 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Depth, Camera Pose and Optical Flow from Monocular Video
May 19, 2022



We propose DFPNet -- an unsupervised, joint learning system for monocular Depth, Optical Flow and egomotion (Camera Pose) estimation from monocular image sequences. Due to the nature of 3D scene geometry these three components are coupled. We leverage this fact to jointly train all the three components in an end-to-end manner. A single composite loss function -- which involves image reconstruction-based loss for depth & optical flow, bidirectional consistency checks and smoothness loss components -- is used to train the network. Using hyperparameter tuning, we are able to reduce the model size to less than 5% (8.4M parameters) of state-of-the-art DFP models. Evaluation on KITTI and Cityscapes driving datasets reveals that our model achieves results comparable to state-of-the-art in all of the three tasks, even with the significantly smaller model size.
Finnish Language Modeling with Deep Transformer Models
Mar 27, 2020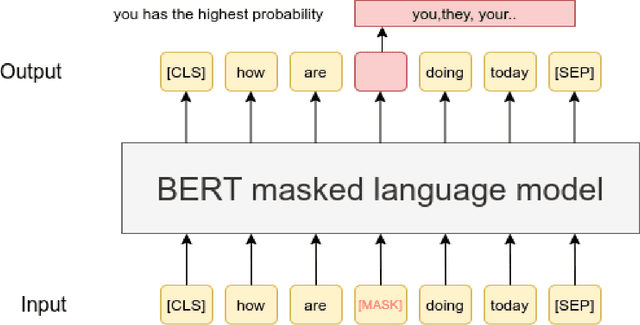
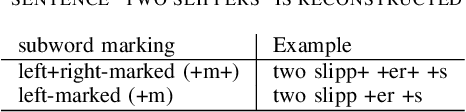


Transformers have recently taken the center stage in language modeling after LSTM's were considered the dominant model architecture for a long time. In this project, we investigate the performance of the Transformer architectures-BERT and Transformer-XL for the language modeling task. We use a sub-word model setting with the Finnish language and compare it to the previous State of the art (SOTA) LSTM model. BERT achieves a pseudo-perplexity score of 14.5, which is the first such measure achieved as far as we know. Transformer-XL improves upon the perplexity score to 73.58 which is 27\% better than the LSTM model.