 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of Agents: Large Language Models Collaborating on Long-Context Tasks
Jun 04, 2024



Addressing the challenge of effectively processing long contexts has become a critical issue for Large Language Models (LLMs). Two common strategies have emerged: 1) reducing the input length, such as retrieving relevant chunks by Retrieval-Augmented Generation (RAG), and 2) expanding the context window limit of LLMs. However, both strategies have drawbacks: input reduction has no guarantee of covering the part with needed information, while window extension struggles with focusing on the pertinent information for solving the task. To mitigate these limitations, we propose Chain-of-Agents (CoA), a novel framework that harnesses multi-agent collaboration through natural language to enable information aggregation and context reasoning across various LLMs over long-context tasks. CoA consists of multiple worker agents who sequentially communicate to handle different segmented portions of the text, followed by a manager agent who synthesizes these contributions into a coherent final output. CoA processes the entire input by interleaving reading and reasoning, and it mitigates long context focus issues by assigning each agent a short context. We perform comprehensive evaluation of CoA on a wide range of long-context tasks in question answering, summarization, and code completion, demonstrating significant improvements by up to 10% over strong baselines of RAG, Full-Context, and multi-agent LLMs.
Effective Large Language Model Adaptation for Improved Grounding
Nov 16, 2023



Large language models (LLMs) have achieved remarkable advancements in natural language understanding, generation, and manipulation of text-based data. However, one major issue towards their widespread deployment in the real world is that they can generate "hallucinated" answers that are not factual. Towards this end, this paper focuses on improving grounding from a holistic perspective with a novel framework, AGREE, Adaptation of LLMs for GRounding EnhancEment. We start with the design of an iterative test-time adaptation (TTA) capability that takes into account the support information generated in self-grounded responses. To effectively enable this capability, we tune LLMs to ground the claims in their responses to retrieved documents by providing citations. This tuning on top of the pre-trained LLMs requires a small amount of data that needs to be constructed in a particular way to learn the grounding information, for which we introduce a data construction method. Our results show that the tuning-based AGREE framework generates better grounded responses with more accurate citations compared to prompting-based approaches.
SQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data
Nov 06, 2023



Text-to-SQL aims to automate the process of generating SQL queries on a database from natural language text. In this work, we propose "SQLPrompt", tailored to improve the few-shot prompting capabilities of Text-to-SQL for Large Language Models (LLMs). Our methods include innovative prompt design, execution-based consistency decoding strategy which selects the SQL with the most consistent execution outcome among other SQL proposals, and a method that aims to improve performance by diversifying the SQL proposals during consistency selection with different prompt designs ("MixPrompt") and foundation models ("MixLLMs"). We show that \emph{SQLPrompt} outperforms previous approaches for in-context learning with few labeled data by a large margin, closing the gap with finetuning state-of-the-art with thousands of labeled data.
Koopman Neural Forecaster for Time Series with Temporal Distribution Shifts
Oct 10, 2022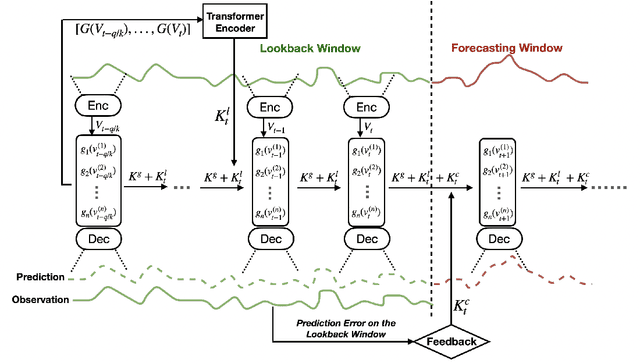

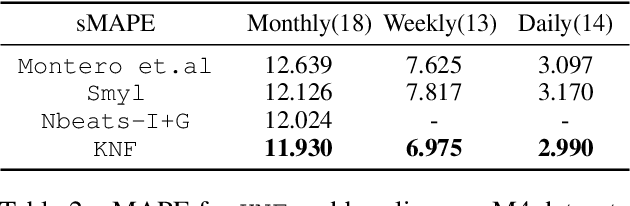
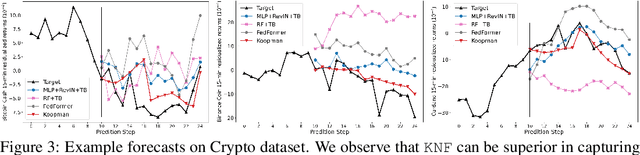
Temporal distributional shifts, with underlying dynamics changing over time, frequently occur in real-world time series, and pose a fundamental challenge for deep neural networks (DNNs). In this paper, we propose a novel deep sequence model based on the Koopman theory for time series forecasting: Koopman Neural Forecaster (KNF) that leverages DNNs to learn the linear Koopman space and the coefficients of chosen measurement functions. KNF imposes appropriate inductive biases for improved robustness against distributional shifts, employing both a global operator to learn shared characteristics, and a local operator to capture changing dynamics, as well as a specially-designed feedback loop to continuously update the learnt operators over time for rapidly varying behaviors. To the best of our knowledge, this is the first time that Koopman theory is applied to real-world chaotic time series without known governing laws. We demonstrate that KNF achieves the superior performance compared to the alternatives, on multiple time series datasets that are shown to suffer from distribution shifts.
Self-Supervised Learning with an Information Maximization Criterion
Sep 16, 2022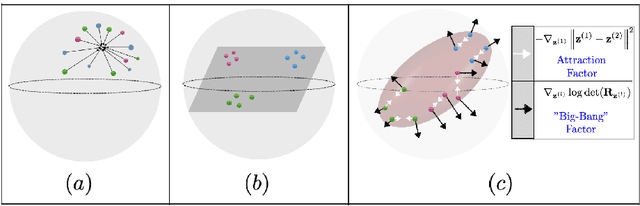
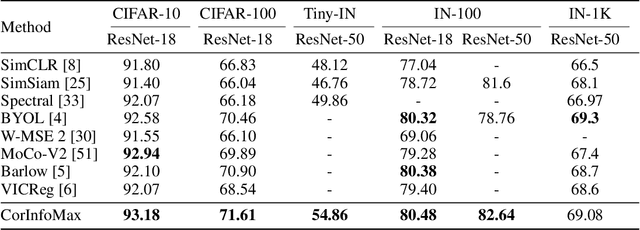
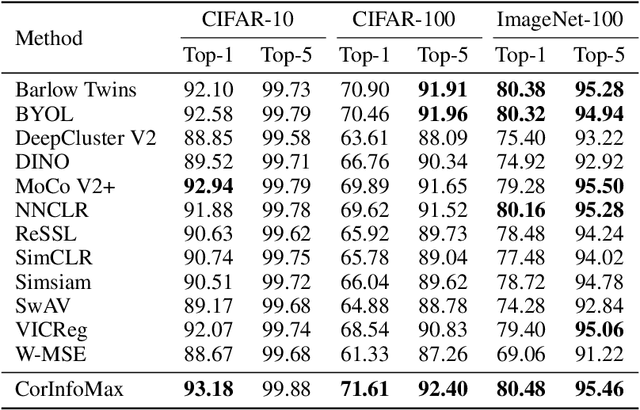
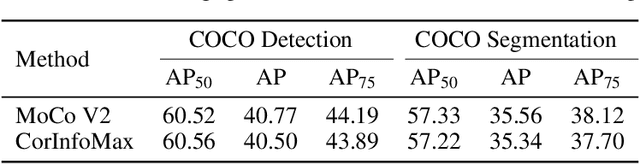
Self-supervised learning allows AI systems to learn effective representations from large amounts of data using tasks that do not require costly labeling. Mode collapse, i.e., the model producing identical representations for all inputs, is a central problem to many self-supervised learning approaches, making self-supervised tasks, such as matching distorted variants of the inputs, ineffective. In this article, we argue that a straightforward application of information maximization among alternative latent representations of the same input naturally solves the collapse problem and achieves competitive empirical results. We propose a self-supervised learning method, CorInfoMax, that uses a second-order statistics-based mutual information measure that reflects the level of correlation among its arguments. Maximizing this correlative information measure between alternative representations of the same input serves two purposes: (1) it avoids the collapse problem by generating feature vectors with non-degenerate covariances; (2) it establishes relevance among alternative representations by increasing the linear dependence among them. An approximation of the proposed information maximization objective simplifies to a Euclidean distance-based objective function regularized by the log-determinant of the feature covariance matrix. The regularization term acts as a natural barrier against feature space degeneracy. Consequently, beyond avoiding complete output collapse to a single point, the proposed approach also prevents dimensional collapse by encouraging the spread of information across the whole feature space. Numerical experiments demonstrate that CorInfoMax achieves better or competitive performance results relative to the state-of-the-art SSL approaches.
Invariant Structure Learning for Better Generalization and Causal Explainability
Jun 13, 2022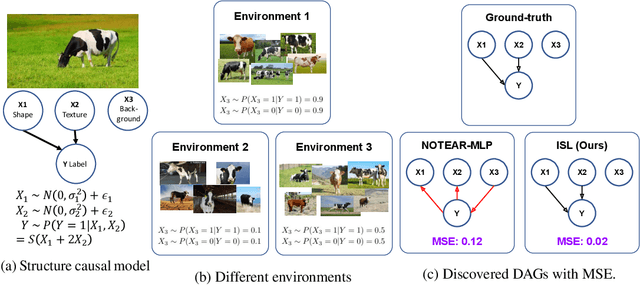
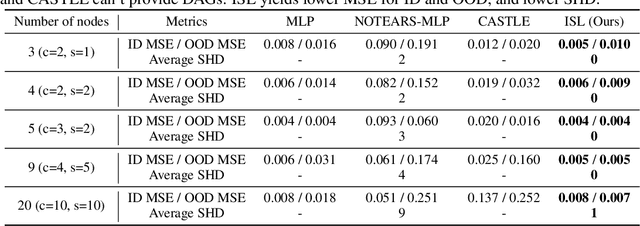
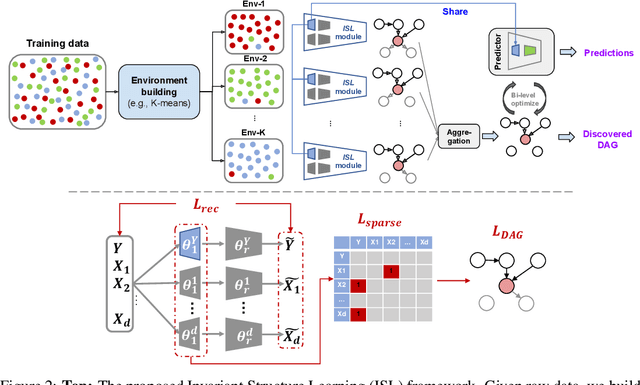

Learning the causal structure behind data is invaluable for improving generalization and obtaining high-quality explanations. We propose a novel framework, Invariant Structure Learning (ISL), that is designed to improve causal structure discovery by utilizing generalization as an indication. ISL splits the data into different environments, and learns a structure that is invariant to the target across different environments by imposing a consistency constraint. An aggregation mechanism then selects the optimal classifier based on a graph structure that reflects the causal mechanisms in the data more accurately compared to the structures learnt from individual environments. Furthermore, we extend ISL to a self-supervised learning setting where accurate causal structure discovery does not rely on any labels. This self-supervised ISL utilizes invariant causality proposals by iteratively setting different nodes as targets. On synthetic and real-world datasets, we demonstrate that ISL accurately discovers the causal structure, outperforms alternative methods, and yields superior generalization for datasets with significant distribution shifts.
Interpretable Mixture of Experts for Structured Data
Jun 05, 2022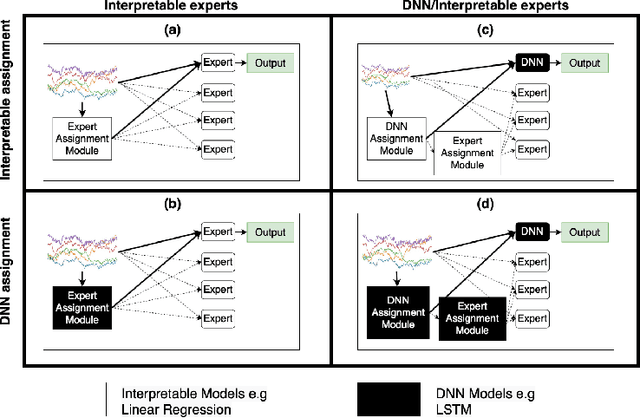
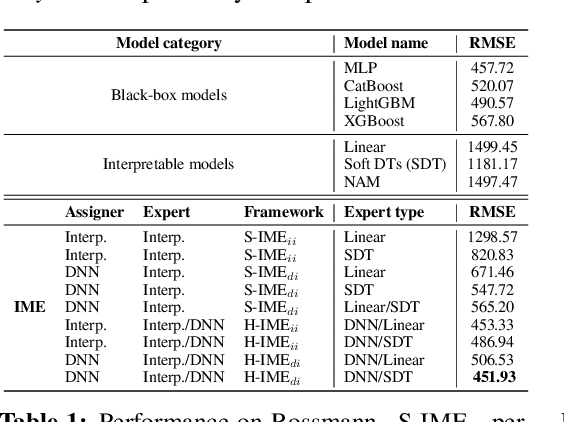
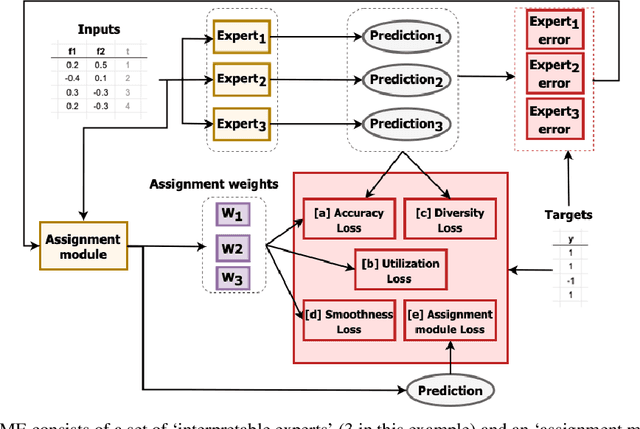
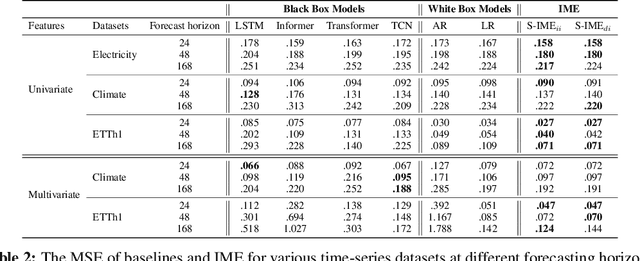
With the growth of machine learning for structured data, the need for reliable model explanations is essential, especially in high-stakes applications. We introduce a novel framework, Interpretable Mixture of Experts (IME), that provides interpretability for structured data while preserving accuracy. IME consists of an assignment module and a mixture of interpretable experts such as linear models where each sample is assigned to a single interpretable expert. This results in an inherently-interpretable architecture where the explanations produced by IME are the exact descriptions of how the prediction is computed. In addition to constituting a standalone inherently-interpretable architecture, an additional IME capability is that it can be integrated with existing Deep Neural Networks (DNNs) to offer interpretability to a subset of samples while maintaining the accuracy of the DNNs. Experiments on various structured datasets demonstrate that IME is more accurate than a single interpretable model and performs comparably to existing state-of-the-art deep learning models in terms of accuracy while providing faithful explanations.