 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentRx: Diagnosing AI Agent Failures from Execution Trajectories
Feb 02, 2026AI agents often fail in ways that are difficult to localize because executions are probabilistic, long-horizon, multi-agent, and mediated by noisy tool outputs. We address this gap by manually annotating failed agent runs and release a novel benchmark of 115 failed trajectories spanning structured API workflows, incident management, and open-ended web/file tasks. Each trajectory is annotated with a critical failure step and a category from a grounded-theory derived, cross-domain failure taxonomy. To mitigate the human cost of failure attribution, we present AGENTRX, an automated domain-agnostic diagnostic framework that pinpoints the critical failure step in a failed agent trajectory. It synthesizes constraints, evaluates them step-by-step, and produces an auditable validation log of constraint violations with associated evidence; an LLM-based judge uses this log to localize the critical step and category. Our framework improves step localization and failure attribution over existing baselines across three domains.
Cost-Driven Synthesis of Sound Abstract Interpreters
Nov 17, 2025Constructing abstract interpreters that provide global soundness guarantees remains a major obstacle in abstract interpretation. We investigate whether modern LLMs can reduce this burden by leveraging them to synthesize sound, non-trivial abstract interpreters across multiple abstract domains in the setting of neural network verification. We formulate synthesis as a constrained optimization problem and introduce a novel mathematically grounded cost function for measuring unsoundness under strict syntactic and semantic constraints. Based on this formulation, we develop a unified framework that unifies LLM-based generation with syntactic and semantic validation and a quantitative cost-guided feedback mechanism. Empirical results demonstrate that our framework not only matches the quality of handcrafted transformers, but more importantly, discovers sound, high-precision transformers for complex nonlinear operators that are absent from existing literature.
A Tensor-Based Compiler and a Runtime for Neuron-Level DNN Certifier Specifications
Jul 26, 2025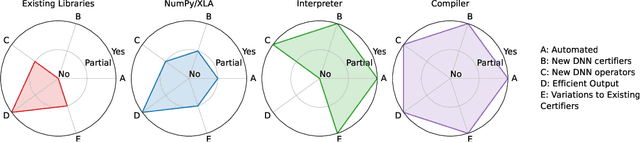


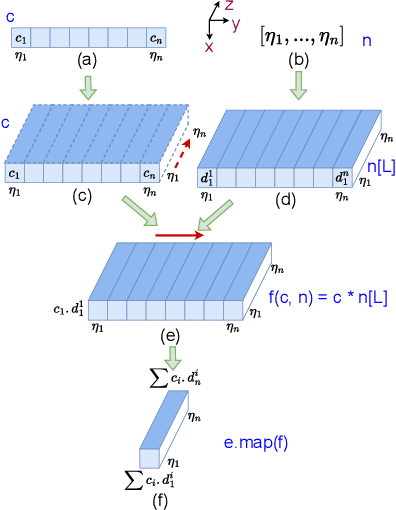
The uninterpretability of DNNs has led to the adoption of abstract interpretation-based certification as a practical means to establish trust in real-world systems that rely on DNNs. However, the current landscape supports only a limited set of certifiers, and developing new ones or modifying existing ones for different applications remains difficult. This is because the mathematical design of certifiers is expressed at the neuron level, while their implementations are optimized and executed at the tensor level. This mismatch creates a semantic gap between design and implementation, making manual bridging both complex and expertise-intensive -- requiring deep knowledge in formal methods, high-performance computing, etc. We propose a compiler framework that automatically translates neuron-level specifications of DNN certifiers into tensor-based, layer-level implementations. This is enabled by two key innovations: a novel stack-based intermediate representation (IR) and a shape analysis that infers the implicit tensor operations needed to simulate the neuron-level semantics. During lifting, the shape analysis creates tensors in the minimal shape required to perform the corresponding operations. The IR also enables domain-specific optimizations as rewrites. At runtime, the resulting tensor computations exhibit sparsity tied to the DNN architecture. This sparsity does not align well with existing formats. To address this, we introduce g-BCSR, a double-compression format that represents tensors as collections of blocks of varying sizes, each possibly internally sparse. Using our compiler and g-BCSR, we make it easy to develop new certifiers and analyze their utility across diverse DNNs. Despite its flexibility, the compiler achieves performance comparable to hand-optimized implementations.
Interpreting Robustness Proofs of Deep Neural Networks
Jan 31, 2023In recent years numerous methods have been developed to formally verify the robustness of deep neural networks (DNNs). Though the proposed techniques are effective in providing mathematical guarantees about the DNNs behavior, it is not clear whether the proofs generated by these methods are human-interpretable. In this paper, we bridge this gap by developing new concepts, algorithms, and representations to generate human understandable interpretations of the proofs. Leveraging the proposed method, we show that the robustness proofs of standard DNNs rely on spurious input features, while the proofs of DNNs trained to be provably robust filter out even the semantically meaningful features. The proofs for the DNNs combining adversarial and provably robust training are the most effective at selectively filtering out spurious features as well as relying on human-understandable input features.