 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAT: Training Neural Networks for Reliable Inference Under Hardware Faults
Paper and Code
Nov 11, 2020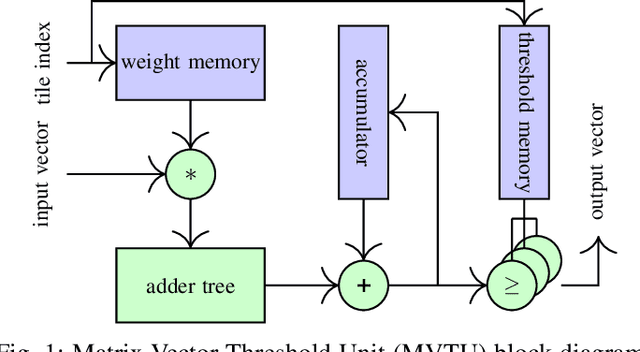
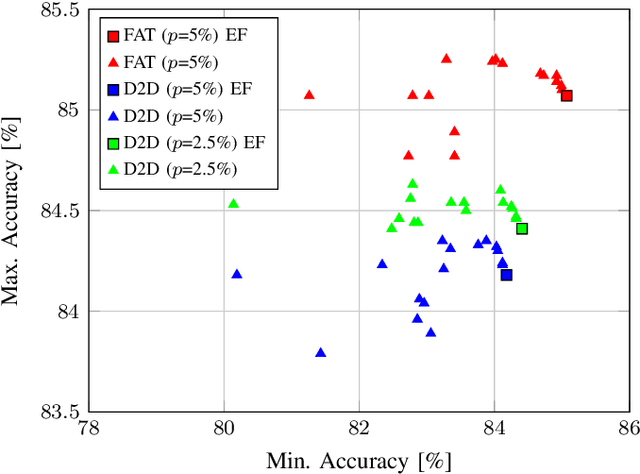
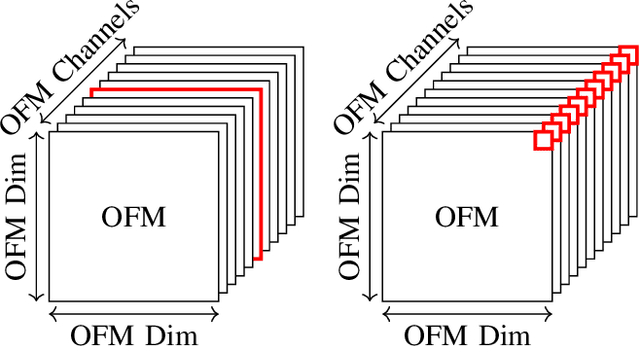
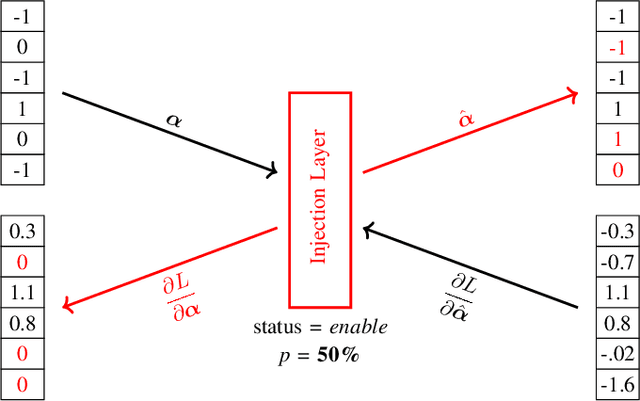
Deep neural networks (DNNs) are state-of-the-art algorithms for multiple applications, spanning from image classification to speech recognition. While providing excellent accuracy, they often have enormous compute and memory requirements. As a result of this, quantized neural networks (QNNs) are increasingly being adopted and deployed especially on embedded devices, thanks to their high accuracy, but also since they have significantly lower compute and memory requirements compared to their floating point equivalents. QNN deployment is also being evaluated for safety-critical applications, such as automotive, avionics, medical or industrial. These systems require functional safety, guaranteeing failure-free behaviour even in the presence of hardware faults. In general fault tolerance can be achieved by adding redundancy to the system, which further exacerbates the overall computational demands and makes it difficult to meet the power and performance requirements. In order to decrease the hardware cost for achieving functional safety, it is vital to explore domain-specific solutions which can exploit the inherent features of DNNs. In this work we present a novel methodology called fault-aware training (FAT), which includes error modeling during neural network (NN) training, to make QNNs resilient to specific fault models on the device. Our experiments show that by injecting faults in the convolutional layers during training, highly accurate convolutional neural networks (CNNs) can be trained which exhibits much better error tolerance compared to the original. Furthermore, we show that redundant systems which are built from QNNs trained with FAT achieve higher worse-case accuracy at lower hardware cost. This has been validated for numerous classification tasks including CIFAR10, GTSRB, SVHN and ImageNet.