 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomMem : Learnable Dynamic Agentic Memory with Atomic Memory Operation
Jan 13, 2026Equipping agents with memory is essential for solving real-world long-horizon problems. However, most existing agent memory mechanisms rely on static and hand-crafted workflows. This limits the performance and generalization ability of these memory designs, which highlights the need for a more flexible, learning-based memory framework. In this paper, we propose AtomMem, which reframes memory management as a dynamic decision-making problem. We deconstruct high-level memory processes into fundamental atomic CRUD (Create, Read, Update, Delete) operations, transforming the memory workflow into a learnable decision process. By combining supervised fine-tuning with reinforcement learning, AtomMem learns an autonomous, task-aligned policy to orchestrate memory behaviors tailored to specific task demands. Experimental results across 3 long-context benchmarks demonstrate that the trained AtomMem-8B consistently outperforms prior static-workflow memory methods. Further analysis of training dynamics shows that our learning-based formulation enables the agent to discover structured, task-aligned memory management strategies, highlighting a key advantage over predefined routines.
Oral Imaging for Malocclusion Issues Assessments: OMNI Dataset, Deep Learning Baselines and Benchmarking
May 21, 2025Malocclusion is a major challenge in orthodontics, and its complex presentation and diverse clinical manifestations make accurate localization and diagnosis particularly important. Currently, one of the major shortcomings facing the field of dental image analysis is the lack of large-scale, accurately labeled datasets dedicated to malocclusion issues, which limits the development of automated diagnostics in the field of dentistry and leads to a lack of diagnostic accuracy and efficiency in clinical practice. Therefore, in this study, we propose the Oral and Maxillofacial Natural Images (OMNI) dataset, a novel and comprehensive dental image dataset aimed at advancing the study of analyzing dental images for issues of malocclusion. Specifically, the dataset contains 4166 multi-view images with 384 participants in data collection and annotated by professional dentists. In addition, we performed a comprehensive validation of the created OMNI dataset, including three CNN-based methods, two Transformer-based methods, and one GNN-based method, and conducted automated diagnostic experiments for malocclusion issues. The experimental results show that the OMNI dataset can facilitate the automated diagnosis research of malocclusion issues and provide a new benchmark for the research in this field. Our OMNI dataset and baseline code are publicly available at https://github.com/RoundFaceJ/OMNI.
GUICourse: From General Vision Language Models to Versatile GUI Agents
Jun 17, 2024
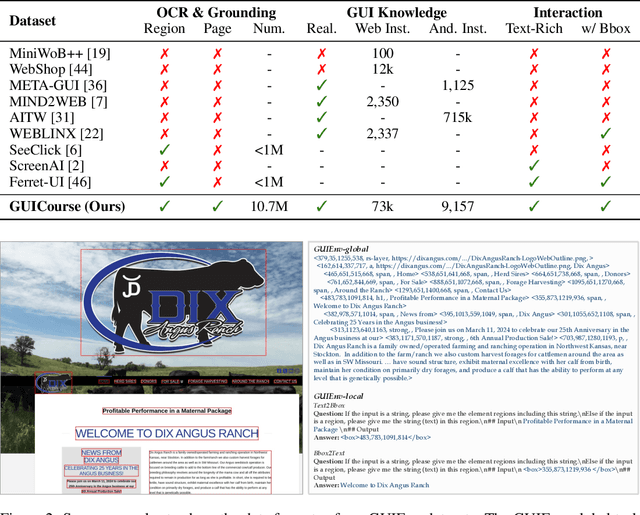
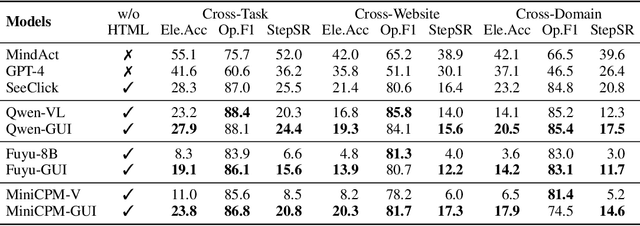
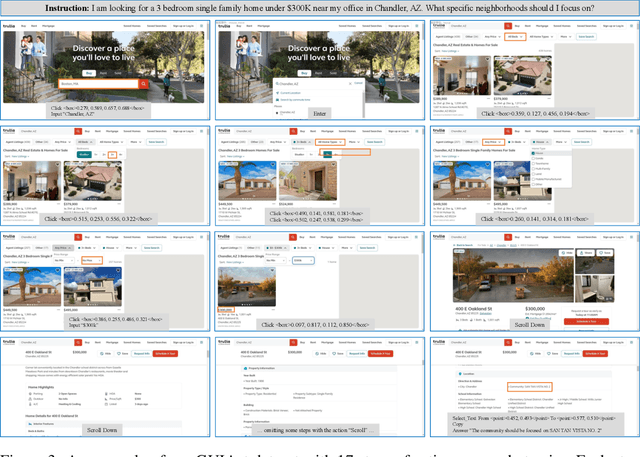
Utilizing Graphic User Interface (GUI) for human-computer interaction is essential for accessing a wide range of digital tools. Recent advancements in Vision Language Models (VLMs) highlight the compelling potential to develop versatile agents to help humans finish GUI navigation tasks. However, current VLMs are challenged in terms of fundamental abilities (OCR and grounding) and GUI knowledge (the functions and control methods of GUI elements), preventing them from becoming practical GUI agents. To solve these challenges, we contribute GUICourse, a suite of datasets to train visual-based GUI agents from general VLMs. First, we introduce the GUIEnv dataset to strengthen the OCR and grounding capabilities of VLMs. Then, we introduce the GUIAct and GUIChat datasets to enrich their knowledge of GUI components and interactions. Experiments demonstrate that our GUI agents have better performance on common GUI tasks than their baseline VLMs. Even the small-size GUI agent (with 3.1B parameters) can still work well on single-step and multi-step GUI tasks. Finally, we analyze the different varieties in the training stage of this agent by ablation study. Our source codes and datasets are released at https://github.com/yiye3/GUICourse.