 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LUT-based Deep Neural Networks Inference through Architecture and Connectivity Optimization
Jan 14, 2026Deploying deep neural networks (DNNs) on resource-constrained edge devices such as FPGAs requires a careful balance among latency, power, and hardware resource usage, while maintaining high accuracy. Existing Lookup Table (LUT)-based DNNs -- such as LogicNets, PolyLUT, and NeuraLUT -- face two critical challenges: the exponential growth of LUT size and inefficient random sparse connectivity. This paper presents SparseLUT, a comprehensive framework that addresses these challenges through two orthogonal optimizations. First, we propose an architectural enhancement that aggregates multiple PolyLUT sub-neurons via an adder, significantly reducing LUT consumption by 2.0x-13.9x and lowering inference latency by 1.2x-1.6x, all while maintaining comparable accuracy. Building upon this foundation, we further introduce a non-greedy training algorithm that optimizes neuron connectivity by selectively pruning less significant inputs and strategically regrowing more effective ones. This training optimization, which incurs no additional area and latency overhead, delivers consistent accuracy improvements across benchmarks -- achieving up to a 2.13% gain on MNIST and 0.94% on Jet Substructure Classification compared to existing LUT-DNN approaches.
* arXiv admin note: substantial text overlap with arXiv:2503.12829, arXiv:2406.04910
SparseLUT: Sparse Connectivity Optimization for Lookup Table-based Deep Neural Networks
Mar 17, 2025



The deployment of deep neural networks (DNNs) on resource-constrained edge devices such as field-programmable gate arrays (FPGAs) requires a careful balance of latency, power, and resource usage while maintaining high accuracy. Existing Lookup Table (LUT)-based DNNs, including LogicNets, PolyLUT, PolyLUT-Add, and NeuraLUT, exploit native FPGA resources with random sparse connectivity. This paper introduces SparseLUT, a connectivity-centric training technique tailored for LUT-based DNNs. SparseLUT leverages a non-greedy training strategy that prioritizes the pruning of less significant connections and strategically regrows alternative ones, resulting in efficient convergence to the target sparsity. Experimental results show consistent accuracy improvements across benchmarks, including up to a 2.13\% increase on MNIST and a 0.94\% improvement for Jet Substructure Classification compared to random sparsity. This is done without any hardware overhead and achieves state-of-the-art results for LUT-based DNNs.
Accuracy to Throughput Trade-offs for Reduced Precision Neural Networks on Reconfigurable Logic
Jul 17, 2018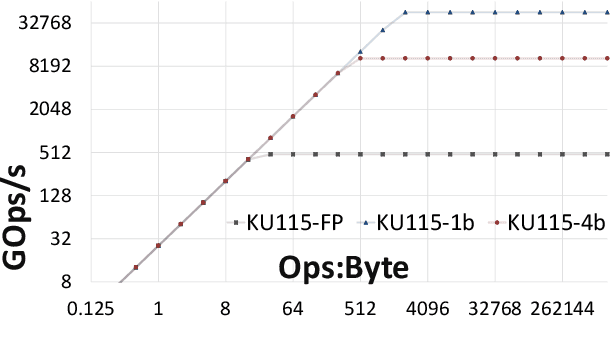
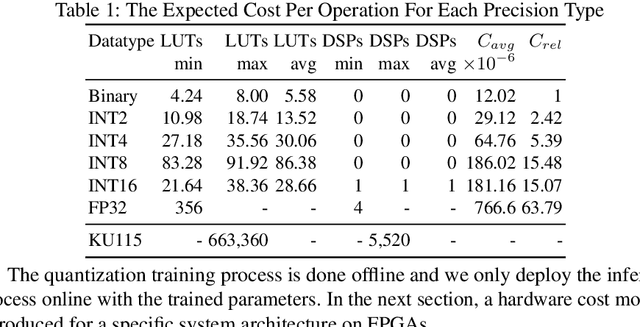

Modern CNN are typically based on floating point linear algebra based implementations. Recently, reduced precision NN have been gaining popularity as they require significantly less memory and computational resources compared to floating point. This is particularly important in power constrained compute environments. However, in many cases a reduction in precision comes at a small cost to the accuracy of the resultant network. In this work, we investigate the accuracy-throughput trade-off for various parameter precision applied to different types of NN models. We firstly propose a quantization training strategy that allows reduced precision NN inference with a lower memory footprint and competitive model accuracy. Then, we quantitatively formulate the relationship between data representation and hardware efficiency. Our experiments finally provide insightful observation. For example, one of our tests show 32-bit floating point is more hardware efficient than 1-bit parameters to achieve 99% MNIST accuracy. In general, 2-bit and 4-bit fixed point parameters show better hardware trade-off on small-scale datasets like MNIST and CIFAR-10 while 4-bit provide the best trade-off in large-scale tasks like AlexNet on ImageNet dataset within our tested problem domain.
Scaling Binarized Neural Networks on Reconfigurable Logic
Jan 27, 2017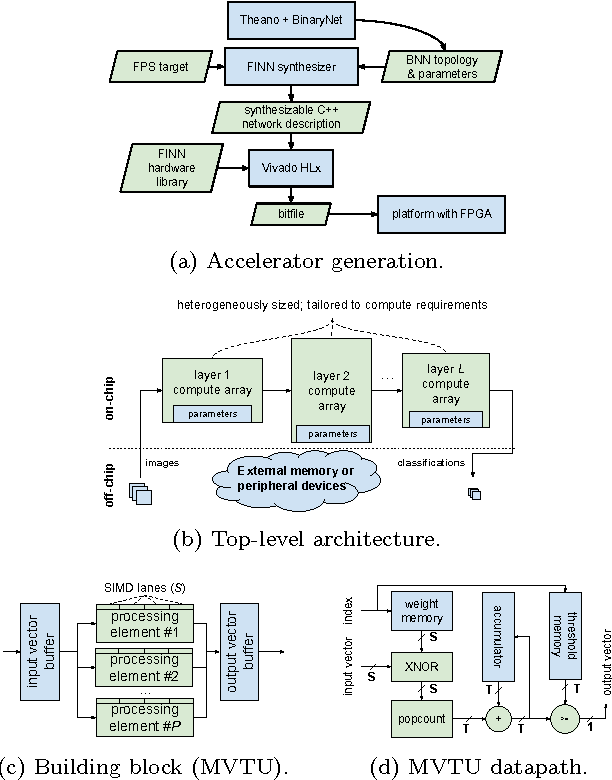

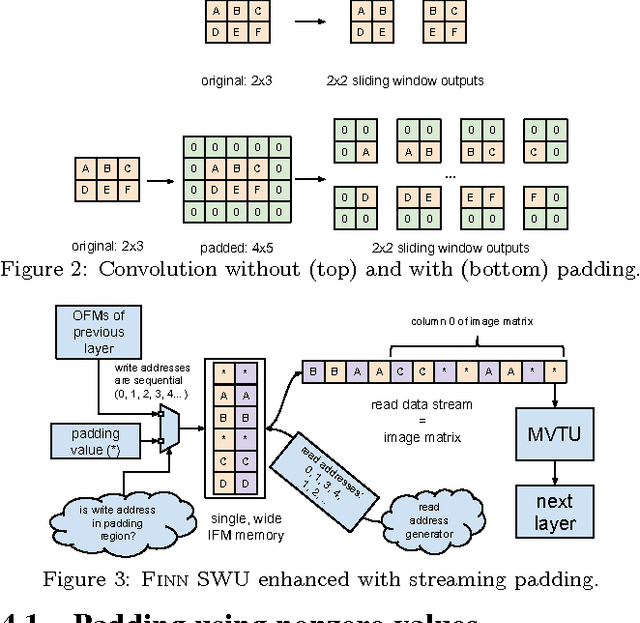
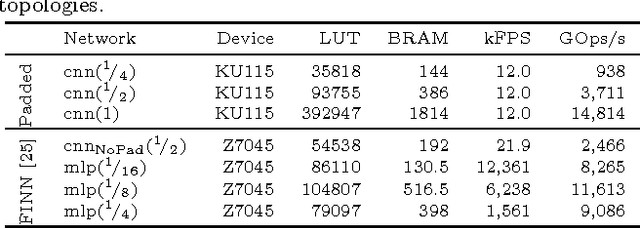
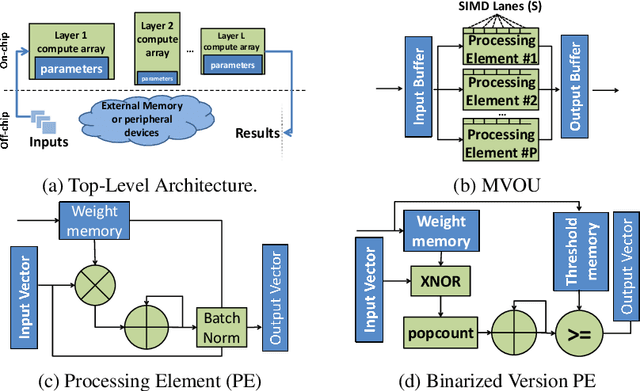
Binarized neural networks (BNNs) are gaining interest in the deep learning community due to their significantly lower computational and memory cost. They are particularly well suited to reconfigurable logic devices, which contain an abundance of fine-grained compute resources and can result in smaller, lower power implementations, or conversely in higher classification rates. Towards this end, the Finn framework was recently proposed for building fast and flexible field programmable gate array (FPGA) accelerators for BNNs. Finn utilized a novel set of optimizations that enable efficient mapping of BNNs to hardware and implemented fully connected, non-padded convolutional and pooling layers, with per-layer compute resources being tailored to user-provided throughput requirements. However, FINN was not evaluated on larger topologies due to the size of the chosen FPGA, and exhibited decreased accuracy due to lack of padding. In this paper, we improve upon Finn to show how padding can be employed on BNNs while still maintaining a 1-bit datapath and high accuracy. Based on this technique, we demonstrate numerous experiments to illustrate flexibility and scalability of the approach. In particular, we show that a large BNN requiring 1.2 billion operations per frame running on an ADM-PCIE-8K5 platform can classify images at 12 kFPS with 671 us latency while drawing less than 41 W board power and classifying CIFAR-10 images at 88.7% accuracy. Our implementation of this network achieves 14.8 trillion operations per second. We believe this is the fastest classification rate reported to date on this benchmark at this level of accuracy.
FINN: A Framework for Fast, Scalable Binarized Neural Network Inference
Dec 01, 2016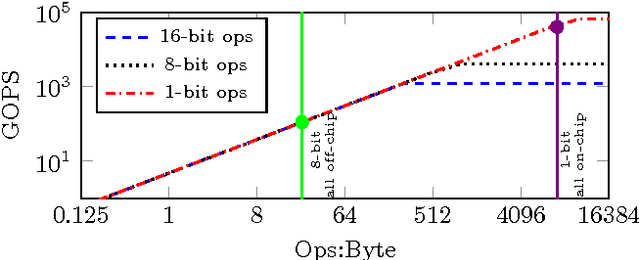

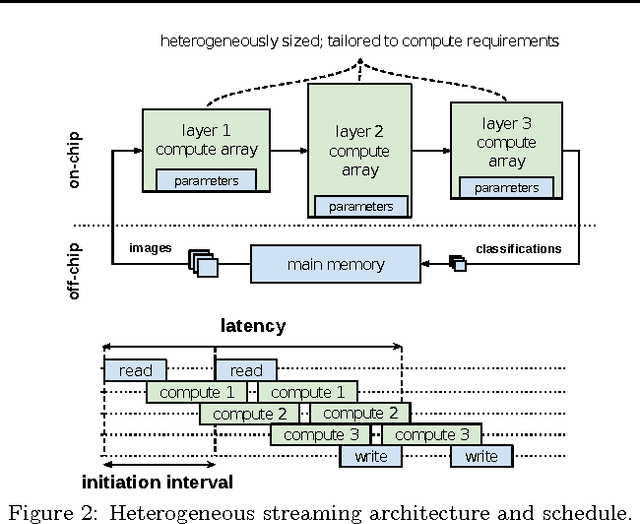
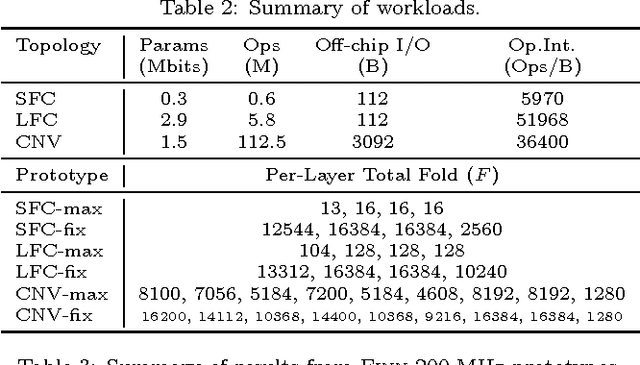
Research has shown that convolutional neural networks contain significant redundancy, and high classification accuracy can be obtained even when weights and activations are reduced from floating point to binary values. In this paper, we present FINN, a framework for building fast and flexible FPGA accelerators using a flexible heterogeneous streaming architecture. By utilizing a novel set of optimizations that enable efficient mapping of binarized neural networks to hardware, we implement fully connected, convolutional and pooling layers, with per-layer compute resources being tailored to user-provided throughput requirements. On a ZC706 embedded FPGA platform drawing less than 25 W total system power, we demonstrate up to 12.3 million image classifications per second with 0.31 {\mu}s latency on the MNIST dataset with 95.8% accuracy, and 21906 image classifications per second with 283 {\mu}s latency on the CIFAR-10 and SVHN datasets with respectively 80.1% and 94.9% accuracy. To the best of our knowledge, ours are the fastest classification rates reported to date on these benchmarks.
Feature Graph Architectures
Dec 15, 2013

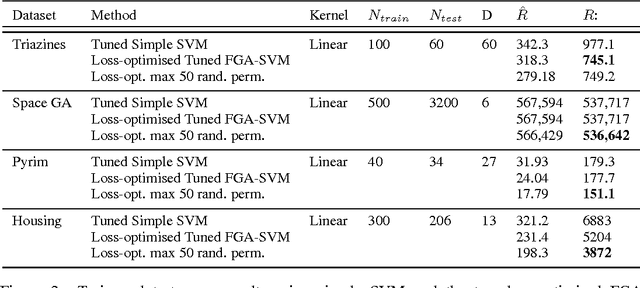
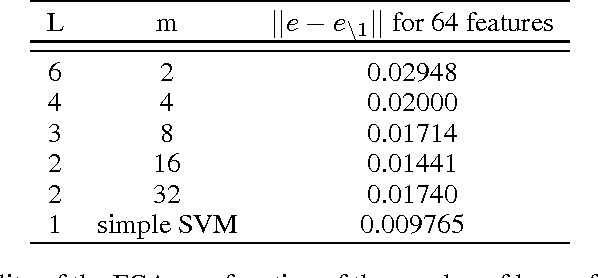
In this article we propose feature graph architectures (FGA), which are deep learning systems employing a structured initialisation and training method based on a feature graph which facilitates improved generalisation performance compared with a standard shallow architecture. The goal is to explore alternative perspectives on the problem of deep network training. We evaluate FGA performance for deep SVMs on some experimental datasets, and show how generalisation and stability results may be derived for these models. We describe the effect of permutations on the model accuracy, and give a criterion for the optimal permutation in terms of feature correlations. The experimental results show that the algorithm produces robust and significant test set improvements over a standard shallow SVM training method for a range of datasets. These gains are achieved with a moderate increase in time complexity.