 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Video Prediction with Structure and Motion
Paper and Code
Mar 20, 2022
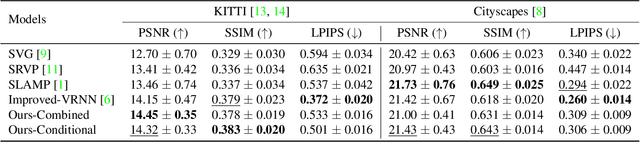
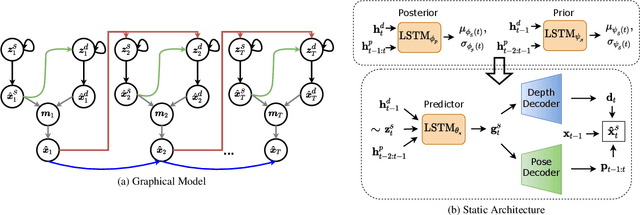
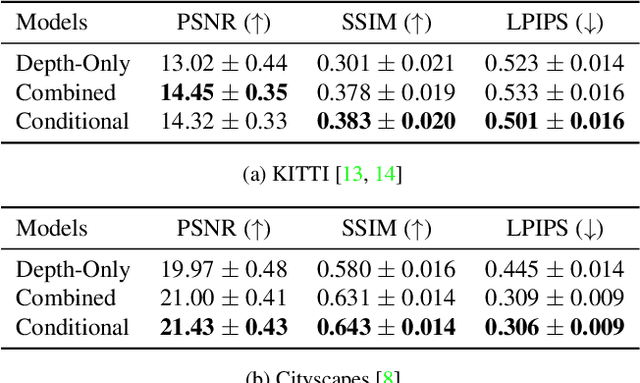
While stochastic video prediction models enable future prediction under uncertainty, they mostly fail to model the complex dynamics of real-world scenes. For example, they cannot provide reliable predictions for scenes with a moving camera and independently moving foreground objects in driving scenarios. The existing methods fail to fully capture the dynamics of the structured world by only focusing on changes in pixels. In this paper, we assume that there is an underlying process creating observations in a video and propose to factorize it into static and dynamic components. We model the static part based on the scene structure and the ego-motion of the vehicle, and the dynamic part based on the remaining motion of the dynamic objects. By learning separate distributions of changes in foreground and background, we can decompose the scene into static and dynamic parts and separately model the change in each. Our experiments demonstrate that disentangling structure and motion helps stochastic video prediction, leading to better future predictions in complex driving scenarios on two real-world driving datasets, KITTI and Cityscapes.