 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Video Synthesis by Temporal Object-Centric Learning
Jul 28, 2025We present a novel framework for compositional video synthesis that leverages temporally consistent object-centric representations, extending our previous work, SlotAdapt, from images to video. While existing object-centric approaches either lack generative capabilities entirely or treat video sequences holistically, thus neglecting explicit object-level structure, our approach explicitly captures temporal dynamics by learning pose invariant object-centric slots and conditioning them on pretrained diffusion models. This design enables high-quality, pixel-level video synthesis with superior temporal coherence, and offers intuitive compositional editing capabilities such as object insertion, deletion, or replacement, maintaining consistent object identities across frames. Extensive experiments demonstrate that our method sets new benchmarks in video generation quality and temporal consistency, outperforming previous object-centric generative methods. Although our segmentation performance closely matches state-of-the-art methods, our approach uniquely integrates this capability with robust generative performance, significantly advancing interactive and controllable video generation and opening new possibilities for advanced content creation, semantic editing, and dynamic scene understanding.
Slot-Guided Adaptation of Pre-trained Diffusion Models for Object-Centric Learning and Compositional Generation
Jan 27, 2025We present SlotAdapt, an object-centric learning method that combines slot attention with pretrained diffusion models by introducing adapters for slot-based conditioning. Our method preserves the generative power of pretrained diffusion models, while avoiding their text-centric conditioning bias. We also incorporate an additional guidance loss into our architecture to align cross-attention from adapter layers with slot attention. This enhances the alignment of our model with the objects in the input image without using external supervision. Experimental results show that our method outperforms state-of-the-art techniques in object discovery and image generation tasks across multiple datasets, including those with real images. Furthermore, we demonstrate through experiments that our method performs remarkably well on complex real-world images for compositional generation, in contrast to other slot-based generative methods in the literature. The project page can be found at $\href{https://kaanakan.github.io/SlotAdapt/}{\text{this https url}}$.
AffectON: Incorporating Affect Into Dialog Generation
Dec 12, 2020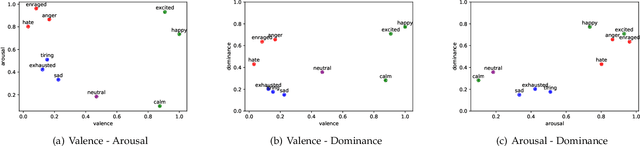
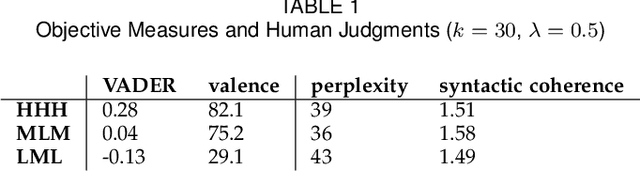


Due to its expressivity, natural language is paramount for explicit and implicit affective state communication among humans. The same linguistic inquiry (e.g., How are you?) might induce responses with different affects depending on the affective state of the conversational partner(s) and the context of the conversation. Yet, most dialog systems do not consider affect as constitutive aspect of response generation. In this paper, we introduce AffectON, an approach for generating affective responses during inference. For generating language in a targeted affect, our approach leverages a probabilistic language model and an affective space. AffectON is language model agnostic, since it can work with probabilities generated by any language model (e.g., sequence-to-sequence models, neural language models, n-grams). Hence, it can be employed for both affective dialog and affective language generation. We experimented with affective dialog generation and evaluated the generated text objectively and subjectively. For the subjective part of the evaluation, we designed a custom user interface for rating and provided recommendations for the design of such interfaces. The results, both subjective and objective demonstrate that our approach is successful in pulling the generated language toward the targeted affect, with little sacrifice in syntactic coherence.
Batch Recurrent Q-Learning for Backchannel Generation Towards Engaging Agents
Aug 06, 2019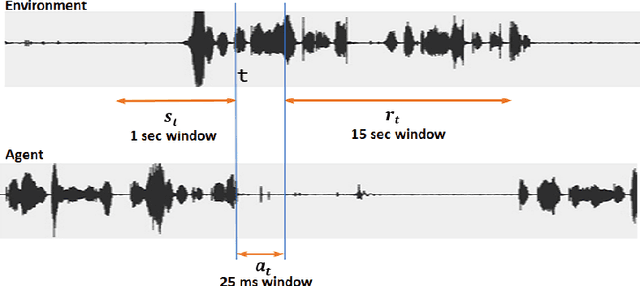
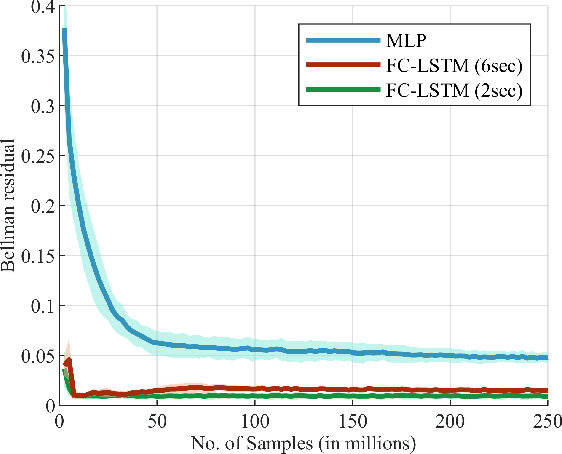
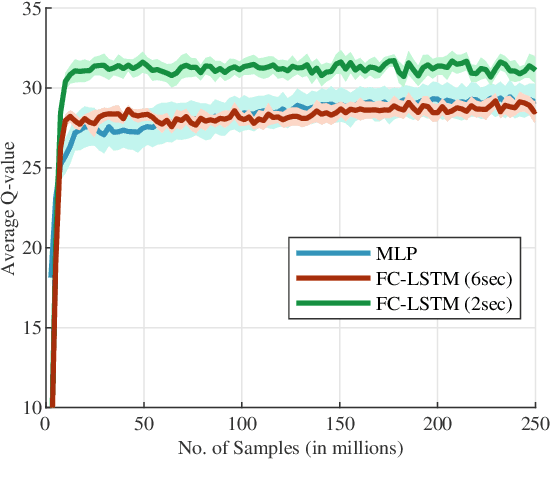
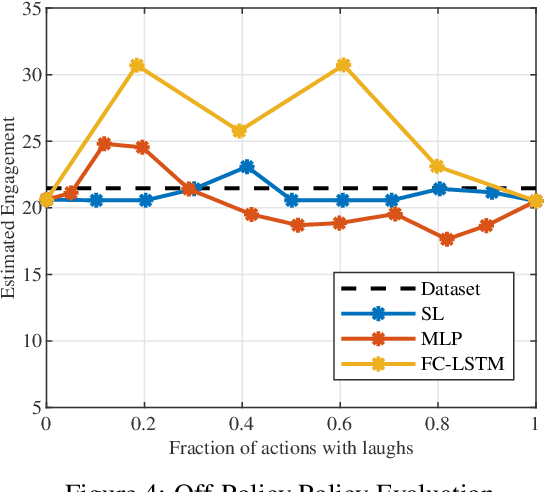
The ability to generate appropriate verbal and non-verbal backchannels by an agent during human-robot interaction greatly enhances the interaction experience. Backchannels are particularly important in applications like tutoring and counseling, which require constant attention and engagement of the user. We present here a method for training a robot for backchannel generation during a human-robot interaction within the reinforcement learning (RL) framework, with the goal of maintaining high engagement level. Since online learning by interaction with a human is highly time-consuming and impractical, we take advantage of the recorded human-to-human dataset and approach our problem as a batch reinforcement learning problem. The dataset is utilized as a batch data acquired by some behavior policy. We perform experiments with laughs as a backchannel and train an agent with value-based techniques. In particular, we demonstrate the effectiveness of recurrent layers in the approximate value function for this problem, that boosts the performance in partially observable environments. With off-policy policy evaluation, it is shown that the RL agents are expected to produce more engagement than an agent trained from imitation learning.
Speech Driven Backchannel Generation using Deep Q-Network for Enhancing Engagement in Human-Robot Interaction
Aug 05, 2019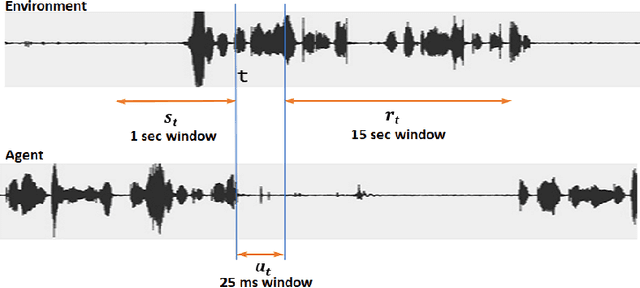
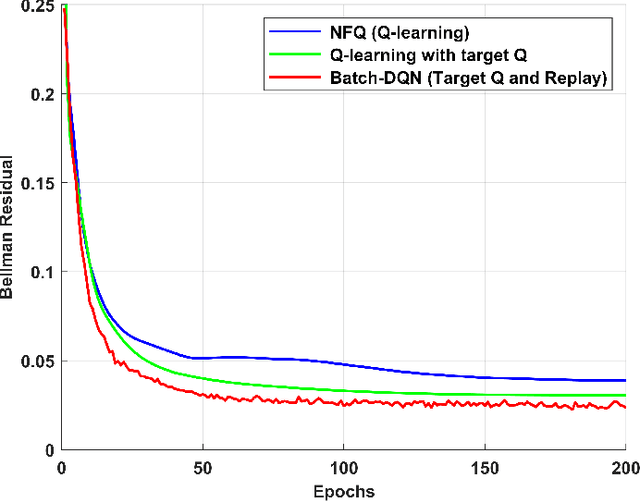

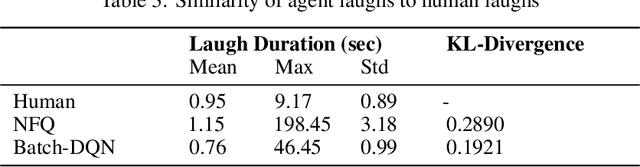
We present a novel method for training a social robot to generate backchannels during human-robot interaction. We address the problem within an off-policy reinforcement learning framework, and show how a robot may learn to produce non-verbal backchannels like laughs, when trained to maximize the engagement and attention of the user. A major contribution of this work is the formulation of the problem as a Markov decision process (MDP) with states defined by the speech activity of the user and rewards generated by quantified engagement levels. The problem that we address falls into the class of applications where unlimited interaction with the environment is not possible (our environment being a human) because it may be time-consuming, costly, impracticable or even dangerous in case a bad policy is executed. Therefore, we introduce deep Q-network (DQN) in a batch reinforcement learning framework, where an optimal policy is learned from a batch data collected using a more controlled policy. We suggest the use of human-to-human dyadic interaction datasets as a batch of trajectories to train an agent for engaging interactions. Our experiments demonstrate the potential of our method to train a robot for engaging behaviors in an offline manner.