 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETA: Efficiency through Thinking Ahead, A Dual Approach to Self-Driving with Large Models
Jun 09, 2025How can we benefit from large models without sacrificing inference speed, a common dilemma in self-driving systems? A prevalent solution is a dual-system architecture, employing a small model for rapid, reactive decisions and a larger model for slower but more informative analyses. Existing dual-system designs often implement parallel architectures where inference is either directly conducted using the large model at each current frame or retrieved from previously stored inference results. However, these works still struggle to enable large models for a timely response to every online frame. Our key insight is to shift intensive computations of the current frame to previous time steps and perform a batch inference of multiple time steps to make large models respond promptly to each time step. To achieve the shifting, we introduce Efficiency through Thinking Ahead (ETA), an asynchronous system designed to: (1) propagate informative features from the past to the current frame using future predictions from the large model, (2) extract current frame features using a small model for real-time responsiveness, and (3) integrate these dual features via an action mask mechanism that emphasizes action-critical image regions. Evaluated on the Bench2Drive CARLA Leaderboard-v2 benchmark, ETA advances state-of-the-art performance by 8% with a driving score of 69.53 while maintaining a near-real-time inference speed at 50 ms.
How much do LLMs learn from negative examples?
Mar 18, 2025

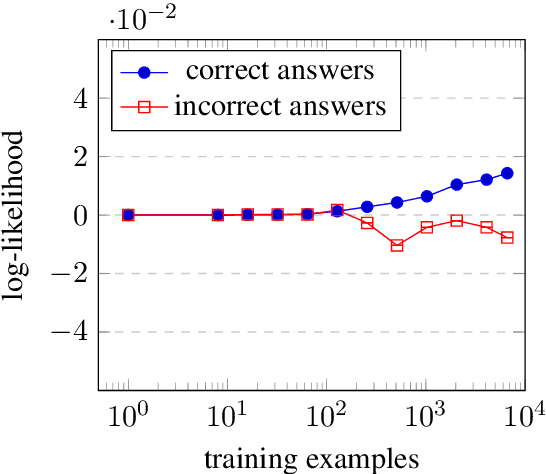

Large language models (LLMs) undergo a three-phase training process: unsupervised pre-training, supervised fine-tuning (SFT), and learning from human feedback (RLHF/DPO). Notably, it is during the final phase that these models are exposed to negative examples -- incorrect, rejected, or suboptimal responses to queries. This paper delves into the role of negative examples in the training of LLMs, using a likelihood-ratio (Likra) model on multiple-choice question answering benchmarks to precisely manage the influence and the volume of negative examples. Our findings reveal three key insights: (1) During a critical phase in training, Likra with negative examples demonstrates a significantly larger improvement per training example compared to SFT using only positive examples. This leads to a sharp jump in the learning curve for Likra unlike the smooth and gradual improvement of SFT; (2) negative examples that are plausible but incorrect (near-misses) exert a greater influence; and (3) while training with positive examples fails to significantly decrease the likelihood of plausible but incorrect answers, training with negative examples more accurately identifies them. These results indicate a potentially significant role for negative examples in improving accuracy and reducing hallucinations for LLMs.
CarFormer: Self-Driving with Learned Object-Centric Representations
Jul 22, 2024



The choice of representation plays a key role in self-driving. Bird's eye view (BEV) representations have shown remarkable performance in recent years. In this paper, we propose to learn object-centric representations in BEV to distill a complex scene into more actionable information for self-driving. We first learn to place objects into slots with a slot attention model on BEV sequences. Based on these object-centric representations, we then train a transformer to learn to drive as well as reason about the future of other vehicles. We found that object-centric slot representations outperform both scene-level and object-level approaches that use the exact attributes of objects. Slot representations naturally incorporate information about objects from their spatial and temporal context such as position, heading, and speed without explicitly providing it. Our model with slots achieves an increased completion rate of the provided routes and, consequently, a higher driving score, with a lower variance across multiple runs, affirming slots as a reliable alternative in object-centric approaches. Additionally, we validate our model's performance as a world model through forecasting experiments, demonstrating its capability to predict future slot representations accurately. The code and the pre-trained models can be found at https://kuis-ai.github.io/CarFormer/.
Self-Supervised Learning with an Information Maximization Criterion
Sep 16, 2022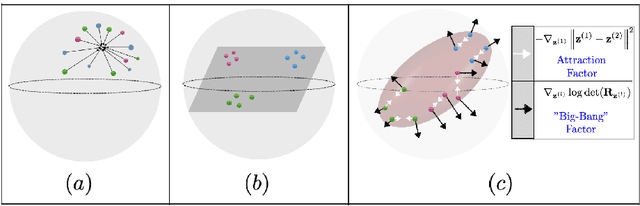
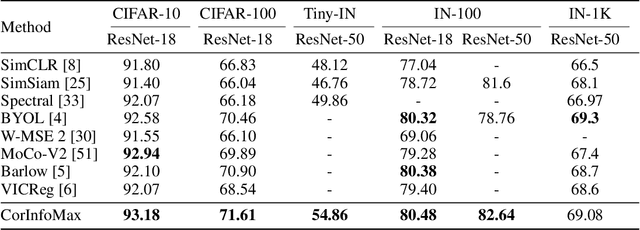
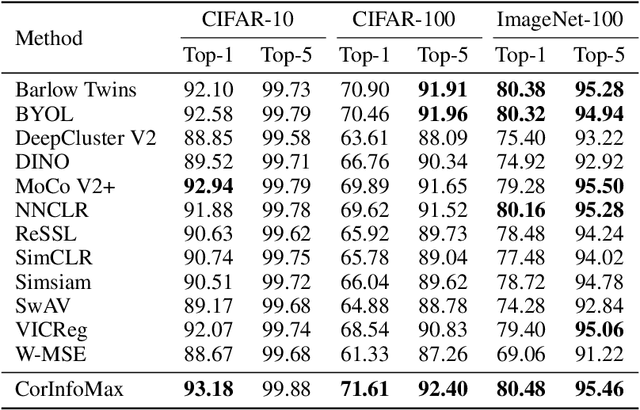
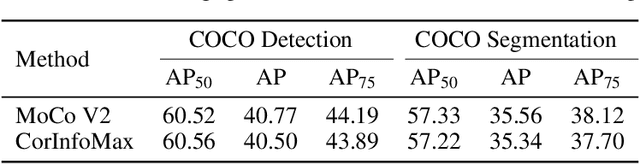
Self-supervised learning allows AI systems to learn effective representations from large amounts of data using tasks that do not require costly labeling. Mode collapse, i.e., the model producing identical representations for all inputs, is a central problem to many self-supervised learning approaches, making self-supervised tasks, such as matching distorted variants of the inputs, ineffective. In this article, we argue that a straightforward application of information maximization among alternative latent representations of the same input naturally solves the collapse problem and achieves competitive empirical results. We propose a self-supervised learning method, CorInfoMax, that uses a second-order statistics-based mutual information measure that reflects the level of correlation among its arguments. Maximizing this correlative information measure between alternative representations of the same input serves two purposes: (1) it avoids the collapse problem by generating feature vectors with non-degenerate covariances; (2) it establishes relevance among alternative representations by increasing the linear dependence among them. An approximation of the proposed information maximization objective simplifies to a Euclidean distance-based objective function regularized by the log-determinant of the feature covariance matrix. The regularization term acts as a natural barrier against feature space degeneracy. Consequently, beyond avoiding complete output collapse to a single point, the proposed approach also prevents dimensional collapse by encouraging the spread of information across the whole feature space. Numerical experiments demonstrate that CorInfoMax achieves better or competitive performance results relative to the state-of-the-art SSL approaches.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.