 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy DPO is a Misspecified Estimator and How to Fix It
Oct 23, 2025Direct alignment algorithms such as Direct Preference Optimization (DPO) fine-tune models based on preference data, using only supervised learning instead of two-stage reinforcement learning with human feedback (RLHF). We show that DPO encodes a statistical estimation problem over reward functions induced by a parametric policy class. When the true reward function that generates preferences cannot be realized via the policy class, DPO becomes misspecified, resulting in failure modes such as preference order reversal, worsening of policy reward, and high sensitivity to the input preference data distribution. On the other hand, we study the local behavior of two-stage RLHF for a parametric class and relate it to a natural gradient step in policy space. Our fine-grained geometric characterization allows us to propose AuxDPO, which introduces additional auxiliary variables in the DPO loss function to help move towards the RLHF solution in a principled manner and mitigate the misspecification in DPO. We empirically demonstrate the superior performance of AuxDPO on didactic bandit settings as well as LLM alignment tasks.
Data Shifts Hurt CoT: A Theoretical Study
Jun 12, 2025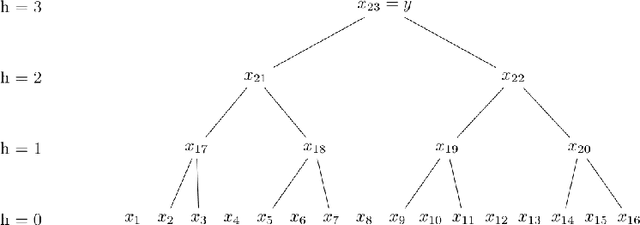
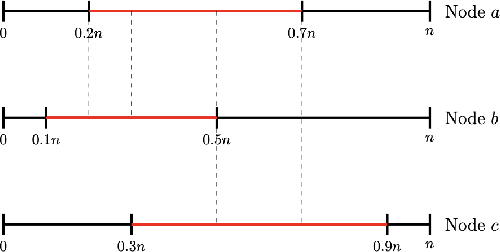
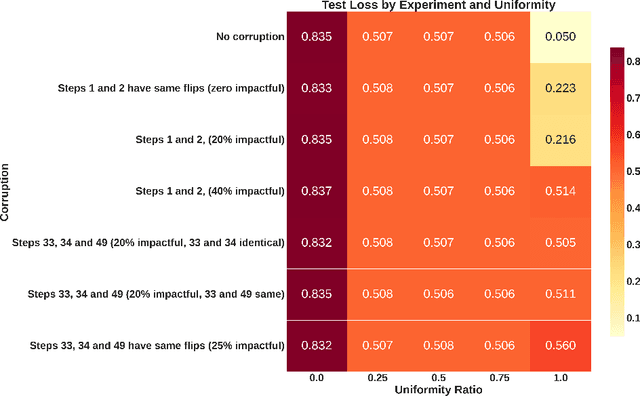
Chain of Thought (CoT) has been applied to various large language models (LLMs) and proven to be effective in improving the quality of outputs. In recent studies, transformers are proven to have absolute upper bounds in terms of expressive power, and consequently, they cannot solve many computationally difficult problems. However, empowered by CoT, transformers are proven to be able to solve some difficult problems effectively, such as the $k$-parity problem. Nevertheless, those works rely on two imperative assumptions: (1) identical training and testing distribution, and (2) corruption-free training data with correct reasoning steps. However, in the real world, these assumptions do not always hold. Although the risks of data shifts have caught attention, our work is the first to rigorously study the exact harm caused by such shifts to the best of our knowledge. Focusing on the $k$-parity problem, in this work we investigate the joint impact of two types of data shifts: the distribution shifts and data poisoning, on the quality of trained models obtained by a well-established CoT decomposition. In addition to revealing a surprising phenomenon that CoT leads to worse performance on learning parity than directly generating the prediction, our technical results also give a rigorous and comprehensive explanation of the mechanistic reasons of such impact.
DINGO: Constrained Inference for Diffusion LLMs
May 29, 2025Diffusion LLMs have emerged as a promising alternative to conventional autoregressive LLMs, offering significant potential for improved runtime efficiency. However, existing diffusion models lack the ability to provably enforce user-specified formal constraints, such as regular expressions, which makes them unreliable for tasks that require structured outputs, such as fixed-schema JSON generation. Unlike autoregressive models that generate tokens sequentially, diffusion LLMs predict a block of tokens in parallel. This parallelism makes traditional constrained decoding algorithms, which are designed for sequential token prediction, ineffective at preserving the true output distribution. To address this limitation, we propose DINGO, a dynamic programming-based constrained decoding strategy that is both efficient and provably distribution-preserving. DINGO enables sampling of output strings with the highest probability under the model's predicted distribution, while strictly satisfying any user-specified regular expression. On standard symbolic math and JSON generation benchmarks, DINGO achieves up to a 68 percentage point improvement over unconstrained inference
Support is All You Need for Certified VAE Training
Apr 16, 2025Variational Autoencoders (VAEs) have become increasingly popular and deployed in safety-critical applications. In such applications, we want to give certified probabilistic guarantees on performance under adversarial attacks. We propose a novel method, CIVET, for certified training of VAEs. CIVET depends on the key insight that we can bound worst-case VAE error by bounding the error on carefully chosen support sets at the latent layer. We show this point mathematically and present a novel training algorithm utilizing this insight. We show in an extensive evaluation across different datasets (in both the wireless and vision application areas), architectures, and perturbation magnitudes that our method outperforms SOTA methods achieving good standard performance with strong robustness guarantees.
CRANE: Reasoning with constrained LLM generation
Feb 13, 2025Code generation, symbolic math reasoning, and other tasks require LLMs to produce outputs that are both syntactically and semantically correct. Constrained LLM generation is a promising direction to enforce adherence to formal grammar, but prior works have empirically observed that strict enforcement of formal constraints often diminishes the reasoning capabilities of LLMs. In this work, we first provide a theoretical explanation for why constraining LLM outputs to very restrictive grammars that only allow syntactically valid final answers reduces the reasoning capabilities of the model. Second, we demonstrate that by augmenting the output grammar with carefully designed additional rules, it is always possible to preserve the reasoning capabilities of the LLM while ensuring syntactic and semantic correctness in its outputs. Building on these theoretical insights, we propose a reasoning-augmented constrained decoding algorithm, CRANE, which effectively balances the correctness of constrained generation with the flexibility of unconstrained generation. Experiments on multiple open-source LLMs and benchmarks show that CRANE significantly outperforms both state-of-the-art constrained decoding strategies and standard unconstrained decoding, showing up to 10% points accuracy improvement over baselines on challenging symbolic reasoning benchmarks GSM-symbolic and FOLIO.
Towards Reliable Alignment: Uncertainty-aware RLHF
Oct 31, 2024



Recent advances in aligning Large Language Models with human preferences have benefited from larger reward models and better preference data. However, most of these methodologies rely on the accuracy of the reward model. The reward models used in Reinforcement Learning with Human Feedback (RLHF) are typically learned from small datasets using stochastic optimization algorithms, making them prone to high variability. We illustrate the inconsistencies between reward models empirically on numerous open-source datasets. We theoretically show that the fluctuation of the reward models can be detrimental to the alignment problem because the derived policies are more overfitted to the reward model and, hence, are riskier if the reward model itself is uncertain. We use concentration of measure to motivate an uncertainty-aware, conservative algorithm for policy optimization. We show that such policies are more risk-averse in the sense that they are more cautious of uncertain rewards. We theoretically prove that our proposed methodology has less risk than the vanilla method. We corroborate our theoretical results with experiments based on designing an ensemble of reward models. We use this ensemble of reward models to align a language model using our methodology and observe that our empirical findings match our theoretical predictions.
Relational DNN Verification With Cross Executional Bound Refinement
May 16, 2024We focus on verifying relational properties defined over deep neural networks (DNNs) such as robustness against universal adversarial perturbations (UAP), certified worst-case hamming distance for binary string classifications, etc. Precise verification of these properties requires reasoning about multiple executions of the same DNN. However, most of the existing works in DNN verification only handle properties defined over single executions and as a result, are imprecise for relational properties. Though few recent works for relational DNN verification, capture linear dependencies between the inputs of multiple executions, they do not leverage dependencies between the outputs of hidden layers producing imprecise results. We develop a scalable relational verifier RACoon that utilizes cross-execution dependencies at all layers of the DNN gaining substantial precision over SOTA baselines on a wide range of datasets, networks, and relational properties.
When are Bandits Robust to Misspecification?
Oct 13, 2023Parametric feature-based reward models are widely employed by algorithms for decision making settings such as bandits and contextual bandits. The typical assumption under which they are analysed is realizability, i.e., that the true rewards of actions are perfectly explained by some parametric model in the class. We are, however, interested in the situation where the true rewards are (potentially significantly) misspecified with respect to the model class. For parameterized bandits and contextual bandits, we identify sufficient conditions, depending on the problem instance and model class, under which classic algorithms such as $\epsilon$-greedy and LinUCB enjoy sublinear (in the time horizon) regret guarantees under even grossly misspecified rewards. This is in contrast to existing worst-case results for misspecified bandits which show regret bounds that scale linearly with time, and shows that there can be a nontrivially large set of bandit instances that are robust to misspecification.
Incremental Randomized Smoothing Certification
May 31, 2023Randomized smoothing-based certification is an effective approach for obtaining robustness certificates of deep neural networks (DNNs) against adversarial attacks. This method constructs a smoothed DNN model and certifies its robustness through statistical sampling, but it is computationally expensive, especially when certifying with a large number of samples. Furthermore, when the smoothed model is modified (e.g., quantized or pruned), certification guarantees may not hold for the modified DNN, and recertifying from scratch can be prohibitively expensive. We present the first approach for incremental robustness certification for randomized smoothing, IRS. We show how to reuse the certification guarantees for the original smoothed model to certify an approximated model with very few samples. IRS significantly reduces the computational cost of certifying modified DNNs while maintaining strong robustness guarantees. We experimentally demonstrate the effectiveness of our approach, showing up to 3x certification speedup over the certification that applies randomized smoothing of the approximate model from scratch.
Incremental Verification of Neural Networks
Apr 04, 2023



Complete verification of deep neural networks (DNNs) can exactly determine whether the DNN satisfies a desired trustworthy property (e.g., robustness, fairness) on an infinite set of inputs or not. Despite the tremendous progress to improve the scalability of complete verifiers over the years on individual DNNs, they are inherently inefficient when a deployed DNN is updated to improve its inference speed or accuracy. The inefficiency is because the expensive verifier needs to be run from scratch on the updated DNN. To improve efficiency, we propose a new, general framework for incremental and complete DNN verification based on the design of novel theory, data structure, and algorithms. Our contributions implemented in a tool named IVAN yield an overall geometric mean speedup of 2.4x for verifying challenging MNIST and CIFAR10 classifiers and a geometric mean speedup of 3.8x for the ACAS-XU classifiers over the state-of-the-art baselines.