 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Video Synthesis by Temporal Object-Centric Learning
Jul 28, 2025We present a novel framework for compositional video synthesis that leverages temporally consistent object-centric representations, extending our previous work, SlotAdapt, from images to video. While existing object-centric approaches either lack generative capabilities entirely or treat video sequences holistically, thus neglecting explicit object-level structure, our approach explicitly captures temporal dynamics by learning pose invariant object-centric slots and conditioning them on pretrained diffusion models. This design enables high-quality, pixel-level video synthesis with superior temporal coherence, and offers intuitive compositional editing capabilities such as object insertion, deletion, or replacement, maintaining consistent object identities across frames. Extensive experiments demonstrate that our method sets new benchmarks in video generation quality and temporal consistency, outperforming previous object-centric generative methods. Although our segmentation performance closely matches state-of-the-art methods, our approach uniquely integrates this capability with robust generative performance, significantly advancing interactive and controllable video generation and opening new possibilities for advanced content creation, semantic editing, and dynamic scene understanding.
Slot-Guided Adaptation of Pre-trained Diffusion Models for Object-Centric Learning and Compositional Generation
Jan 27, 2025We present SlotAdapt, an object-centric learning method that combines slot attention with pretrained diffusion models by introducing adapters for slot-based conditioning. Our method preserves the generative power of pretrained diffusion models, while avoiding their text-centric conditioning bias. We also incorporate an additional guidance loss into our architecture to align cross-attention from adapter layers with slot attention. This enhances the alignment of our model with the objects in the input image without using external supervision. Experimental results show that our method outperforms state-of-the-art techniques in object discovery and image generation tasks across multiple datasets, including those with real images. Furthermore, we demonstrate through experiments that our method performs remarkably well on complex real-world images for compositional generation, in contrast to other slot-based generative methods in the literature. The project page can be found at $\href{https://kaanakan.github.io/SlotAdapt/}{\text{this https url}}$.
ADAPT: Efficient Multi-Agent Trajectory Prediction with Adaptation
Jul 26, 2023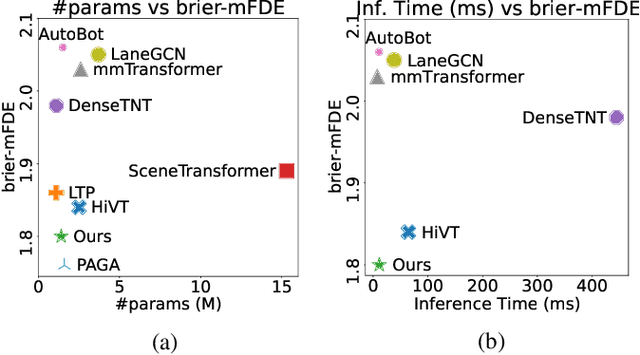
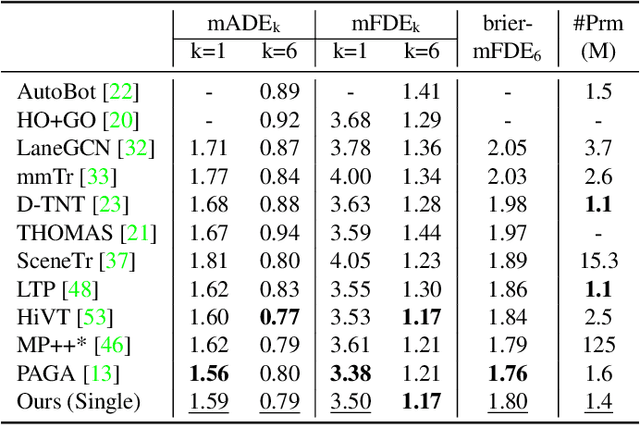

Forecasting future trajectories of agents in complex traffic scenes requires reliable and efficient predictions for all agents in the scene. However, existing methods for trajectory prediction are either inefficient or sacrifice accuracy. To address this challenge, we propose ADAPT, a novel approach for jointly predicting the trajectories of all agents in the scene with dynamic weight learning. Our approach outperforms state-of-the-art methods in both single-agent and multi-agent settings on the Argoverse and Interaction datasets, with a fraction of their computational overhead. We attribute the improvement in our performance: first, to the adaptive head augmenting the model capacity without increasing the model size; second, to our design choices in the endpoint-conditioned prediction, reinforced by gradient stopping. Our analyses show that ADAPT can focus on each agent with adaptive prediction, allowing for accurate predictions efficiently. https://KUIS-AI.github.io/adapt
Stochastic Future Prediction in Real World Driving Scenarios
Sep 27, 2022



Uncertainty plays a key role in future prediction. The future is uncertain. That means there might be many possible futures. A future prediction method should cover the whole possibilities to be robust. In autonomous driving, covering multiple modes in the prediction part is crucially important to make safety-critical decisions. Although computer vision systems have advanced tremendously in recent years, future prediction remains difficult today. Several examples are uncertainty of the future, the requirement of full scene understanding, and the noisy outputs space. In this thesis, we propose solutions to these challenges by modeling the motion explicitly in a stochastic way and learning the temporal dynamics in a latent space.
Trajectory Forecasting on Temporal Graphs
Jul 01, 2022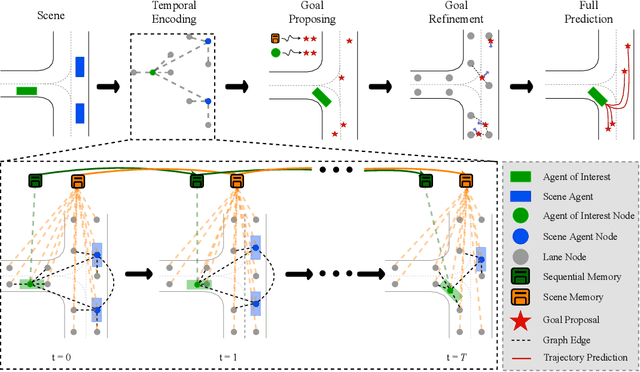
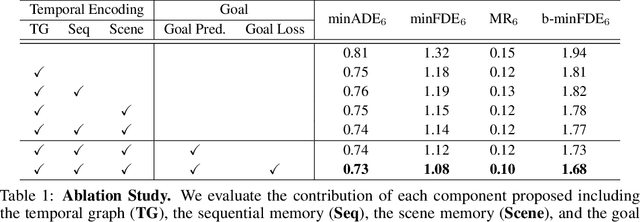
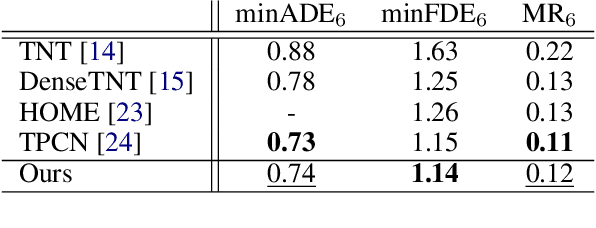
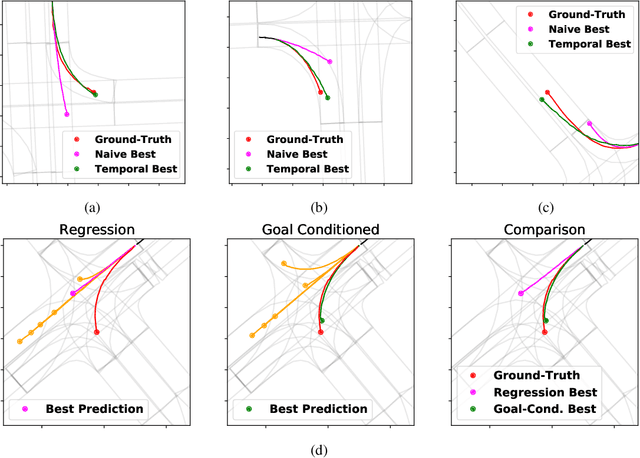
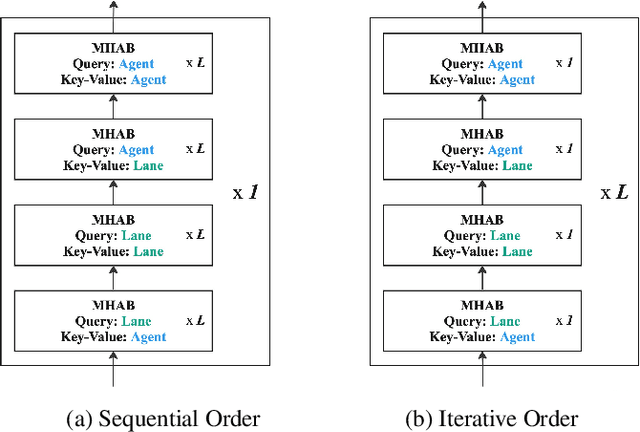
Predicting future locations of agents in the scene is an important problem in self-driving. In recent years, there has been a significant progress in representing the scene and the agents in it. The interactions of agents with the scene and with each other are typically modeled with a Graph Neural Network. However, the graph structure is mostly static and fails to represent the temporal changes in highly dynamic scenes. In this work, we propose a temporal graph representation to better capture the dynamics in traffic scenes. We complement our representation with two types of memory modules; one focusing on the agent of interest and the other on the entire scene. This allows us to learn temporally-aware representations that can achieve good results even with simple regression of multiple futures. When combined with goal-conditioned prediction, we show better results that can reach the state-of-the-art performance on the Argoverse benchmark.
StretchBEV: Stretching Future Instance Prediction Spatially and Temporally
Mar 25, 2022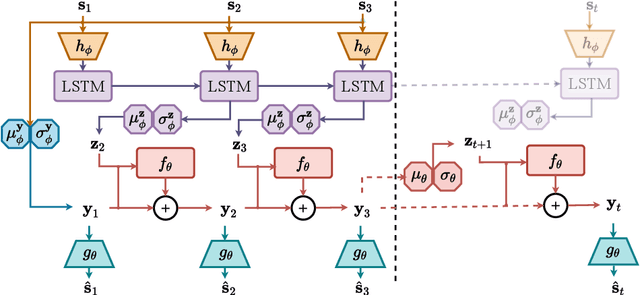
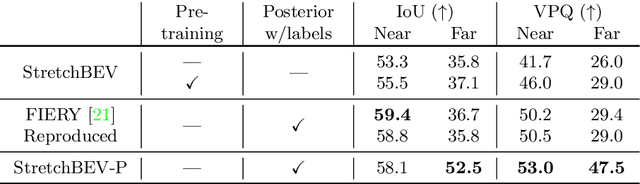
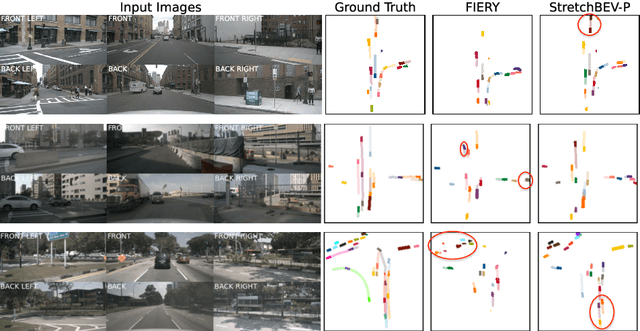

In self-driving, predicting future in terms of location and motion of all the agents around the vehicle is a crucial requirement for planning. Recently, a new joint formulation of perception and prediction has emerged by fusing rich sensory information perceived from multiple cameras into a compact bird's-eye view representation to perform prediction. However, the quality of future predictions degrades over time while extending to longer time horizons due to multiple plausible predictions. In this work, we address this inherent uncertainty in future predictions with a stochastic temporal model. Our model learns temporal dynamics in a latent space through stochastic residual updates at each time step. By sampling from a learned distribution at each time step, we obtain more diverse future predictions that are also more accurate compared to previous work, especially stretching both spatially further regions in the scene and temporally over longer time horizons. Despite separate processing of each time step, our model is still efficient through decoupling of the learning of dynamics and the generation of future predictions.
Stochastic Video Prediction with Structure and Motion
Mar 20, 2022
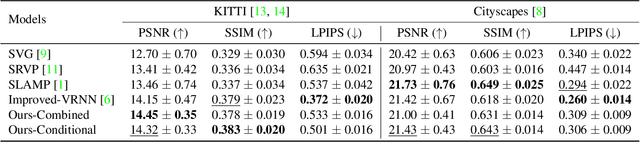
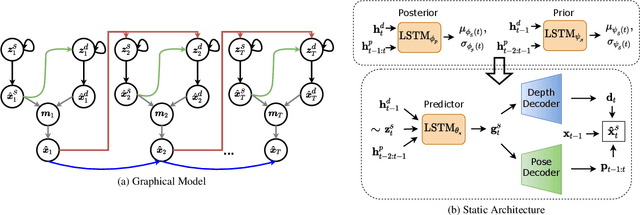
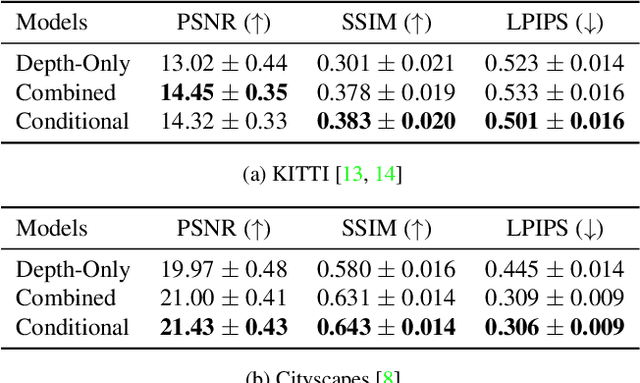
While stochastic video prediction models enable future prediction under uncertainty, they mostly fail to model the complex dynamics of real-world scenes. For example, they cannot provide reliable predictions for scenes with a moving camera and independently moving foreground objects in driving scenarios. The existing methods fail to fully capture the dynamics of the structured world by only focusing on changes in pixels. In this paper, we assume that there is an underlying process creating observations in a video and propose to factorize it into static and dynamic components. We model the static part based on the scene structure and the ego-motion of the vehicle, and the dynamic part based on the remaining motion of the dynamic objects. By learning separate distributions of changes in foreground and background, we can decompose the scene into static and dynamic parts and separately model the change in each. Our experiments demonstrate that disentangling structure and motion helps stochastic video prediction, leading to better future predictions in complex driving scenarios on two real-world driving datasets, KITTI and Cityscapes.
SLAMP: Stochastic Latent Appearance and Motion Prediction
Aug 05, 2021
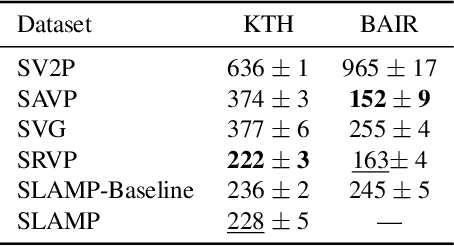
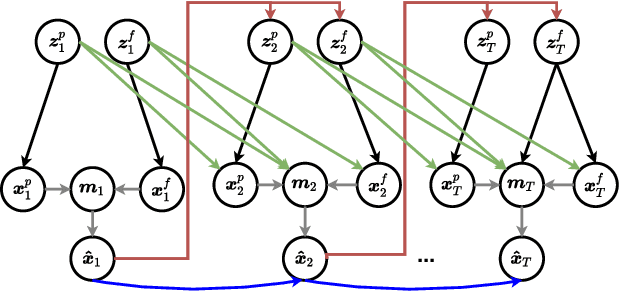
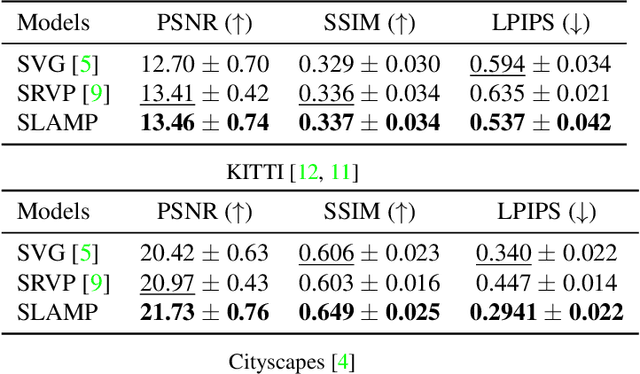
Motion is an important cue for video prediction and often utilized by separating video content into static and dynamic components. Most of the previous work utilizing motion is deterministic but there are stochastic methods that can model the inherent uncertainty of the future. Existing stochastic models either do not reason about motion explicitly or make limiting assumptions about the static part. In this paper, we reason about appearance and motion in the video stochastically by predicting the future based on the motion history. Explicit reasoning about motion without history already reaches the performance of current stochastic models. The motion history further improves the results by allowing to predict consistent dynamics several frames into the future. Our model performs comparably to the state-of-the-art models on the generic video prediction datasets, however, significantly outperforms them on two challenging real-world autonomous driving datasets with complex motion and dynamic background.
Just Noticeable Difference for Machine Perception and Generation of Regularized Adversarial Images with Minimal Perturbation
Feb 16, 2021
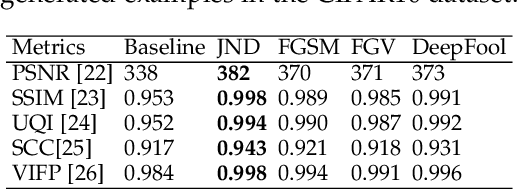


In this study, we introduce a measure for machine perception, inspired by the concept of Just Noticeable Difference (JND) of human perception. Based on this measure, we suggest an adversarial image generation algorithm, which iteratively distorts an image by an additive noise until the machine learning model detects the change in the image by outputting a false label. The amount of noise added to the original image is defined as the gradient of the cost function of the machine learning model. This cost function explicitly minimizes the amount of perturbation applied on the input image and it is regularized by bounded range and total variation functions to assure perceptual similarity of the adversarial image to the input. We evaluate the adversarial images generated by our algorithm both qualitatively and quantitatively on CIFAR10, ImageNet, and MS COCO datasets. Our experiments on image classification and object detection tasks show that adversarial images generated by our method are both more successful in deceiving the recognition/detection model and less perturbed compared to the images generated by the state-of-the-art methods.
Just Noticeable Difference for Machines to Generate Adversarial Images
Jan 29, 2020
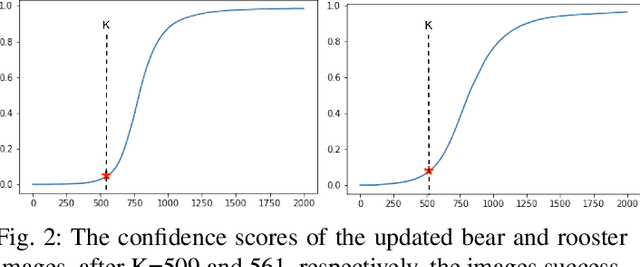


One way of designing a robust machine learning algorithm is to generate authentic adversarial images which can trick the algorithms as much as possible. In this study, we propose a new method to generate adversarial images which are very similar to true images, yet, these images are discriminated from the original ones and are assigned into another category by the model. The proposed method is based on a popular concept of experimental psychology, called, Just Noticeable Difference. We define Just Noticeable Difference for a machine learning model and generate a least perceptible difference for adversarial images which can trick a model. The suggested model iteratively distorts a true image by gradient descent method until the machine learning algorithm outputs a false label. Deep Neural Networks are trained for object detection and classification tasks. The cost function includes regularization terms to generate just noticeably different adversarial images which can be detected by the model. The adversarial images generated in this study looks more natural compared to the output of state of the art adversarial image generators.