 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Visual Foundation Models Achieve Long-term Point Tracking?
Paper and Code
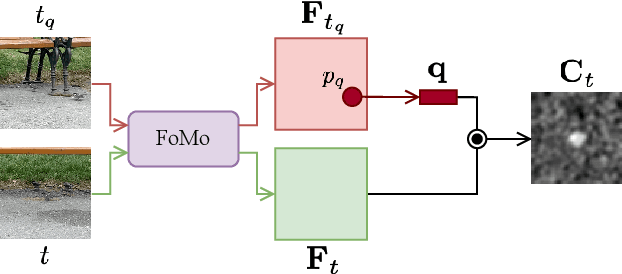
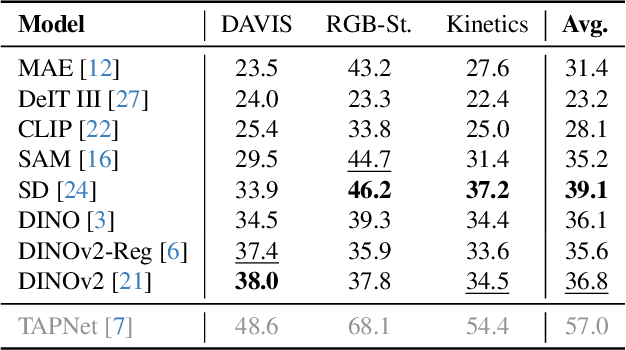
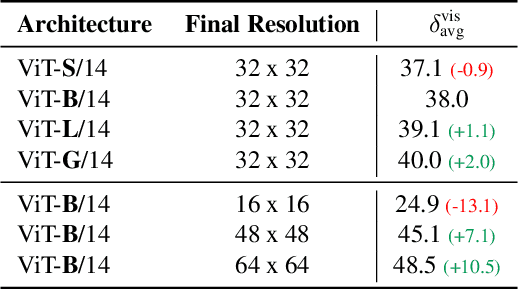
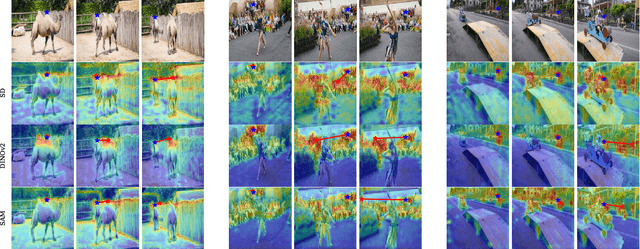
Large-scale vision foundation models have demonstrated remarkable success across various tasks, underscoring their robust generalization capabilities. While their proficiency in two-view correspondence has been explored, their effectiveness in long-term correspondence within complex environments remains unexplored. To address this, we evaluate the geometric awareness of visual foundation models in the context of point tracking: (i) in zero-shot settings, without any training; (ii) by probing with low-capacity layers; (iii) by fine-tuning with Low Rank Adaptation (LoRA). Our findings indicate that features from Stable Diffusion and DINOv2 exhibit superior geometric correspondence abilities in zero-shot settings. Furthermore, DINOv2 achieves performance comparable to supervised models in adaptation settings, demonstrating its potential as a strong initialization for correspondence learning.