 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow much do LLMs learn from negative examples?
Paper and Code


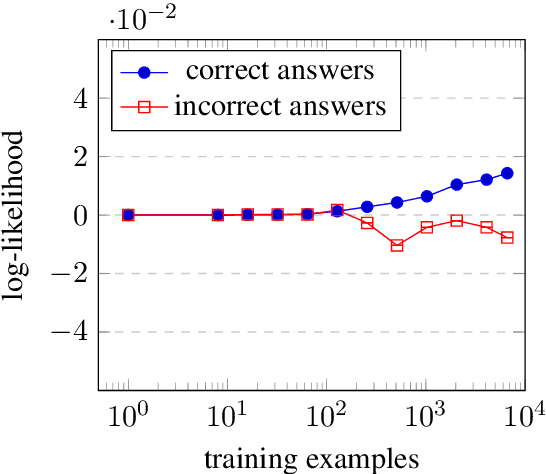

Large language models (LLMs) undergo a three-phase training process: unsupervised pre-training, supervised fine-tuning (SFT), and learning from human feedback (RLHF/DPO). Notably, it is during the final phase that these models are exposed to negative examples -- incorrect, rejected, or suboptimal responses to queries. This paper delves into the role of negative examples in the training of LLMs, using a likelihood-ratio (Likra) model on multiple-choice question answering benchmarks to precisely manage the influence and the volume of negative examples. Our findings reveal three key insights: (1) During a critical phase in training, Likra with negative examples demonstrates a significantly larger improvement per training example compared to SFT using only positive examples. This leads to a sharp jump in the learning curve for Likra unlike the smooth and gradual improvement of SFT; (2) negative examples that are plausible but incorrect (near-misses) exert a greater influence; and (3) while training with positive examples fails to significantly decrease the likelihood of plausible but incorrect answers, training with negative examples more accurately identifies them. These results indicate a potentially significant role for negative examples in improving accuracy and reducing hallucinations for LLMs.