 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshXL: Neural Coordinate Field for Generative 3D Foundation Models
May 31, 2024



The polygon mesh representation of 3D data exhibits great flexibility, fast rendering speed, and storage efficiency, which is widely preferred in various applications. However, given its unstructured graph representation, the direct generation of high-fidelity 3D meshes is challenging. Fortunately, with a pre-defined ordering strategy, 3D meshes can be represented as sequences, and the generation process can be seamlessly treated as an auto-regressive problem. In this paper, we validate the Neural Coordinate Field (NeurCF), an explicit coordinate representation with implicit neural embeddings, is a simple-yet-effective representation for large-scale sequential mesh modeling. After that, we present MeshXL, a family of generative pre-trained auto-regressive models, which addresses the process of 3D mesh generation with modern large language model approaches. Extensive experiments show that MeshXL is able to generate high-quality 3D meshes, and can also serve as foundation models for various down-stream applications.
StyleAvatar3D: Leveraging Image-Text Diffusion Models for High-Fidelity 3D Avatar Generation
May 31, 2023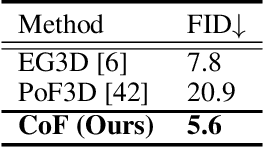
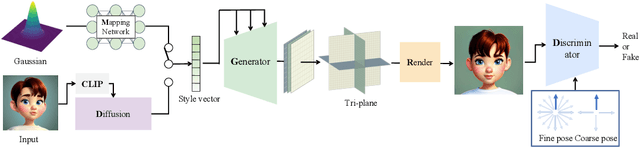


The recent advancements in image-text diffusion models have stimulated research interest in large-scale 3D generative models. Nevertheless, the limited availability of diverse 3D resources presents significant challenges to learning. In this paper, we present a novel method for generating high-quality, stylized 3D avatars that utilizes pre-trained image-text diffusion models for data generation and a Generative Adversarial Network (GAN)-based 3D generation network for training. Our method leverages the comprehensive priors of appearance and geometry offered by image-text diffusion models to generate multi-view images of avatars in various styles. During data generation, we employ poses extracted from existing 3D models to guide the generation of multi-view images. To address the misalignment between poses and images in data, we investigate view-specific prompts and develop a coarse-to-fine discriminator for GAN training. We also delve into attribute-related prompts to increase the diversity of the generated avatars. Additionally, we develop a latent diffusion model within the style space of StyleGAN to enable the generation of avatars based on image inputs. Our approach demonstrates superior performance over current state-of-the-art methods in terms of visual quality and diversity of the produced avatars.