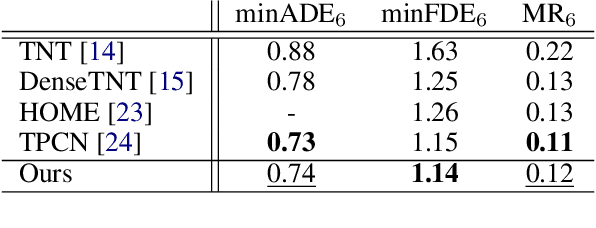
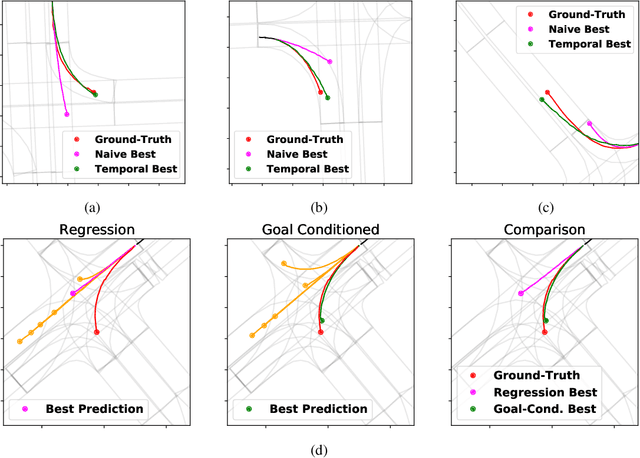
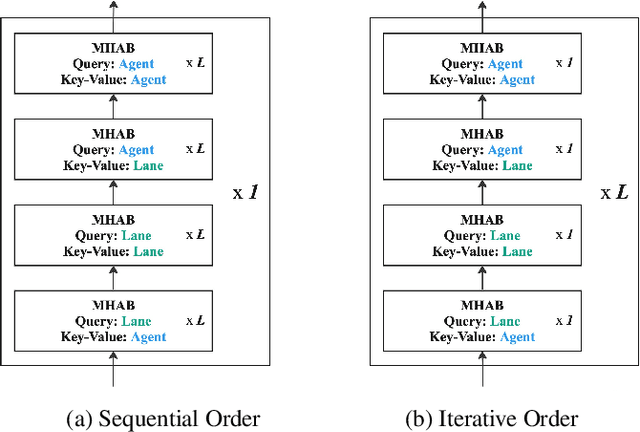
Predicting future locations of agents in the scene is an important problem in self-driving. In recent years, there has been a significant progress in representing the scene and the agents in it. The interactions of agents with the scene and with each other are typically modeled with a Graph Neural Network. However, the graph structure is mostly static and fails to represent the temporal changes in highly dynamic scenes. In this work, we propose a temporal graph representation to better capture the dynamics in traffic scenes. We complement our representation with two types of memory modules; one focusing on the agent of interest and the other on the entire scene. This allows us to learn temporally-aware representations that can achieve good results even with simple regression of multiple futures. When combined with goal-conditioned prediction, we show better results that can reach the state-of-the-art performance on the Argoverse benchmark.