 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgerySleuth: Empowering Multimodal Large Language Models for Image Manipulation Detection
Paper and Code
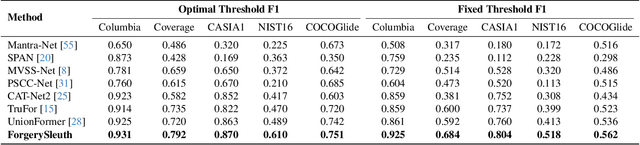
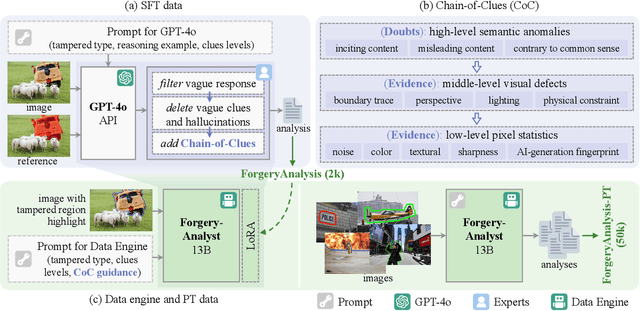
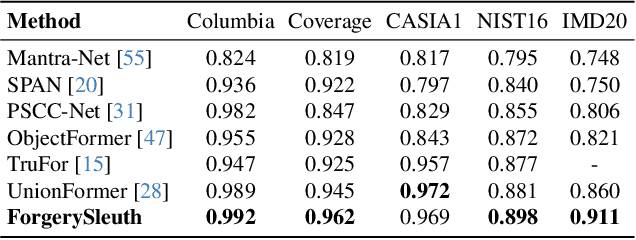
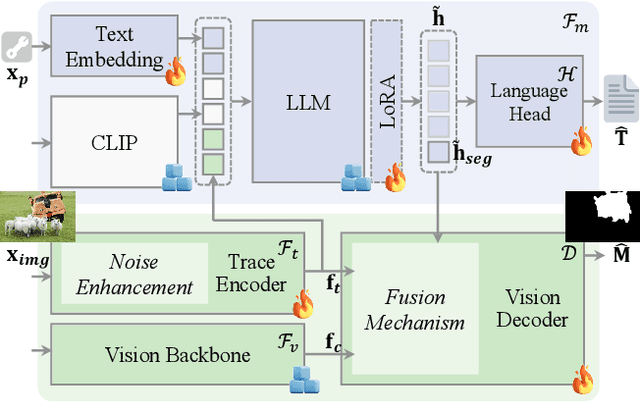
Multimodal large language models have unlocked new possibilities for various multimodal tasks. However, their potential in image manipulation detection remains unexplored. When directly applied to the IMD task, M-LLMs often produce reasoning texts that suffer from hallucinations and overthinking. To address this, in this work, we propose ForgerySleuth, which leverages M-LLMs to perform comprehensive clue fusion and generate segmentation outputs indicating specific regions that are tampered with. Moreover, we construct the ForgeryAnalysis dataset through the Chain-of-Clues prompt, which includes analysis and reasoning text to upgrade the image manipulation detection task. A data engine is also introduced to build a larger-scale dataset for the pre-training phase. Our extensive experiments demonstrate the effectiveness of ForgeryAnalysis and show that ForgerySleuth significantly outperforms existing methods in generalization, robustness, and explainability.