 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAISTA-NET: Human Assisted Instance Segmentation Through Attention
May 12, 2023Instance segmentation is a form of image detection which has a range of applications, such as object refinement, medical image analysis, and image/video editing, all of which demand a high degree of accuracy. However, this precision is often beyond the reach of what even state-of-the-art, fully automated instance segmentation algorithms can deliver. The performance gap becomes particularly prohibitive for small and complex objects. Practitioners typically resort to fully manual annotation, which can be a laborious process. In order to overcome this problem, we propose a novel approach to enable more precise predictions and generate higher-quality segmentation masks for high-curvature, complex and small-scale objects. Our human-assisted segmentation model, HAISTA-NET, augments the existing Strong Mask R-CNN network to incorporate human-specified partial boundaries. We also present a dataset of hand-drawn partial object boundaries, which we refer to as human attention maps. In addition, the Partial Sketch Object Boundaries (PSOB) dataset contains hand-drawn partial object boundaries which represent curvatures of an object's ground truth mask with several pixels. Through extensive evaluation using the PSOB dataset, we show that HAISTA-NET outperforms state-of-the art methods such as Mask R-CNN, Strong Mask R-CNN, and Mask2Former, achieving respective increases of +36.7, +29.6, and +26.5 points in AP-Mask metrics for these three models. We hope that our novel approach will set a baseline for future human-aided deep learning models by combining fully automated and interactive instance segmentation architectures.
Perceptually Validated Precise Local Editing for Facial Action Units with StyleGAN
Jul 27, 2021



The ability to edit facial expressions has a wide range of applications in computer graphics. The ideal facial expression editing algorithm needs to satisfy two important criteria. First, it should allow precise and targeted editing of individual facial actions. Second, it should generate high fidelity outputs without artifacts. We build a solution based on StyleGAN, which has been used extensively for semantic manipulation of faces. As we do so, we add to our understanding of how various semantic attributes are encoded in StyleGAN. In particular, we show that a naive strategy to perform editing in the latent space results in undesired coupling between certain action units, even if they are conceptually distinct. For example, although brow lowerer and lip tightener are distinct action units, they appear correlated in the training data. Hence, StyleGAN has difficulty in disentangling them. We allow disentangled editing of such action units by computing detached regions of influence for each action unit, and restrict editing to these regions. We validate the effectiveness of our local editing method through perception experiments conducted with 23 subjects. The results show that our method provides higher control over local editing and produces images with superior fidelity compared to the state-of-the-art methods.
On Training Sketch Recognizers for New Domains
Apr 18, 2021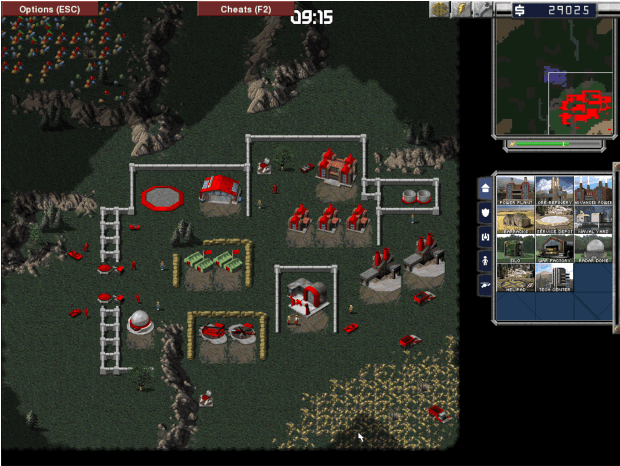
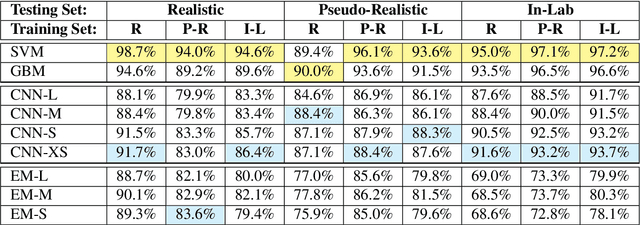
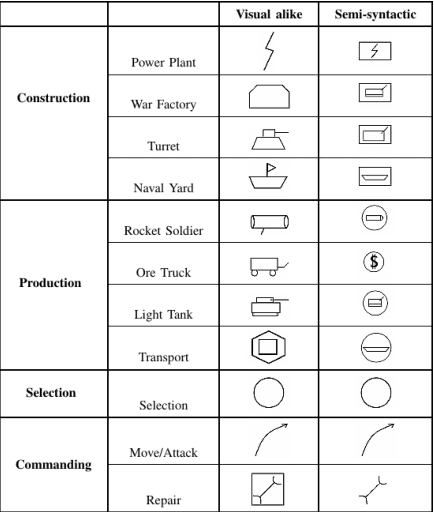
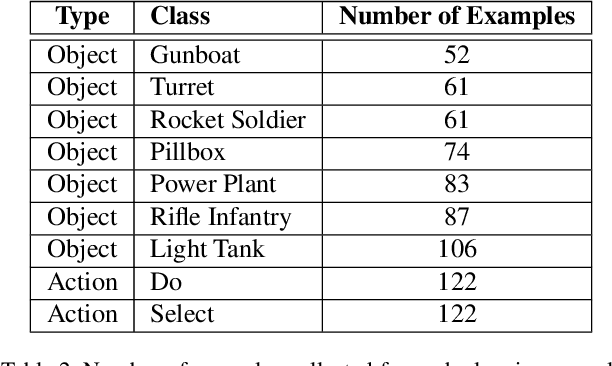
Sketch recognition algorithms are engineered and evaluated using publicly available datasets contributed by the sketch recognition community over the years. While existing datasets contain sketches of a limited set of generic objects, each new domain inevitably requires collecting new data for training domain specific recognizers. This gives rise to two fundamental concerns: First, will the data collection protocol yield ecologically valid data? Second, will the amount of collected data suffice to train sufficiently accurate classifiers? In this paper, we draw attention to these two concerns. We show that the ecological validity of the data collection protocol and the ability to accommodate small datasets are significant factors impacting recognizer accuracy in realistic scenarios. More specifically, using sketch-based gaming as a use case, we show that deep learning methods, as well as more traditional methods, suffer significantly from dataset shift. Furthermore, we demonstrate that in realistic scenarios where data is scarce and expensive, standard measures taken for adapting deep learners to small datasets fall short of comparing favorably with alternatives. Although transfer learning, and extensive data augmentation help deep learners, they still perform significantly worse compared to standard setups (e.g., SVMs and GBMs with standard feature representations). We pose learning from small datasets as a key problem for the deep sketch recognition field, one which has been ignored in the bulk of the existing literature.
HaptiStylus: A Novel Stylus Capable of Displaying Movement and Rotational Torque Effects
Apr 02, 2021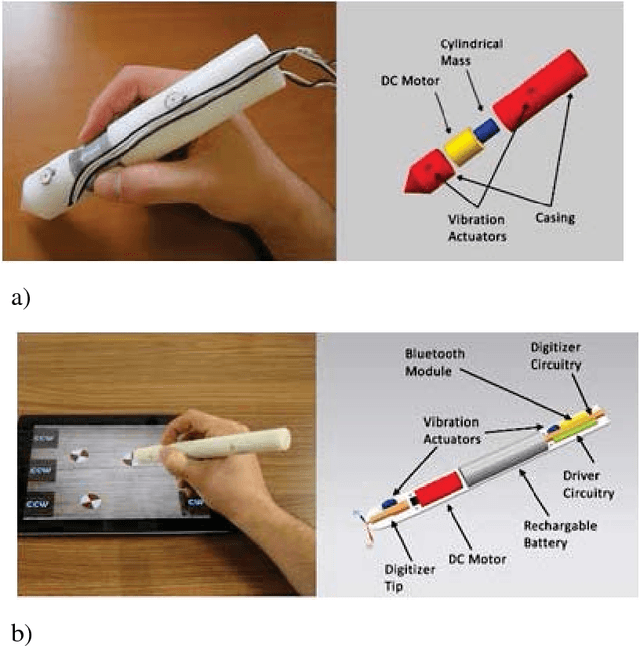

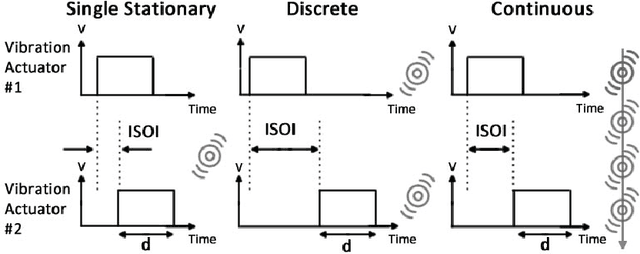
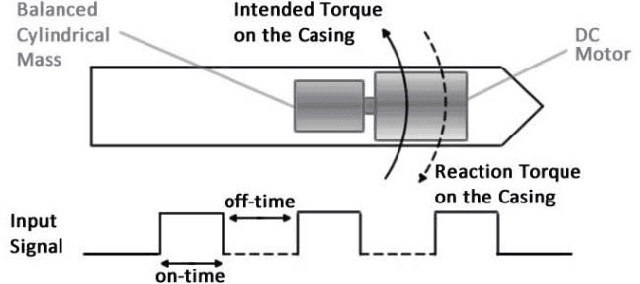
With the emergence of pen-enabled tablets and mobile devices, stylus-based interaction has been receiving increasing attention. Unfortunately, styluses available in the market today are all passive instruments that are primarily used for writing and pointing. In this paper, we describe a novel stylus capable of displaying certain vibro-tactile and inertial haptic effects to the user. Our stylus is equipped with two vibration actuators at the ends, which are used to create a tactile sensation of up and down movement along the stylus. The stylus is also embedded with a DC motor, which is used to create a sense of bidirectional rotational torque about the long axis of the pen. Through two psychophysical experiments, we show that, when driven with carefully selected timing and actuation patterns, our haptic stylus can convey movement and rotational torque information to the user. Results from a further psychophysical experiment provide insight on how the shape of the actuation patterns effects the perception of rotational torque effect. Finally, experimental results from our interactive pen-based game show that our haptic stylus is effective in practical settings
HapTable: An Interactive Tabletop Providing Online Haptic Feedback for Touch Gestures
Mar 30, 2021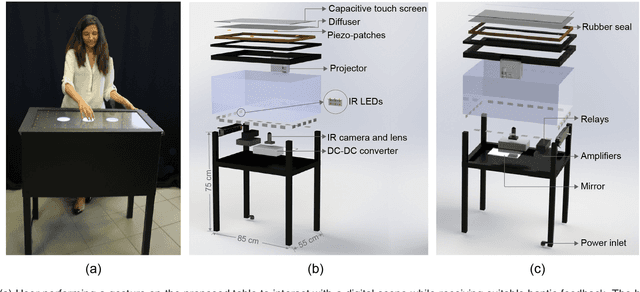
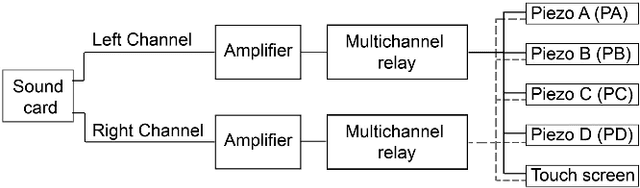

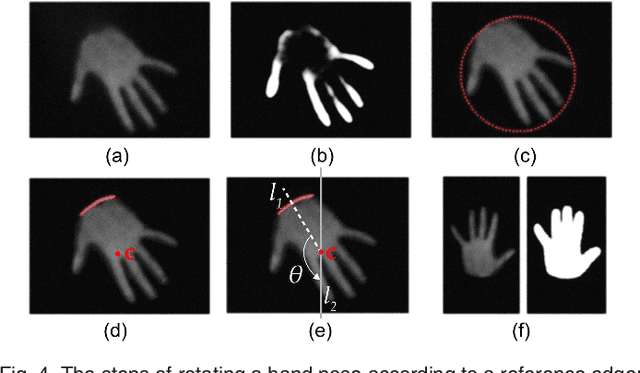
We present HapTable; a multimodal interactive tabletop that allows users to interact with digital images and objects through natural touch gestures, and receive visual and haptic feedback accordingly. In our system, hand pose is registered by an infrared camera and hand gestures are classified using a Support Vector Machine (SVM) classifier. To display a rich set of haptic effects for both static and dynamic gestures, we integrated electromechanical and electrostatic actuation techniques effectively on tabletop surface of HapTable, which is a surface capacitive touch screen. We attached four piezo patches to the edges of tabletop to display vibrotactile feedback for static gestures. For this purpose, the vibration response of the tabletop, in the form of frequency response functions (FRFs), was obtained by a laser Doppler vibrometer for 84 grid points on its surface. Using these FRFs, it is possible to display localized vibrotactile feedback on the surface for static gestures. For dynamic gestures, we utilize the electrostatic actuation technique to modulate the frictional forces between finger skin and tabletop surface by applying voltage to its conductive layer. Here, we present two examples of such applications, one for static and one for dynamic gestures, along with detailed user studies. In the first one, user detects the direction of a virtual flow, such as that of wind or water, by putting their hand on the tabletop surface and feeling a vibrotactile stimulus traveling underneath it. In the second example, user rotates a virtual knob on the tabletop surface to select an item from a menu while feeling the knob's detents and resistance to rotation in the form of frictional haptic feedback.
Batch Recurrent Q-Learning for Backchannel Generation Towards Engaging Agents
Aug 06, 2019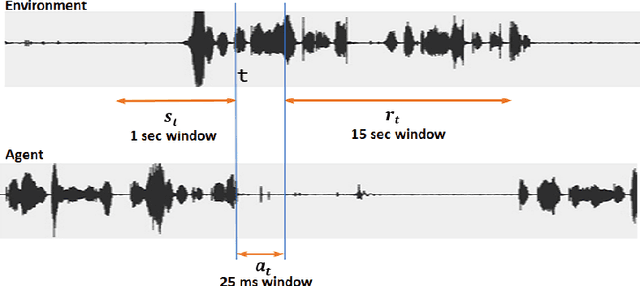
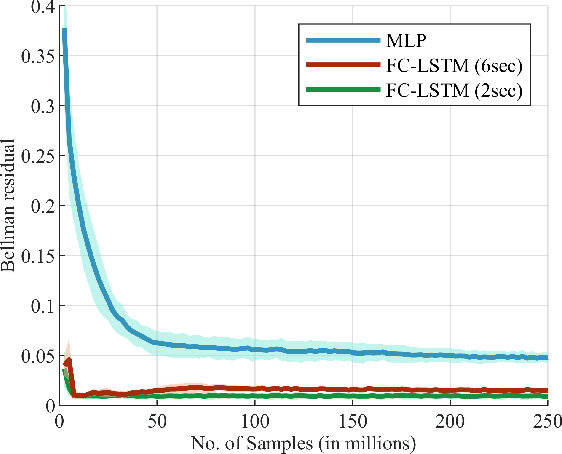
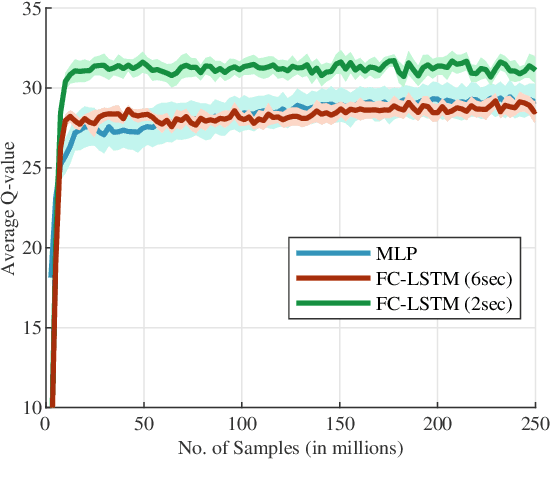
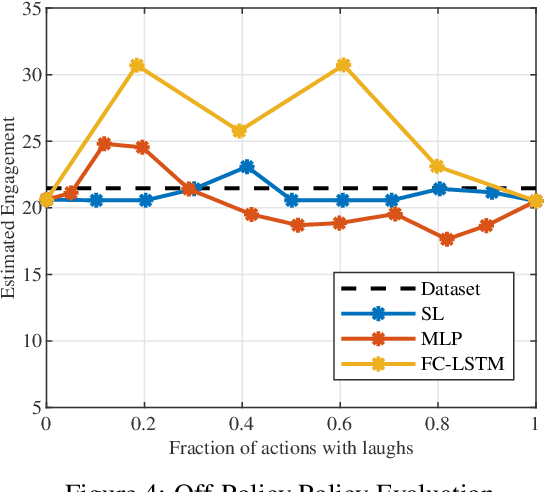
The ability to generate appropriate verbal and non-verbal backchannels by an agent during human-robot interaction greatly enhances the interaction experience. Backchannels are particularly important in applications like tutoring and counseling, which require constant attention and engagement of the user. We present here a method for training a robot for backchannel generation during a human-robot interaction within the reinforcement learning (RL) framework, with the goal of maintaining high engagement level. Since online learning by interaction with a human is highly time-consuming and impractical, we take advantage of the recorded human-to-human dataset and approach our problem as a batch reinforcement learning problem. The dataset is utilized as a batch data acquired by some behavior policy. We perform experiments with laughs as a backchannel and train an agent with value-based techniques. In particular, we demonstrate the effectiveness of recurrent layers in the approximate value function for this problem, that boosts the performance in partially observable environments. With off-policy policy evaluation, it is shown that the RL agents are expected to produce more engagement than an agent trained from imitation learning.
Speech Driven Backchannel Generation using Deep Q-Network for Enhancing Engagement in Human-Robot Interaction
Aug 05, 2019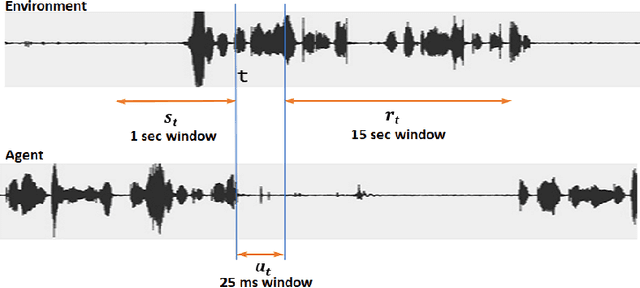
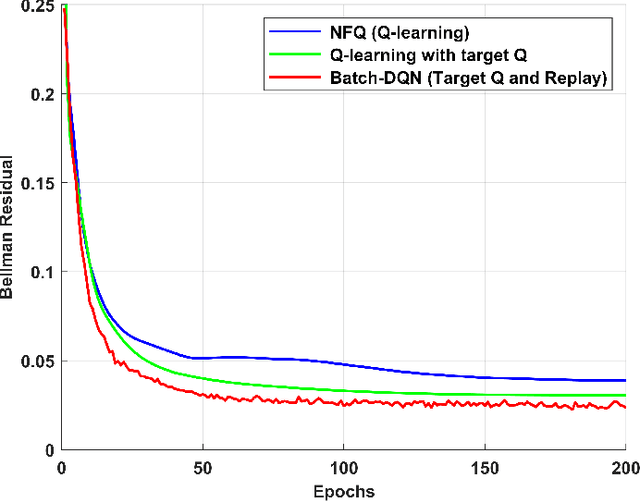

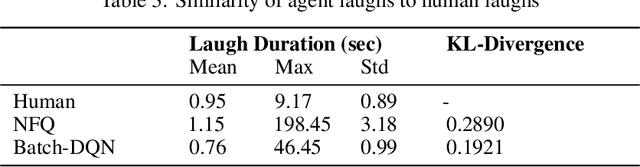
We present a novel method for training a social robot to generate backchannels during human-robot interaction. We address the problem within an off-policy reinforcement learning framework, and show how a robot may learn to produce non-verbal backchannels like laughs, when trained to maximize the engagement and attention of the user. A major contribution of this work is the formulation of the problem as a Markov decision process (MDP) with states defined by the speech activity of the user and rewards generated by quantified engagement levels. The problem that we address falls into the class of applications where unlimited interaction with the environment is not possible (our environment being a human) because it may be time-consuming, costly, impracticable or even dangerous in case a bad policy is executed. Therefore, we introduce deep Q-network (DQN) in a batch reinforcement learning framework, where an optimal policy is learned from a batch data collected using a more controlled policy. We suggest the use of human-to-human dyadic interaction datasets as a batch of trajectories to train an agent for engaging interactions. Our experiments demonstrate the potential of our method to train a robot for engaging behaviors in an offline manner.