 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-aware Test-Time Training for Zero-shot Video Object Segmentation
Paper and Code
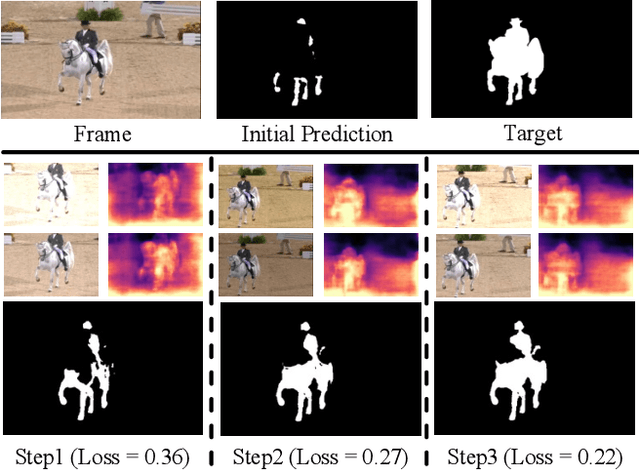
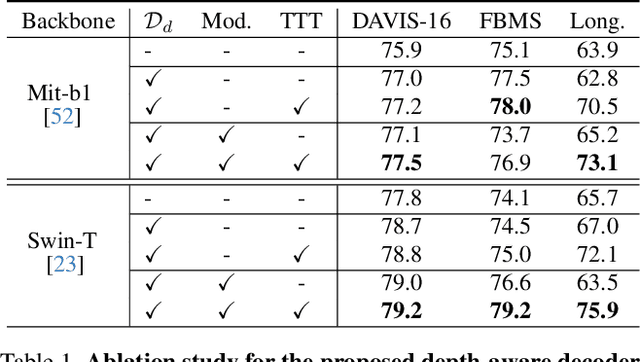
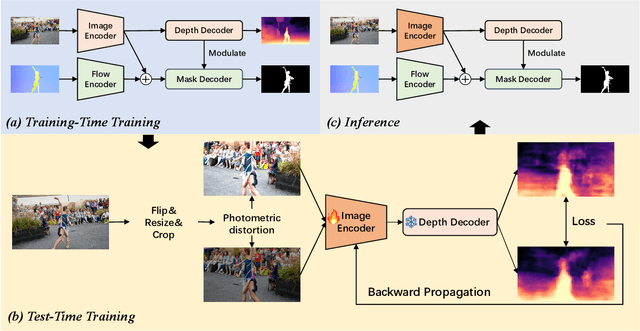
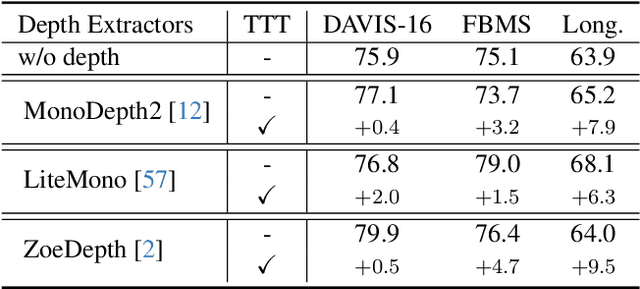
Zero-shot Video Object Segmentation (ZSVOS) aims at segmenting the primary moving object without any human annotations. Mainstream solutions mainly focus on learning a single model on large-scale video datasets, which struggle to generalize to unseen videos. In this work, we introduce a test-time training (TTT) strategy to address the problem. Our key insight is to enforce the model to predict consistent depth during the TTT process. In detail, we first train a single network to perform both segmentation and depth prediction tasks. This can be effectively learned with our specifically designed depth modulation layer. Then, for the TTT process, the model is updated by predicting consistent depth maps for the same frame under different data augmentations. In addition, we explore different TTT weight updating strategies. Our empirical results suggest that the momentum-based weight initialization and looping-based training scheme lead to more stable improvements. Experiments show that the proposed method achieves clear improvements on ZSVOS. Our proposed video TTT strategy provides significant superiority over state-of-the-art TTT methods. Our code is available at: https://nifangbaage.github.io/DATTT.