 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt Takes Two: Real-time Co-Speech Two-person's Interaction Generation via Reactive Auto-regressive Diffusion Model
Dec 03, 2024



Conversational scenarios are very common in real-world settings, yet existing co-speech motion synthesis approaches often fall short in these contexts, where one person's audio and gestures will influence the other's responses. Additionally, most existing methods rely on offline sequence-to-sequence frameworks, which are unsuitable for online applications. In this work, we introduce an audio-driven, auto-regressive system designed to synthesize dynamic movements for two characters during a conversation. At the core of our approach is a diffusion-based full-body motion synthesis model, which is conditioned on the past states of both characters, speech audio, and a task-oriented motion trajectory input, allowing for flexible spatial control. To enhance the model's ability to learn diverse interactions, we have enriched existing two-person conversational motion datasets with more dynamic and interactive motions. We evaluate our system through multiple experiments to show it outperforms across a variety of tasks, including single and two-person co-speech motion generation, as well as interactive motion generation. To the best of our knowledge, this is the first system capable of generating interactive full-body motions for two characters from speech in an online manner.
InterAct: Capture and Modelling of Realistic, Expressive and Interactive Activities between Two Persons in Daily Scenarios
May 19, 2024



We address the problem of accurate capture and expressive modelling of interactive behaviors happening between two persons in daily scenarios. Different from previous works which either only consider one person or focus on conversational gestures, we propose to simultaneously model the activities of two persons, and target objective-driven, dynamic, and coherent interactions which often span long duration. To this end, we capture a new dataset dubbed InterAct, which is composed of 241 motion sequences where two persons perform a realistic scenario over the whole sequence. The audios, body motions, and facial expressions of both persons are all captured in our dataset. We also demonstrate the first diffusion model based approach that directly estimates the interactive motions between two persons from their audios alone. All the data and code will be available for research purposes upon acceptance of the paper.
Media2Face: Co-speech Facial Animation Generation With Multi-Modality Guidance
Jan 30, 2024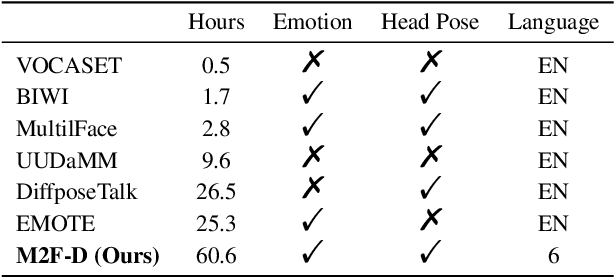
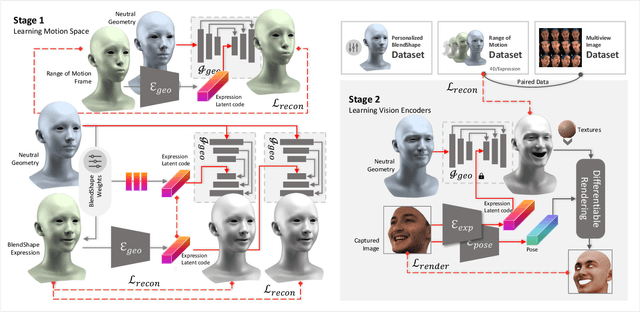

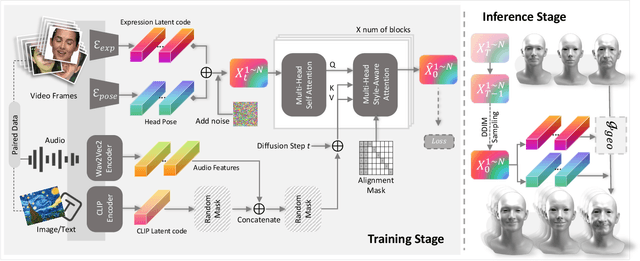
The synthesis of 3D facial animations from speech has garnered considerable attention. Due to the scarcity of high-quality 4D facial data and well-annotated abundant multi-modality labels, previous methods often suffer from limited realism and a lack of lexible conditioning. We address this challenge through a trilogy. We first introduce Generalized Neural Parametric Facial Asset (GNPFA), an efficient variational auto-encoder mapping facial geometry and images to a highly generalized expression latent space, decoupling expressions and identities. Then, we utilize GNPFA to extract high-quality expressions and accurate head poses from a large array of videos. This presents the M2F-D dataset, a large, diverse, and scan-level co-speech 3D facial animation dataset with well-annotated emotional and style labels. Finally, we propose Media2Face, a diffusion model in GNPFA latent space for co-speech facial animation generation, accepting rich multi-modality guidances from audio, text, and image. Extensive experiments demonstrate that our model not only achieves high fidelity in facial animation synthesis but also broadens the scope of expressiveness and style adaptability in 3D facial animation.
Neural Face Rigging for Animating and Retargeting Facial Meshes in the Wild
May 15, 2023We propose an end-to-end deep-learning approach for automatic rigging and retargeting of 3D models of human faces in the wild. Our approach, called Neural Face Rigging (NFR), holds three key properties: (i) NFR's expression space maintains human-interpretable editing parameters for artistic controls; (ii) NFR is readily applicable to arbitrary facial meshes with different connectivity and expressions; (iii) NFR can encode and produce fine-grained details of complex expressions performed by arbitrary subjects. To the best of our knowledge, NFR is the first approach to provide realistic and controllable deformations of in-the-wild facial meshes, without the manual creation of blendshapes or correspondence. We design a deformation autoencoder and train it through a multi-dataset training scheme, which benefits from the unique advantages of two data sources: a linear 3DMM with interpretable control parameters as in FACS, and 4D captures of real faces with fine-grained details. Through various experiments, we show NFR's ability to automatically produce realistic and accurate facial deformations across a wide range of existing datasets as well as noisy facial scans in-the-wild, while providing artist-controlled, editable parameters.