 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory Forecasting on Temporal Graphs
Paper and Code
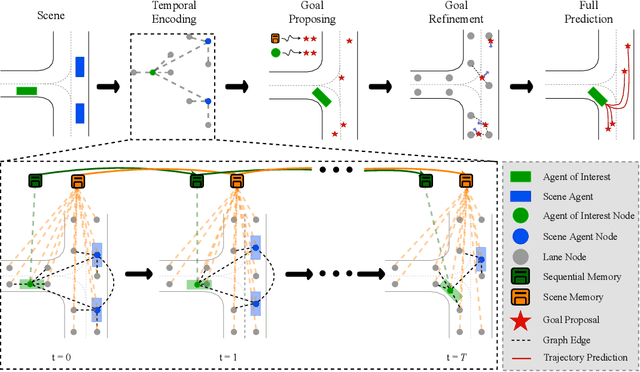
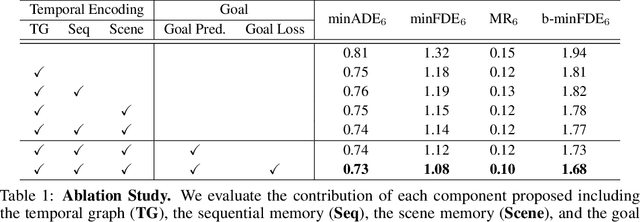
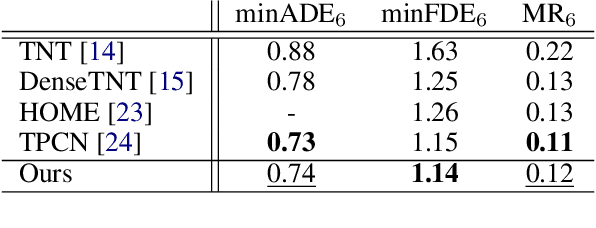
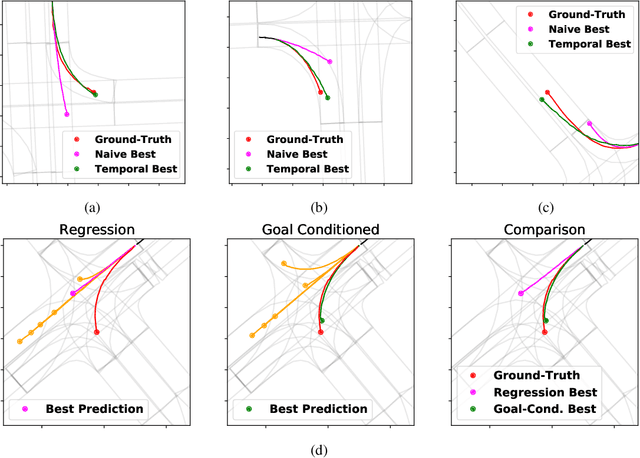
Predicting future locations of agents in the scene is an important problem in self-driving. In recent years, there has been a significant progress in representing the scene and the agents in it. The interactions of agents with the scene and with each other are typically modeled with a Graph Neural Network. However, the graph structure is mostly static and fails to represent the temporal changes in highly dynamic scenes. In this work, we propose a temporal graph representation to better capture the dynamics in traffic scenes. We complement our representation with two types of memory modules; one focusing on the agent of interest and the other on the entire scene. This allows us to learn temporally-aware representations that can achieve good results even with simple regression of multiple futures. When combined with goal-conditioned prediction, we show better results that can reach the state-of-the-art performance on the Argoverse benchmark.