 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting and Mitigating Diffusion Bias via Mechanistic Interpretability
Mar 26, 2025Diffusion models have demonstrated impressive capabilities in synthesizing diverse content. However, despite their high-quality outputs, these models often perpetuate social biases, including those related to gender and race. These biases can potentially contribute to harmful real-world consequences, reinforcing stereotypes and exacerbating inequalities in various social contexts. While existing research on diffusion bias mitigation has predominantly focused on guiding content generation, it often neglects the intrinsic mechanisms within diffusion models that causally drive biased outputs. In this paper, we investigate the internal processes of diffusion models, identifying specific decision-making mechanisms, termed bias features, embedded within the model architecture. By directly manipulating these features, our method precisely isolates and adjusts the elements responsible for bias generation, permitting granular control over the bias levels in the generated content. Through experiments on both unconditional and conditional diffusion models across various social bias attributes, we demonstrate our method's efficacy in managing generation distribution while preserving image quality. We also dissect the discovered model mechanism, revealing different intrinsic features controlling fine-grained aspects of generation, boosting further research on mechanistic interpretability of diffusion models.
Discovering Influential Neuron Path in Vision Transformers
Mar 12, 2025Vision Transformer models exhibit immense power yet remain opaque to human understanding, posing challenges and risks for practical applications. While prior research has attempted to demystify these models through input attribution and neuron role analysis, there's been a notable gap in considering layer-level information and the holistic path of information flow across layers. In this paper, we investigate the significance of influential neuron paths within vision Transformers, which is a path of neurons from the model input to output that impacts the model inference most significantly. We first propose a joint influence measure to assess the contribution of a set of neurons to the model outcome. And we further provide a layer-progressive neuron locating approach that efficiently selects the most influential neuron at each layer trying to discover the crucial neuron path from input to output within the target model. Our experiments demonstrate the superiority of our method finding the most influential neuron path along which the information flows, over the existing baseline solutions. Additionally, the neuron paths have illustrated that vision Transformers exhibit some specific inner working mechanism for processing the visual information within the same image category. We further analyze the key effects of these neurons on the image classification task, showcasing that the found neuron paths have already preserved the model capability on downstream tasks, which may also shed some lights on real-world applications like model pruning. The project website including implementation code is available at https://foundation-model-research.github.io/NeuronPath/.
MVPaint: Synchronized Multi-View Diffusion for Painting Anything 3D
Nov 04, 2024



Texturing is a crucial step in the 3D asset production workflow, which enhances the visual appeal and diversity of 3D assets. Despite recent advancements in Text-to-Texture (T2T) generation, existing methods often yield subpar results, primarily due to local discontinuities, inconsistencies across multiple views, and their heavy dependence on UV unwrapping outcomes. To tackle these challenges, we propose a novel generation-refinement 3D texturing framework called MVPaint, which can generate high-resolution, seamless textures while emphasizing multi-view consistency. MVPaint mainly consists of three key modules. 1) Synchronized Multi-view Generation (SMG). Given a 3D mesh model, MVPaint first simultaneously generates multi-view images by employing an SMG model, which leads to coarse texturing results with unpainted parts due to missing observations. 2) Spatial-aware 3D Inpainting (S3I). To ensure complete 3D texturing, we introduce the S3I method, specifically designed to effectively texture previously unobserved areas. 3) UV Refinement (UVR). Furthermore, MVPaint employs a UVR module to improve the texture quality in the UV space, which first performs a UV-space Super-Resolution, followed by a Spatial-aware Seam-Smoothing algorithm for revising spatial texturing discontinuities caused by UV unwrapping. Moreover, we establish two T2T evaluation benchmarks: the Objaverse T2T benchmark and the GSO T2T benchmark, based on selected high-quality 3D meshes from the Objaverse dataset and the entire GSO dataset, respectively. Extensive experimental results demonstrate that MVPaint surpasses existing state-of-the-art methods. Notably, MVPaint could generate high-fidelity textures with minimal Janus issues and highly enhanced cross-view consistency.
MeshXL: Neural Coordinate Field for Generative 3D Foundation Models
May 31, 2024



The polygon mesh representation of 3D data exhibits great flexibility, fast rendering speed, and storage efficiency, which is widely preferred in various applications. However, given its unstructured graph representation, the direct generation of high-fidelity 3D meshes is challenging. Fortunately, with a pre-defined ordering strategy, 3D meshes can be represented as sequences, and the generation process can be seamlessly treated as an auto-regressive problem. In this paper, we validate the Neural Coordinate Field (NeurCF), an explicit coordinate representation with implicit neural embeddings, is a simple-yet-effective representation for large-scale sequential mesh modeling. After that, we present MeshXL, a family of generative pre-trained auto-regressive models, which addresses the process of 3D mesh generation with modern large language model approaches. Extensive experiments show that MeshXL is able to generate high-quality 3D meshes, and can also serve as foundation models for various down-stream applications.
CLAY: A Controllable Large-scale Generative Model for Creating High-quality 3D Assets
May 30, 2024



In the realm of digital creativity, our potential to craft intricate 3D worlds from imagination is often hampered by the limitations of existing digital tools, which demand extensive expertise and efforts. To narrow this disparity, we introduce CLAY, a 3D geometry and material generator designed to effortlessly transform human imagination into intricate 3D digital structures. CLAY supports classic text or image inputs as well as 3D-aware controls from diverse primitives (multi-view images, voxels, bounding boxes, point clouds, implicit representations, etc). At its core is a large-scale generative model composed of a multi-resolution Variational Autoencoder (VAE) and a minimalistic latent Diffusion Transformer (DiT), to extract rich 3D priors directly from a diverse range of 3D geometries. Specifically, it adopts neural fields to represent continuous and complete surfaces and uses a geometry generative module with pure transformer blocks in latent space. We present a progressive training scheme to train CLAY on an ultra large 3D model dataset obtained through a carefully designed processing pipeline, resulting in a 3D native geometry generator with 1.5 billion parameters. For appearance generation, CLAY sets out to produce physically-based rendering (PBR) textures by employing a multi-view material diffusion model that can generate 2K resolution textures with diffuse, roughness, and metallic modalities. We demonstrate using CLAY for a range of controllable 3D asset creations, from sketchy conceptual designs to production ready assets with intricate details. Even first time users can easily use CLAY to bring their vivid 3D imaginations to life, unleashing unlimited creativity.
Neural Free-Viewpoint Performance Rendering under Complex Human-object Interactions
Aug 03, 2021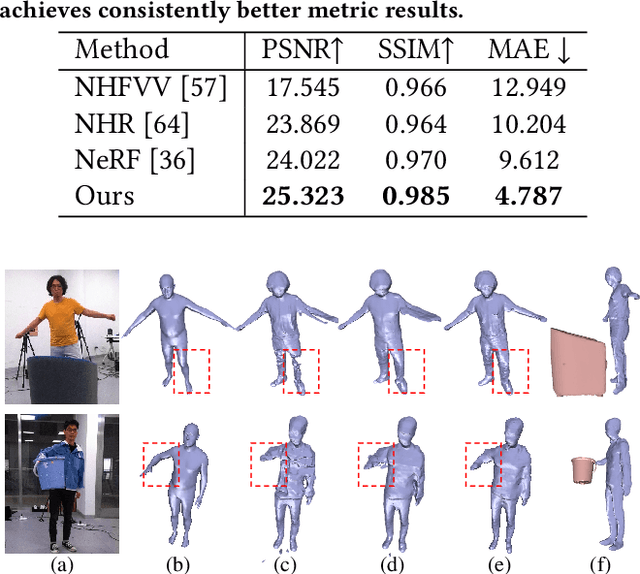
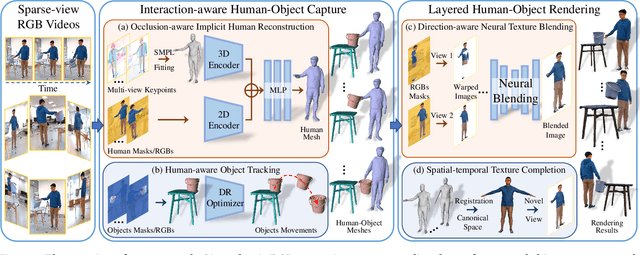
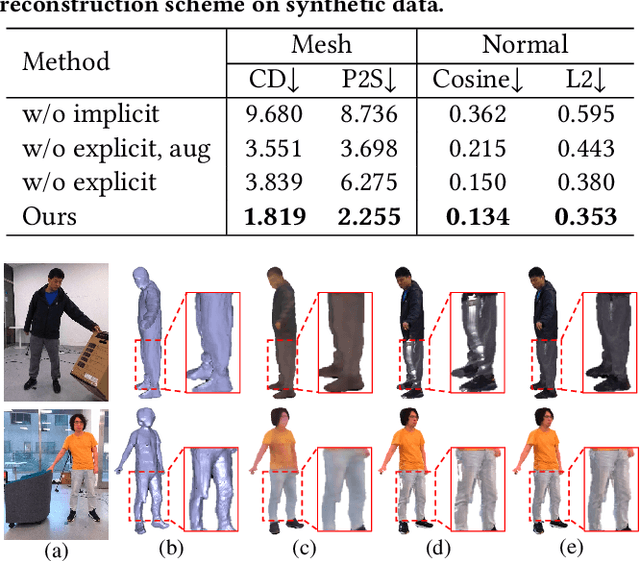

4D reconstruction of human-object interaction is critical for immersive VR/AR experience and human activity understanding. Recent advances still fail to recover fine geometry and texture results from sparse RGB inputs, especially under challenging human-object interactions scenarios. In this paper, we propose a neural human performance capture and rendering system to generate both high-quality geometry and photo-realistic texture of both human and objects under challenging interaction scenarios in arbitrary novel views, from only sparse RGB streams. To deal with complex occlusions raised by human-object interactions, we adopt a layer-wise scene decoupling strategy and perform volumetric reconstruction and neural rendering of the human and object. Specifically, for geometry reconstruction, we propose an interaction-aware human-object capture scheme that jointly considers the human reconstruction and object reconstruction with their correlations. Occlusion-aware human reconstruction and robust human-aware object tracking are proposed for consistent 4D human-object dynamic reconstruction. For neural texture rendering, we propose a layer-wise human-object rendering scheme, which combines direction-aware neural blending weight learning and spatial-temporal texture completion to provide high-resolution and photo-realistic texture results in the occluded scenarios. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality geometry and texture reconstruction in free viewpoints for challenging human-object interactions.
Few-shot Neural Human Performance Rendering from Sparse RGBD Videos
Jul 14, 2021
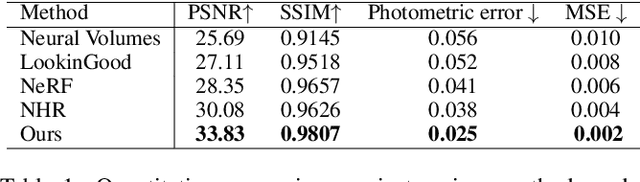

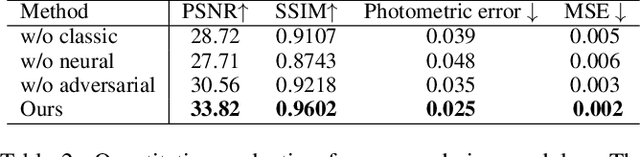
Recent neural rendering approaches for human activities achieve remarkable view synthesis results, but still rely on dense input views or dense training with all the capture frames, leading to deployment difficulty and inefficient training overload. However, existing advances will be ill-posed if the input is both spatially and temporally sparse. To fill this gap, in this paper we propose a few-shot neural human rendering approach (FNHR) from only sparse RGBD inputs, which exploits the temporal and spatial redundancy to generate photo-realistic free-view output of human activities. Our FNHR is trained only on the key-frames which expand the motion manifold in the input sequences. We introduce a two-branch neural blending to combine the neural point render and classical graphics texturing pipeline, which integrates reliable observations over sparse key-frames. Furthermore, we adopt a patch-based adversarial training process to make use of the local redundancy and avoids over-fitting to the key-frames, which generates fine-detailed rendering results. Extensive experiments demonstrate the effectiveness of our approach to generate high-quality free view-point results for challenging human performances under the sparse setting.
SportsCap: Monocular 3D Human Motion Capture and Fine-grained Understanding in Challenging Sports Videos
Apr 26, 2021


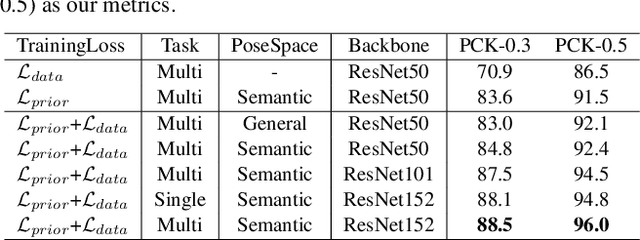
Markerless motion capture and understanding of professional non-daily human movements is an important yet unsolved task, which suffers from complex motion patterns and severe self-occlusion, especially for the monocular setting. In this paper, we propose SportsCap -- the first approach for simultaneously capturing 3D human motions and understanding fine-grained actions from monocular challenging sports video input. Our approach utilizes the semantic and temporally structured sub-motion prior in the embedding space for motion capture and understanding in a data-driven multi-task manner. To enable robust capture under complex motion patterns, we propose an effective motion embedding module to recover both the implicit motion embedding and explicit 3D motion details via a corresponding mapping function as well as a sub-motion classifier. Based on such hybrid motion information, we introduce a multi-stream spatial-temporal Graph Convolutional Network(ST-GCN) to predict the fine-grained semantic action attributes, and adopt a semantic attribute mapping block to assemble various correlated action attributes into a high-level action label for the overall detailed understanding of the whole sequence, so as to enable various applications like action assessment or motion scoring. Comprehensive experiments on both public and our proposed datasets show that with a challenging monocular sports video input, our novel approach not only significantly improves the accuracy of 3D human motion capture, but also recovers accurate fine-grained semantic action attributes.
ChallenCap: Monocular 3D Capture of Challenging Human Performances using Multi-Modal References
Mar 29, 2021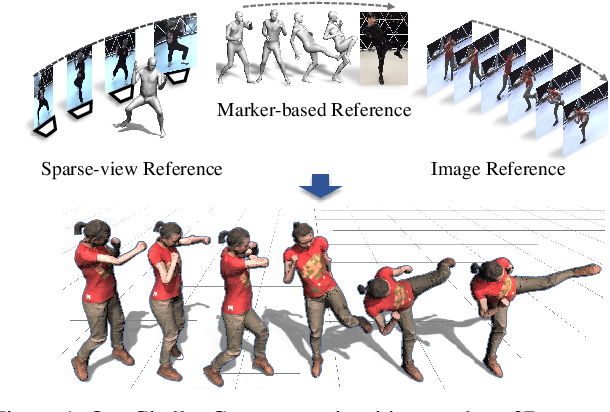
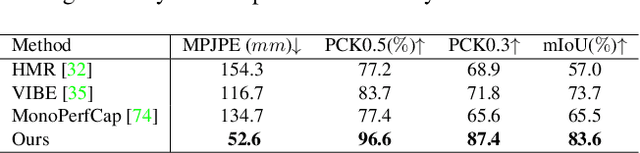
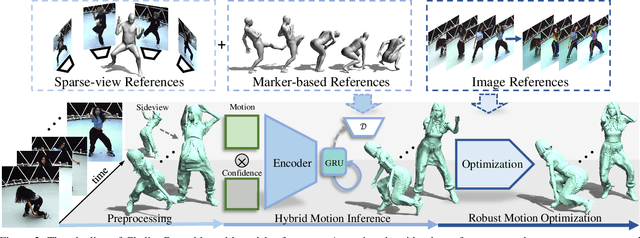

Capturing challenging human motions is critical for numerous applications, but it suffers from complex motion patterns and severe self-occlusion under the monocular setting. In this paper, we propose ChallenCap -- a template-based approach to capture challenging 3D human motions using a single RGB camera in a novel learning-and-optimization framework, with the aid of multi-modal references. We propose a hybrid motion inference stage with a generation network, which utilizes a temporal encoder-decoder to extract the motion details from the pair-wise sparse-view reference, as well as a motion discriminator to utilize the unpaired marker-based references to extract specific challenging motion characteristics in a data-driven manner. We further adopt a robust motion optimization stage to increase the tracking accuracy, by jointly utilizing the learned motion details from the supervised multi-modal references as well as the reliable motion hints from the input image reference. Extensive experiments on our new challenging motion dataset demonstrate the effectiveness and robustness of our approach to capture challenging human motions.
Towards 3D Human Shape Recovery Under Clothing
Apr 09, 2019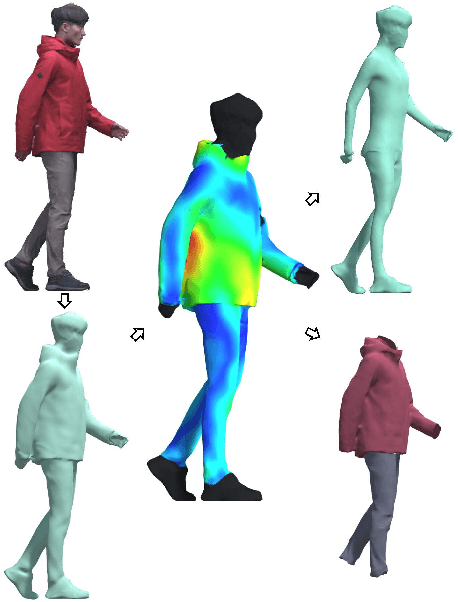
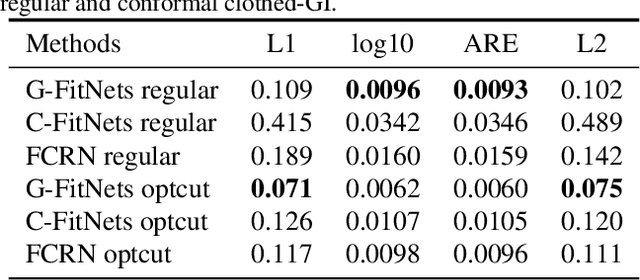

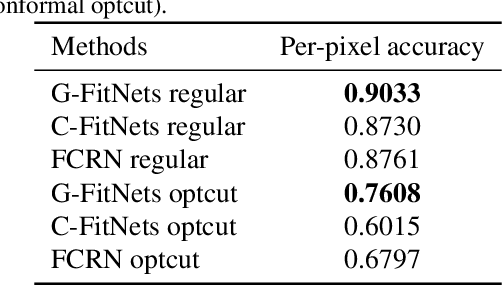
We present a learning-based scheme for robustly and accurately estimating clothing fitness as well as the human shape on clothed 3D human scans. Our approach maps the clothed human geometry to a geometry image that we call clothed-GI. To align clothed-GI under different clothing, we extend the parametric human model and employ skeleton detection and warping for reliable alignment. For each pixel on the clothed-GI, we extract a feature vector including color/texture, position, normal, etc. and train a modified conditional GAN network for per-pixel fitness prediction using a comprehensive 3D clothing. Our technique significantly improves the accuracy of human shape prediction, especially under loose and fitted clothing. We further demonstrate using our results for human/clothing segmentation and virtual clothes fitting at a high visual realism.