 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Signs: A Survey of Edge-Deployable OCR Models for Billboard Visibility Analysis
Jul 15, 2025



Outdoor advertisements remain a critical medium for modern marketing, yet accurately verifying billboard text visibility under real-world conditions is still challenging. Traditional Optical Character Recognition (OCR) pipelines excel at cropped text recognition but often struggle with complex outdoor scenes, varying fonts, and weather-induced visual noise. Recently, multimodal Vision-Language Models (VLMs) have emerged as promising alternatives, offering end-to-end scene understanding with no explicit detection step. This work systematically benchmarks representative VLMs - including Qwen 2.5 VL 3B, InternVL3, and SmolVLM2 - against a compact CNN-based OCR baseline (PaddleOCRv4) across two public datasets (ICDAR 2015 and SVT), augmented with synthetic weather distortions to simulate realistic degradation. Our results reveal that while selected VLMs excel at holistic scene reasoning, lightweight CNN pipelines still achieve competitive accuracy for cropped text at a fraction of the computational cost-an important consideration for edge deployment. To foster future research, we release our weather-augmented benchmark and evaluation code publicly.
LLaMA-NAS: Efficient Neural Architecture Search for Large Language Models
May 28, 2024The abilities of modern large language models (LLMs) in solving natural language processing, complex reasoning, sentiment analysis and other tasks have been extraordinary which has prompted their extensive adoption. Unfortunately, these abilities come with very high memory and computational costs which precludes the use of LLMs on most hardware platforms. To mitigate this, we propose an effective method of finding Pareto-optimal network architectures based on LLaMA2-7B using one-shot NAS. In particular, we fine-tune LLaMA2-7B only once and then apply genetic algorithm-based search to find smaller, less computationally complex network architectures. We show that, for certain standard benchmark tasks, the pre-trained LLaMA2-7B network is unnecessarily large and complex. More specifically, we demonstrate a 1.5x reduction in model size and 1.3x speedup in throughput for certain tasks with negligible drop in accuracy. In addition to finding smaller, higher-performing network architectures, our method does so more effectively and efficiently than certain pruning or sparsification techniques. Finally, we demonstrate how quantization is complementary to our method and that the size and complexity of the networks we find can be further decreased using quantization. We believe that our work provides a way to automatically create LLMs which can be used on less expensive and more readily available hardware platforms.
SimQ-NAS: Simultaneous Quantization Policy and Neural Architecture Search
Dec 19, 2023Recent one-shot Neural Architecture Search algorithms rely on training a hardware-agnostic super-network tailored to a specific task and then extracting efficient sub-networks for different hardware platforms. Popular approaches separate the training of super-networks from the search for sub-networks, often employing predictors to alleviate the computational overhead associated with search. Additionally, certain methods also incorporate the quantization policy within the search space. However, while the quantization policy search for convolutional neural networks is well studied, the extension of these methods to transformers and especially foundation models remains under-explored. In this paper, we demonstrate that by using multi-objective search algorithms paired with lightly trained predictors, we can efficiently search for both the sub-network architecture and the corresponding quantization policy and outperform their respective baselines across different performance objectives such as accuracy, model size, and latency. Specifically, we demonstrate that our approach performs well across both uni-modal (ViT and BERT) and multi-modal (BEiT-3) transformer-based architectures as well as convolutional architectures (ResNet). For certain networks, we demonstrate an improvement of up to $4.80x$ and $3.44x$ for latency and model size respectively, without degradation in accuracy compared to the fully quantized INT8 baselines.
InstaTune: Instantaneous Neural Architecture Search During Fine-Tuning
Aug 29, 2023



One-Shot Neural Architecture Search (NAS) algorithms often rely on training a hardware agnostic super-network for a domain specific task. Optimal sub-networks are then extracted from the trained super-network for different hardware platforms. However, training super-networks from scratch can be extremely time consuming and compute intensive especially for large models that rely on a two-stage training process of pre-training and fine-tuning. State of the art pre-trained models are available for a wide range of tasks, but their large sizes significantly limits their applicability on various hardware platforms. We propose InstaTune, a method that leverages off-the-shelf pre-trained weights for large models and generates a super-network during the fine-tuning stage. InstaTune has multiple benefits. Firstly, since the process happens during fine-tuning, it minimizes the overall time and compute resources required for NAS. Secondly, the sub-networks extracted are optimized for the target task, unlike prior work that optimizes on the pre-training objective. Finally, InstaTune is easy to "plug and play" in existing frameworks. By using multi-objective evolutionary search algorithms along with lightly trained predictors, we find Pareto-optimal sub-networks that outperform their respective baselines across different performance objectives such as accuracy and MACs. Specifically, we demonstrate that our approach performs well across both unimodal (ViT and BERT) and multi-modal (BEiT-3) transformer based architectures.
Sensi-BERT: Towards Sensitivity Driven Fine-Tuning for Parameter-Efficient BERT
Jul 14, 2023Large pre-trained language models have recently gained significant traction due to their improved performance on various down-stream tasks like text classification and question answering, requiring only few epochs of fine-tuning. However, their large model sizes often prohibit their applications on resource-constrained edge devices. Existing solutions of yielding parameter-efficient BERT models largely rely on compute-exhaustive training and fine-tuning. Moreover, they often rely on additional compute heavy models to mitigate the performance gap. In this paper, we present Sensi-BERT, a sensitivity driven efficient fine-tuning of BERT models that can take an off-the-shelf pre-trained BERT model and yield highly parameter-efficient models for downstream tasks. In particular, we perform sensitivity analysis to rank each individual parameter tensor, that then is used to trim them accordingly during fine-tuning for a given parameter or FLOPs budget. Our experiments show the efficacy of Sensi-BERT across different downstream tasks including MNLI, QQP, QNLI, and SST-2, demonstrating better performance at similar or smaller parameter budget compared to various existing alternatives.
A Hardware-Aware Framework for Accelerating Neural Architecture Search Across Modalities
May 19, 2022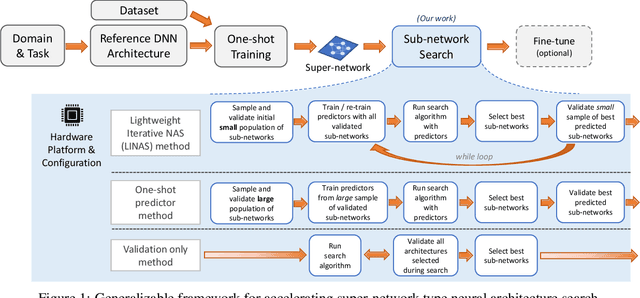
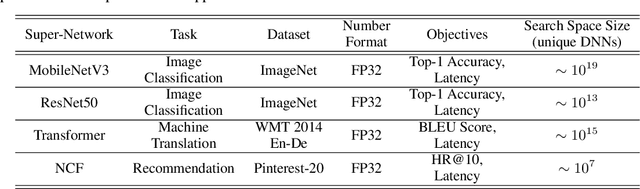
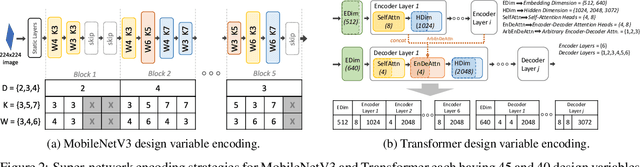
Recent advances in Neural Architecture Search (NAS) such as one-shot NAS offer the ability to extract specialized hardware-aware sub-network configurations from a task-specific super-network. While considerable effort has been employed towards improving the first stage, namely, the training of the super-network, the search for derivative high-performing sub-networks is still under-explored. Popular methods decouple the super-network training from the sub-network search and use performance predictors to reduce the computational burden of searching on different hardware platforms. We propose a flexible search framework that automatically and efficiently finds optimal sub-networks that are optimized for different performance metrics and hardware configurations. Specifically, we show how evolutionary algorithms can be paired with lightly trained objective predictors in an iterative cycle to accelerate architecture search in a multi-objective setting for various modalities including machine translation and image classification.
A Hardware-Aware System for Accelerating Deep Neural Network Optimization
Feb 25, 2022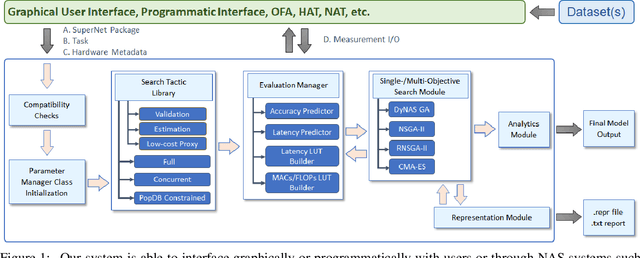
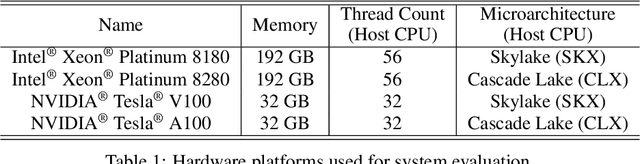
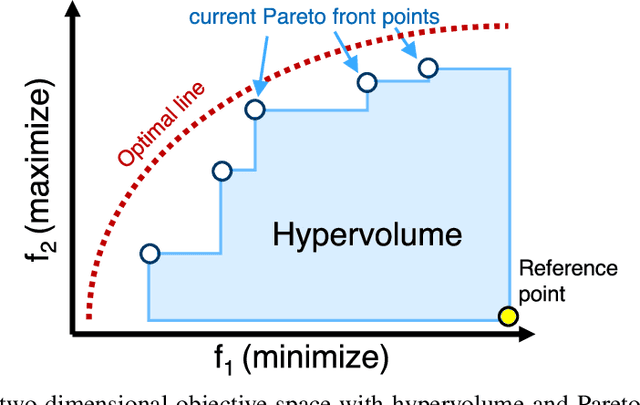
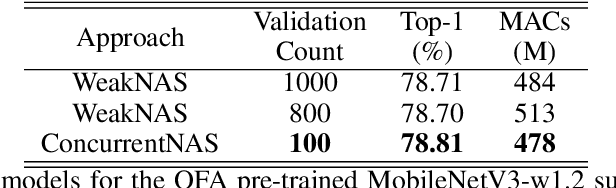
Recent advances in Neural Architecture Search (NAS) which extract specialized hardware-aware configurations (a.k.a. "sub-networks") from a hardware-agnostic "super-network" have become increasingly popular. While considerable effort has been employed towards improving the first stage, namely, the training of the super-network, the search for derivative high-performing sub-networks is still largely under-explored. For example, some recent network morphism techniques allow a super-network to be trained once and then have hardware-specific networks extracted from it as needed. These methods decouple the super-network training from the sub-network search and thus decrease the computational burden of specializing to different hardware platforms. We propose a comprehensive system that automatically and efficiently finds sub-networks from a pre-trained super-network that are optimized to different performance metrics and hardware configurations. By combining novel search tactics and algorithms with intelligent use of predictors, we significantly decrease the time needed to find optimal sub-networks from a given super-network. Further, our approach does not require the super-network to be refined for the target task a priori, thus allowing it to interface with any super-network. We demonstrate through extensive experiments that our system works seamlessly with existing state-of-the-art super-network training methods in multiple domains. Moreover, we show how novel search tactics paired with evolutionary algorithms can accelerate the search process for ResNet50, MobileNetV3 and Transformer while maintaining objective space Pareto front diversity and demonstrate an 8x faster search result than the state-of-the-art Bayesian optimization WeakNAS approach.
Accelerating Neural Architecture Exploration Across Modalities Using Genetic Algorithms
Feb 25, 2022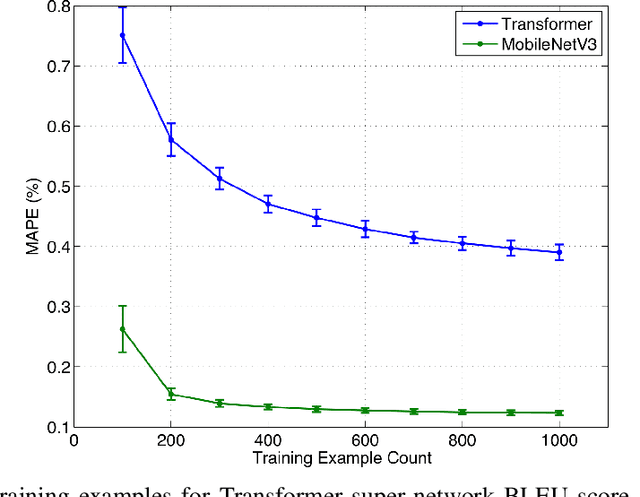
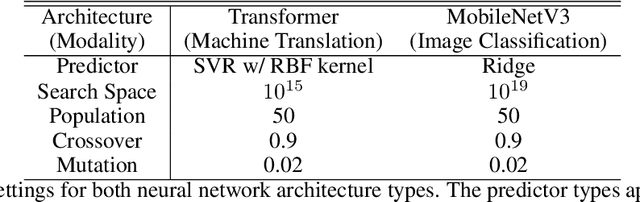
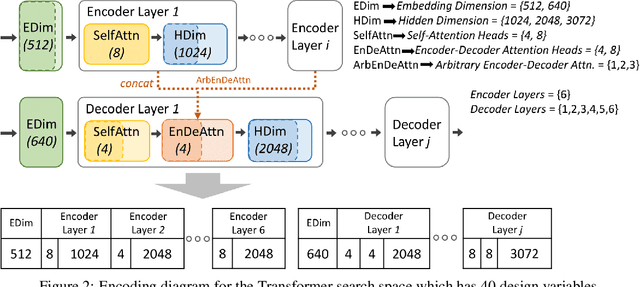
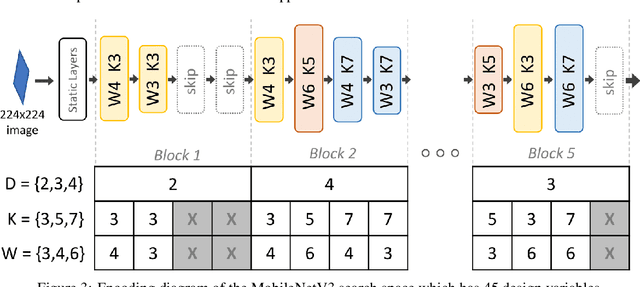
Neural architecture search (NAS), the study of automating the discovery of optimal deep neural network architectures for tasks in domains such as computer vision and natural language processing, has seen rapid growth in the machine learning research community. While there have been many recent advancements in NAS, there is still a significant focus on reducing the computational cost incurred when validating discovered architectures by making search more efficient. Evolutionary algorithms, specifically genetic algorithms, have a history of usage in NAS and continue to gain popularity versus other optimization approaches as a highly efficient way to explore the architecture objective space. Most NAS research efforts have centered around computer vision tasks and only recently have other modalities, such as the rapidly growing field of natural language processing, been investigated in depth. In this work, we show how genetic algorithms can be paired with lightly trained objective predictors in an iterative cycle to accelerate multi-objective architectural exploration in a way that works in the modalities of both machine translation and image classification.