 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Training Sketch Recognizers for New Domains
Apr 18, 2021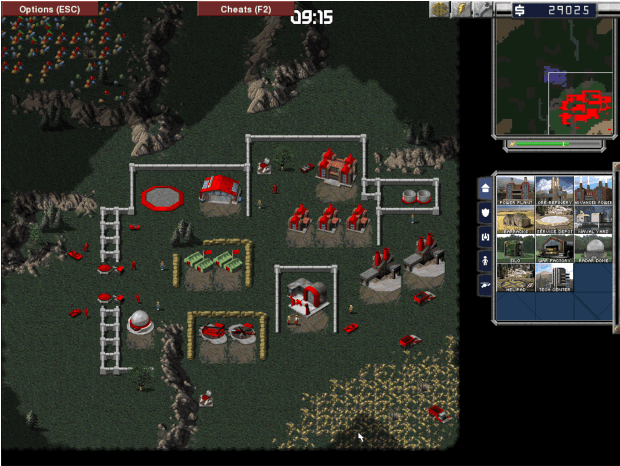
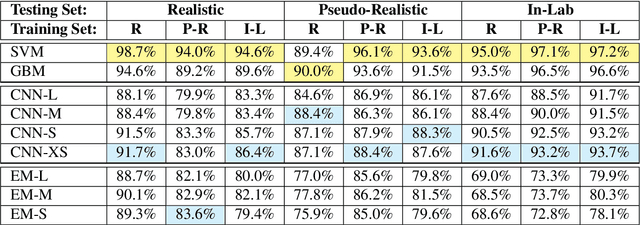
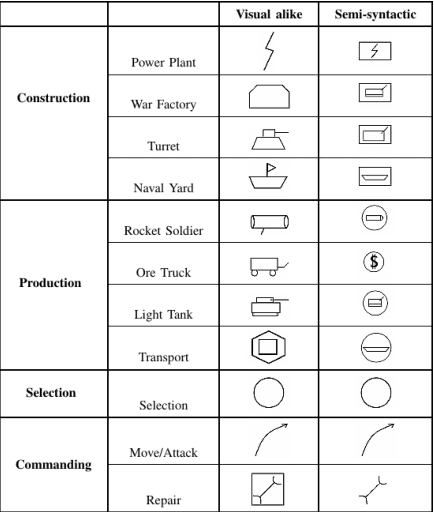
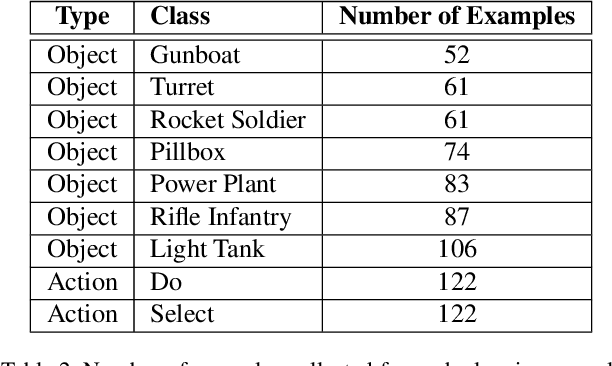
Sketch recognition algorithms are engineered and evaluated using publicly available datasets contributed by the sketch recognition community over the years. While existing datasets contain sketches of a limited set of generic objects, each new domain inevitably requires collecting new data for training domain specific recognizers. This gives rise to two fundamental concerns: First, will the data collection protocol yield ecologically valid data? Second, will the amount of collected data suffice to train sufficiently accurate classifiers? In this paper, we draw attention to these two concerns. We show that the ecological validity of the data collection protocol and the ability to accommodate small datasets are significant factors impacting recognizer accuracy in realistic scenarios. More specifically, using sketch-based gaming as a use case, we show that deep learning methods, as well as more traditional methods, suffer significantly from dataset shift. Furthermore, we demonstrate that in realistic scenarios where data is scarce and expensive, standard measures taken for adapting deep learners to small datasets fall short of comparing favorably with alternatives. Although transfer learning, and extensive data augmentation help deep learners, they still perform significantly worse compared to standard setups (e.g., SVMs and GBMs with standard feature representations). We pose learning from small datasets as a key problem for the deep sketch recognition field, one which has been ignored in the bulk of the existing literature.