 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Error-Tolerant Quantized Neural Network Accelerators
Dec 16, 2019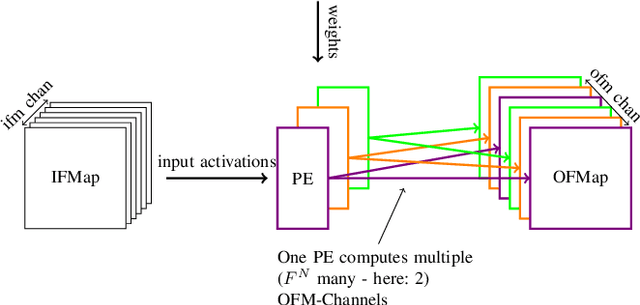
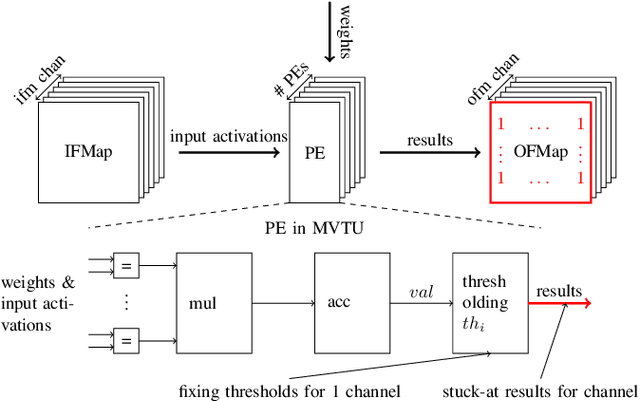
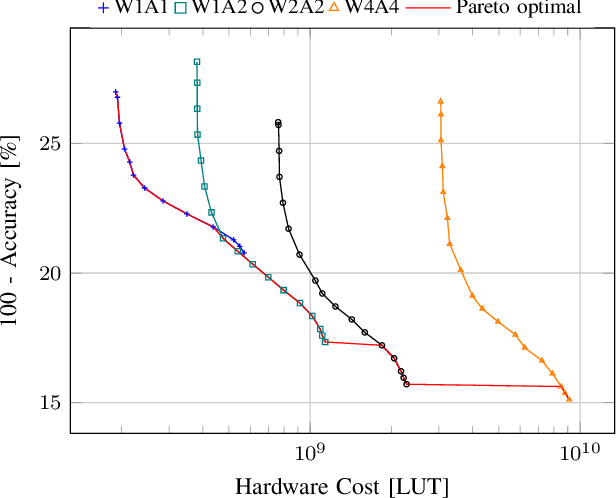
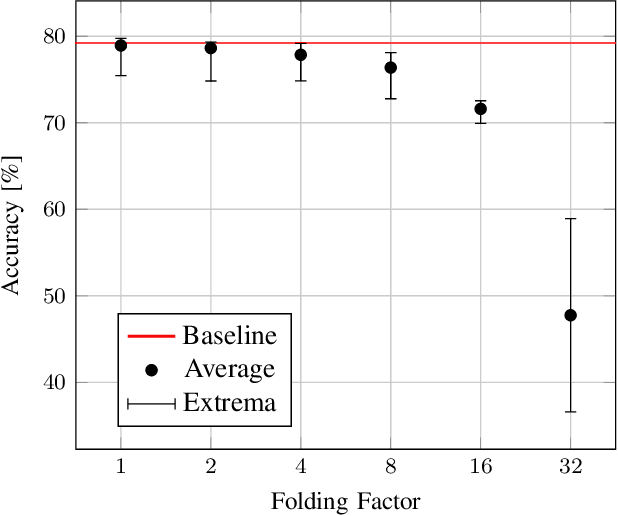
Neural Networks are currently one of the most widely deployed machine learning algorithms. In particular, Convolutional Neural Networks (CNNs), are gaining popularity and are evaluated for deployment in safety critical applications such as self driving vehicles. Modern CNNs feature enormous memory bandwidth and high computational needs, challenging existing hardware platforms to meet throughput, latency and power requirements. Functional safety and error tolerance need to be considered as additional requirement in safety critical systems. In general, fault tolerant operation can be achieved by adding redundancy to the system, which is further exacerbating the computational demands. Furthermore, the question arises whether pruning and quantization methods for performance scaling turn out to be counterproductive with regards to fail safety requirements. In this work we present a methodology to evaluate the impact of permanent faults affecting Quantized Neural Networks (QNNs) and how to effectively decrease their effects in hardware accelerators. We use FPGA-based hardware accelerated error injection, in order to enable the fast evaluation. A detailed analysis is presented showing that QNNs containing convolutional layers are by far not as robust to faults as commonly believed and can lead to accuracy drops of up to 10%. To circumvent that, we propose two different methods to increase their robustness: 1) selective channel replication which adds significantly less redundancy than used by the common triple modular redundancy and 2) a fault-aware scheduling of processing elements for folded implementations
* 6 pages, 5 figures
AddNet: Deep Neural Networks Using FPGA-Optimized Multipliers
Nov 19, 2019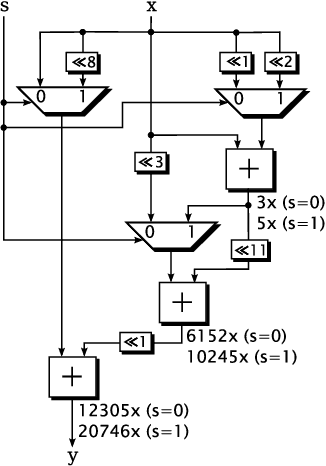
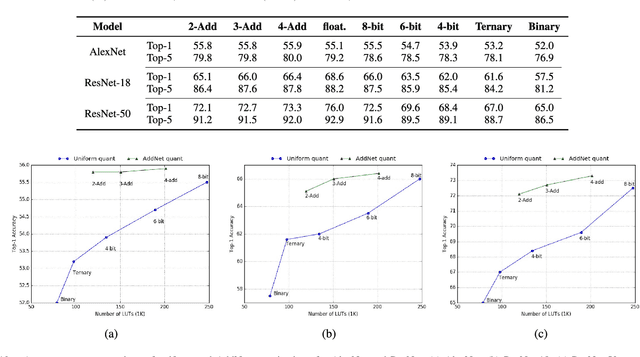
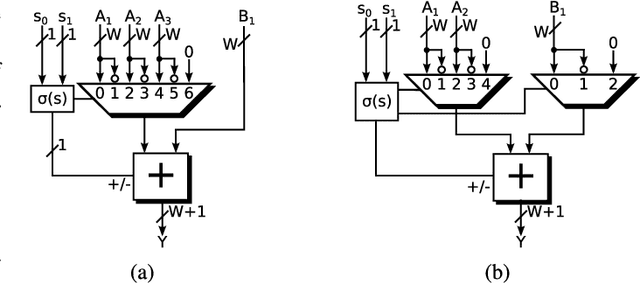
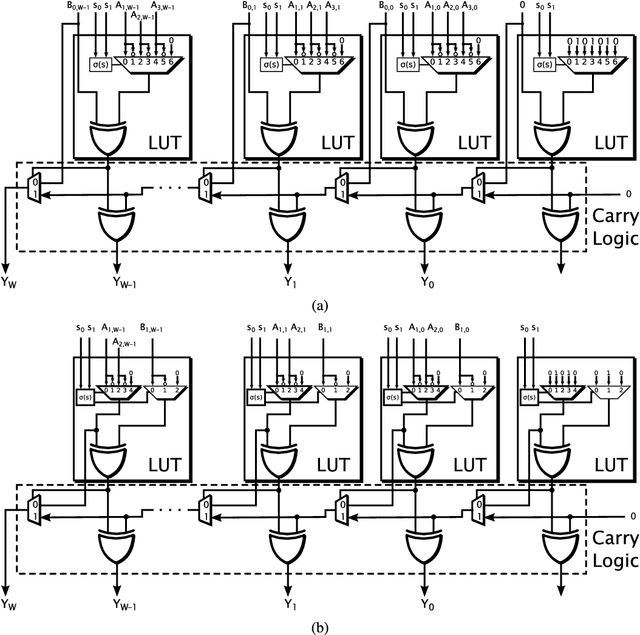
Low-precision arithmetic operations to accelerate deep-learning applications on field-programmable gate arrays (FPGAs) have been studied extensively, because they offer the potential to save silicon area or increase throughput. However, these benefits come at the cost of a decrease in accuracy. In this article, we demonstrate that reconfigurable constant coefficient multipliers (RCCMs) offer a better alternative for saving the silicon area than utilizing low-precision arithmetic. RCCMs multiply input values by a restricted choice of coefficients using only adders, subtractors, bit shifts, and multiplexers (MUXes), meaning that they can be heavily optimized for FPGAs. We propose a family of RCCMs tailored to FPGA logic elements to ensure their efficient utilization. To minimize information loss from quantization, we then develop novel training techniques that map the possible coefficient representations of the RCCMs to neural network weight parameter distributions. This enables the usage of the RCCMs in hardware, while maintaining high accuracy. We demonstrate the benefits of these techniques using AlexNet, ResNet-18, and ResNet-50 networks. The resulting implementations achieve up to 50% resource savings over traditional 8-bit quantized networks, translating to significant speedups and power savings. Our RCCM with the lowest resource requirements exceeds 6-bit fixed point accuracy, while all other implementations with RCCMs achieve at least similar accuracy to an 8-bit uniformly quantized design, while achieving significant resource savings.
Unrolling Ternary Neural Networks
Sep 09, 2019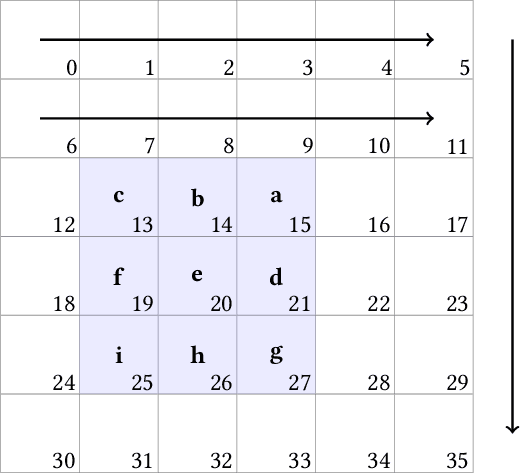
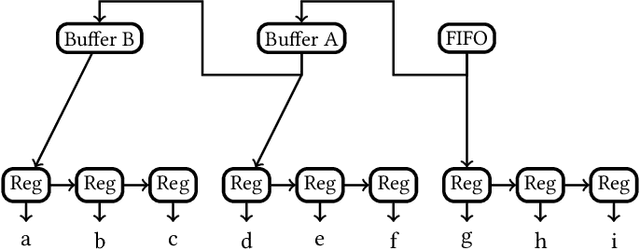
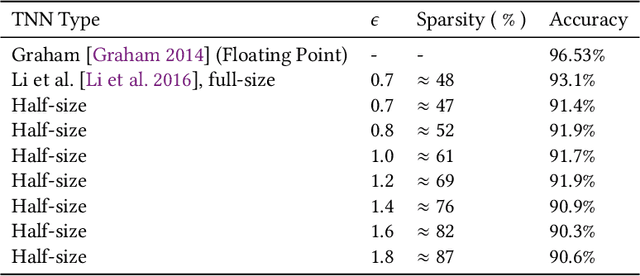
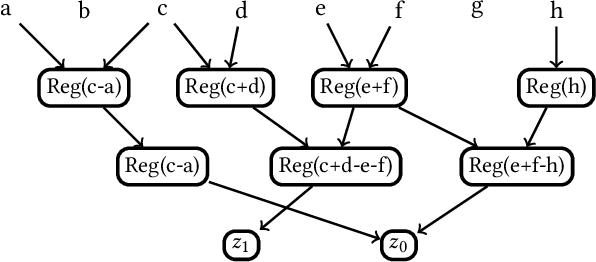
The computational complexity of neural networks for large scale or real-time applications necessitates hardware acceleration. Most approaches assume that the network architecture and parameters are unknown at design time, permitting usage in a large number of applications. This paper demonstrates, for the case where the neural network architecture and ternary weight values are known a priori, that extremely high throughput implementations of neural network inference can be made by customising the datapath and routing to remove unnecessary computations and data movement. This approach is ideally suited to FPGA implementations as a specialized implementation of a trained network improves efficiency while still retaining generality with the reconfigurability of an FPGA. A VGG style network with ternary weights and fixed point activations is implemented for the CIFAR10 dataset on Amazon's AWS F1 instance. This paper demonstrates how to remove 90% of the operations in convolutional layers by exploiting sparsity and compile-time optimizations. The implementation in hardware achieves 90.9 +/- 0.1% accuracy and 122 k frames per second, with a latency of only 29 us, which is the fastest CNN inference implementation reported so far on an FPGA.