 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning-Driven Intelligent Memory System Design: From On-Chip Caches to Storage
Mar 15, 2026Despite the data-rich environment in which memory systems of modern computing platforms operate, many state-of-the-art architectural policies employed in the memory system rely on static, human-designed heuristics that fail to truly adapt to the workload and system behavior via principled learning methodologies. In this article, we propose a fundamentally different design approach: using lightweight and practical machine learning (ML) methods to enable adaptive, data-driven control throughout the memory hierarchy. We present three ML-guided architectural policies: (1) Pythia, a reinforcement learning-based data prefetcher for on-chip caches, (2) Hermes, a perceptron learning-based off-chip predictor for multi-level cache hierarchies, and (3) Sibyl, a reinforcement learning-based data placement policy for hybrid storage systems. Our evaluation shows that Pythia, Hermes, and Sibyl significantly outperform the best-prior human-designed policies, while incurring modest hardware overheads. Collectively, this article demonstrates that integrating adaptive learning into memory subsystems can lead to intelligent, self-optimizing architectures that unlock performance and efficiency gains beyond what is possible with traditional human-designed approaches.
Mitigating the Memory Bottleneck with Machine Learning-Driven and Data-Aware Microarchitectural Techniques
Mar 08, 2026Modern applications process massive data volumes that overwhelm the storage and retrieval capabilities of memory systems, making memory the primary performance and energy-efficiency bottleneck of computing systems. Although many microarchitectural techniques attempt to hide or tolerate long memory access latency, rapidly growing data footprints continue to outpace technology scaling, requiring more effective solutions. This dissertation shows that modern processors observe large amounts of application and system data during execution, yet many microarchitectural mechanisms make decisions largely independent of this information. Through four case studies, we demonstrate that such data-agnostic design leads to substantial missed opportunities for improving performance and energy efficiency. To address this limitation, this dissertation advocates shifting microarchitecture design from data-agnostic to data-informed. We propose mechanisms that (1) learn policies from observed execution behavior (data-driven design) and (2) exploit semantic characteristics of application data (data-aware design). We apply lightweight machine learning techniques and previously underexplored data characteristics across four processor components: a reinforcement learning-based hardware data prefetcher that learns memory access patterns online; a perceptron predictor that identifies memory requests likely to access off-chip memory; a reinforcement learning mechanism that coordinates data prefetching and off-chip prediction; and a mechanism that exploits repeatability in memory addresses and loaded values to eliminate predictable load instructions. Our extensive evaluation shows that the proposed techniques significantly improve performance and energy efficiency compared to prior state-of-the-art approaches.
Athena: Synergizing Data Prefetching and Off-Chip Prediction via Online Reinforcement Learning
Jan 24, 2026Prefetching and off-chip prediction are two techniques proposed to hide long memory access latencies in high-performance processors. In this work, we demonstrate that: (1) prefetching and off-chip prediction often provide complementary performance benefits, yet (2) naively combining them often fails to realize their full performance potential, and (3) existing prefetcher control policies leave significant room for performance improvement behind. Our goal is to design a holistic framework that can autonomously learn to coordinate an off-chip predictor with multiple prefetchers employed at various cache levels. To this end, we propose a new technique called Athena, which models the coordination between prefetchers and off-chip predictor (OCP) as a reinforcement learning (RL) problem. Athena acts as the RL agent that observes multiple system-level features (e.g., prefetcher/OCP accuracy, bandwidth usage) over an epoch of program execution, and uses them as state information to select a coordination action (i.e., enabling the prefetcher and/or OCP, and adjusting prefetcher aggressiveness). At the end of every epoch, Athena receives a numerical reward that measures the change in multiple system-level metrics (e.g., number of cycles taken to execute an epoch). Athena uses this reward to autonomously and continuously learn a policy to coordinate prefetchers with OCP. Our extensive evaluation using a diverse set of memory-intensive workloads shows that Athena consistently outperforms prior state-of-the-art coordination policies across a wide range of system configurations with various combinations of underlying prefetchers, OCPs, and main memory bandwidths, while incurring only modest storage overhead. Athena is freely available at https://github.com/CMU-SAFARI/Athena.
Harmonia: A Multi-Agent Reinforcement Learning Approach to Data Placement and Migration in Hybrid Storage Systems
Mar 26, 2025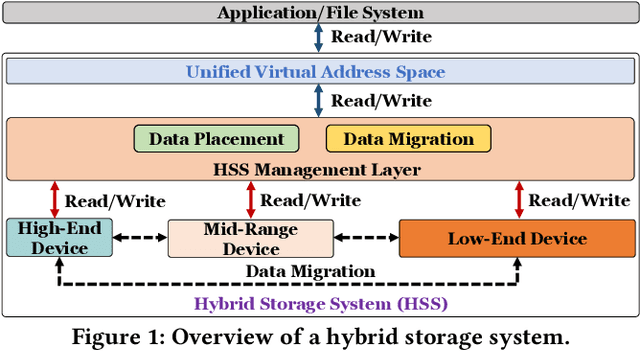
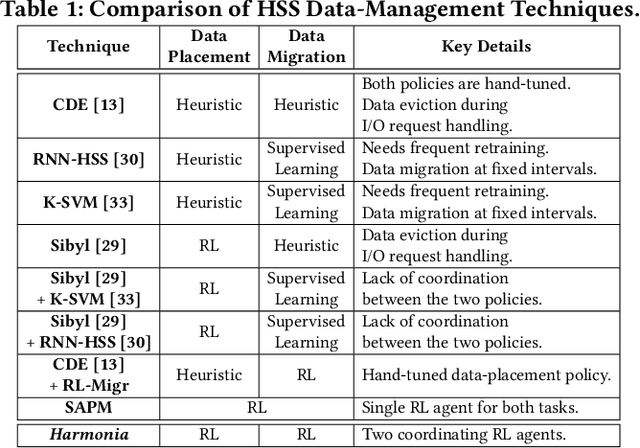
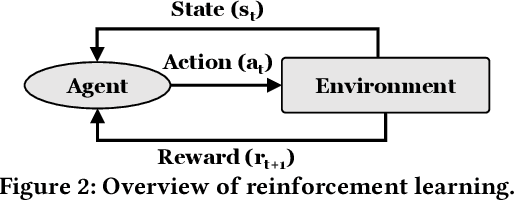

Hybrid storage systems (HSS) combine multiple storage devices with diverse characteristics to achieve high performance and capacity at low cost. The performance of an HSS highly depends on the effectiveness of two key policies: (1) the data-placement policy, which determines the best-fit storage device for incoming data, and (2) the data-migration policy, which rearranges stored data across the devices to sustain high HSS performance. Prior works focus on improving only data placement or only data migration in HSS, which leads to sub-optimal HSS performance. Unfortunately, no prior work tries to optimize both policies together. Our goal is to design a holistic data-management technique for HSS that optimizes both data-placement and data-migration policies to fully exploit the potential of an HSS. We propose Harmonia, a multi-agent reinforcement learning (RL)-based data-management technique that employs two light-weight autonomous RL agents, a data-placement agent and a data-migration agent, which adapt their policies for the current workload and HSS configuration, and coordinate with each other to improve overall HSS performance. We evaluate Harmonia on a real HSS with up to four heterogeneous storage devices with diverse characteristics. Our evaluation using 17 data-intensive workloads on performance-optimized (cost-optimized) HSS with two storage devices shows that, on average, Harmonia (1) outperforms the best-performing prior approach by 49.5% (31.7%), (2) bridges the performance gap between the best-performing prior work and Oracle by 64.2% (64.3%). On an HSS with three (four) devices, Harmonia outperforms the best-performing prior work by 37.0% (42.0%). Harmonia's performance benefits come with low latency (240ns for inference) and storage overheads (206 KiB for both RL agents together). We plan to open-source Harmonia's implementation to aid future research on HSS.
Sibyl: Adaptive and Extensible Data Placement in Hybrid Storage Systems Using Online Reinforcement Learning
May 15, 2022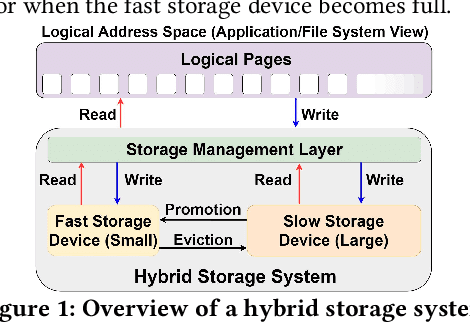

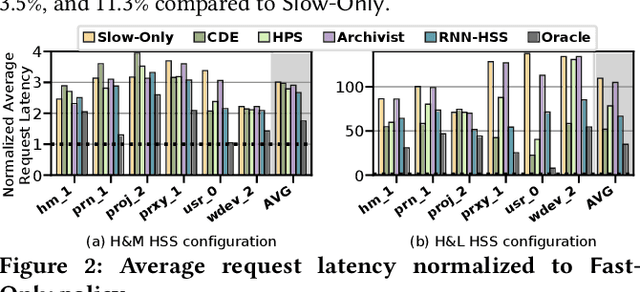
Hybrid storage systems (HSS) use multiple different storage devices to provide high and scalable storage capacity at high performance. Recent research proposes various techniques that aim to accurately identify performance-critical data to place it in a "best-fit" storage device. Unfortunately, most of these techniques are rigid, which (1) limits their adaptivity to perform well for a wide range of workloads and storage device configurations, and (2) makes it difficult for designers to extend these techniques to different storage system configurations (e.g., with a different number or different types of storage devices) than the configuration they are designed for. We introduce Sibyl, the first technique that uses reinforcement learning for data placement in hybrid storage systems. Sibyl observes different features of the running workload as well as the storage devices to make system-aware data placement decisions. For every decision it makes, Sibyl receives a reward from the system that it uses to evaluate the long-term performance impact of its decision and continuously optimizes its data placement policy online. We implement Sibyl on real systems with various HSS configurations. Our results show that Sibyl provides 21.6%/19.9% performance improvement in a performance-oriented/cost-oriented HSS configuration compared to the best previous data placement technique. Our evaluation using an HSS configuration with three different storage devices shows that Sibyl outperforms the state-of-the-art data placement policy by 23.9%-48.2%, while significantly reducing the system architect's burden in designing a data placement mechanism that can simultaneously incorporate three storage devices. We show that Sibyl achieves 80% of the performance of an oracle policy that has complete knowledge of future access patterns while incurring a very modest storage overhead of only 124.4 KiB.
Pythia: A Customizable Hardware Prefetching Framework Using Online Reinforcement Learning
Oct 19, 2021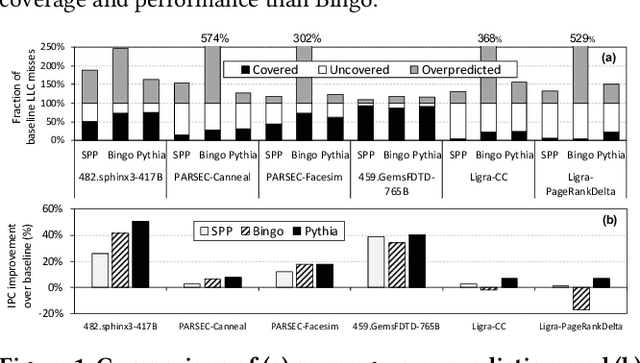
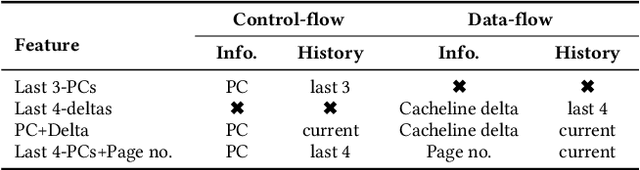

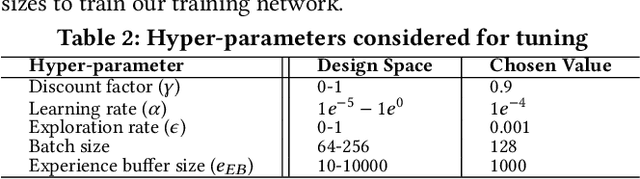
Past research has proposed numerous hardware prefetching techniques, most of which rely on exploiting one specific type of program context information (e.g., program counter, cacheline address) to predict future memory accesses. These techniques either completely neglect a prefetcher's undesirable effects (e.g., memory bandwidth usage) on the overall system, or incorporate system-level feedback as an afterthought to a system-unaware prefetch algorithm. We show that prior prefetchers often lose their performance benefit over a wide range of workloads and system configurations due to their inherent inability to take multiple different types of program context and system-level feedback information into account while prefetching. In this paper, we make a case for designing a holistic prefetch algorithm that learns to prefetch using multiple different types of program context and system-level feedback information inherent to its design. To this end, we propose Pythia, which formulates the prefetcher as a reinforcement learning agent. For every demand request, Pythia observes multiple different types of program context information to make a prefetch decision. For every prefetch decision, Pythia receives a numerical reward that evaluates prefetch quality under the current memory bandwidth usage. Pythia uses this reward to reinforce the correlation between program context information and prefetch decision to generate highly accurate, timely, and system-aware prefetch requests in the future. Our extensive evaluations using simulation and hardware synthesis show that Pythia outperforms multiple state-of-the-art prefetchers over a wide range of workloads and system configurations, while incurring only 1.03% area overhead over a desktop-class processor and no software changes in workloads. The source code of Pythia can be freely downloaded from https://github.com/CMU-SAFARI/Pythia.