Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinnish Language Modeling with Deep Transformer Models
Mar 27, 2020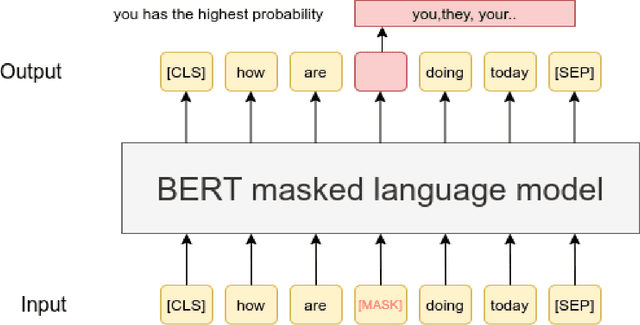
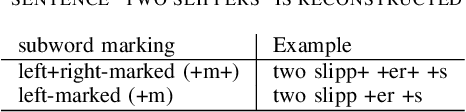


Transformers have recently taken the center stage in language modeling after LSTM's were considered the dominant model architecture for a long time. In this project, we investigate the performance of the Transformer architectures-BERT and Transformer-XL for the language modeling task. We use a sub-word model setting with the Finnish language and compare it to the previous State of the art (SOTA) LSTM model. BERT achieves a pseudo-perplexity score of 14.5, which is the first such measure achieved as far as we know. Transformer-XL improves upon the perplexity score to 73.58 which is 27\% better than the LSTM model.
* 4 pages
Via