 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgefSEAD: a Composable FPGA-based Streaming Ensemble Anomaly Detection Library
Jun 10, 2024



Machine learning ensembles combine multiple base models to produce a more accurate output. They can be applied to a range of machine learning problems, including anomaly detection. In this paper, we investigate how to maximize the composability and scalability of an FPGA-based streaming ensemble anomaly detector (fSEAD). To achieve this, we propose a flexible computing architecture consisting of multiple partially reconfigurable regions, pblocks, which each implement anomaly detectors. Our proof-of-concept design supports three state-of-the-art anomaly detection algorithms: Loda, RS-Hash and xStream. Each algorithm is scalable, meaning multiple instances can be placed within a pblock to improve performance. Moreover, fSEAD is implemented using High-level synthesis (HLS), meaning further custom anomaly detectors can be supported. Pblocks are interconnected via an AXI-switch, enabling them to be composed in an arbitrary fashion before combining and merging results at run-time to create an ensemble that maximizes the use of FPGA resources and accuracy. Through utilizing reconfigurable Dynamic Function eXchange (DFX), the detector can be modified at run-time to adapt to changing environmental conditions. We compare fSEAD to an equivalent central processing unit (CPU) implementation using four standard datasets, with speed-ups ranging from $3\times$ to $8\times$.
* The source code for this paper is available at: https://github.com/bingleilou/fSEAD
PolyLUT-Add: FPGA-based LUT Inference with Wide Inputs
Jun 07, 2024



FPGAs have distinct advantages as a technology for deploying deep neural networks (DNNs) at the edge. Lookup Table (LUT) based networks, where neurons are directly modelled using LUTs, help maximize this promise of offering ultra-low latency and high area efficiency on FPGAs. Unfortunately, LUT resource usage scales exponentially with the number of inputs to the LUT, restricting PolyLUT to small LUT sizes. This work introduces PolyLUT-Add, a technique that enhances neuron connectivity by combining $A$ PolyLUT sub-neurons via addition to improve accuracy. Moreover, we describe a novel architecture to improve its scalability. We evaluated our implementation over the MNIST, Jet Substructure classification and Network Intrusion Detection benchmark and found that for similar accuracy, PolyLUT-Add achieves a LUT reduction of $1.3-7.7\times$ with a $1.2-2.2\times$ decrease in latency.
The Wyner Variational Autoencoder for Unsupervised Multi-Layer Wireless Fingerprinting
Mar 28, 2023



Wireless fingerprinting refers to a device identification method leveraging hardware imperfections and wireless channel variations as signatures. Beyond physical layer characteristics, recent studies demonstrated that user behaviours could be identified through network traffic, e.g., packet length, without decryption of the payload. Inspired by these results, we propose a multi-layer fingerprinting framework that jointly considers the multi-layer signatures for improved identification performance. In contrast to previous works, by leveraging the recent multi-view machine learning paradigm, i.e., data with multiple forms, our method can cluster the device information shared among the multi-layer features without supervision. Our information-theoretic approach can be extended to supervised and semi-supervised settings with straightforward derivations. In solving the formulated problem, we obtain a tight surrogate bound using variational inference for efficient optimization. In extracting the shared device information, we develop an algorithm based on the Wyner common information method, enjoying reduced computation complexity as compared to existing approaches. The algorithm can be applied to data distributions belonging to the exponential family class. Empirically, we evaluate the algorithm in a synthetic dataset with real-world video traffic and simulated physical layer characteristics. Our empirical results show that the proposed method outperforms the state-of-the-art baselines in both supervised and unsupervised settings.
NITI: Training Integer Neural Networks Using Integer-only Arithmetic
Sep 28, 2020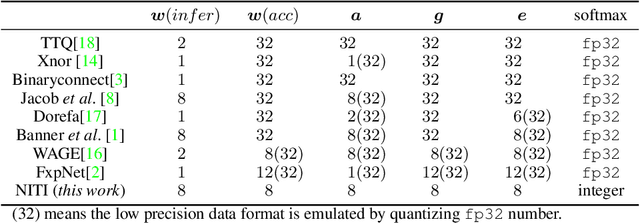
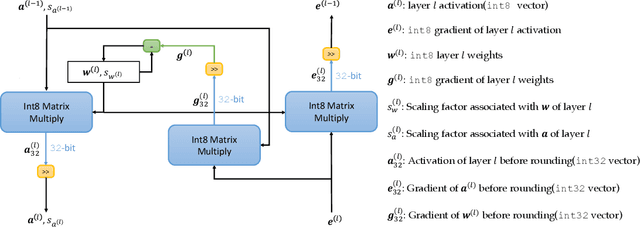
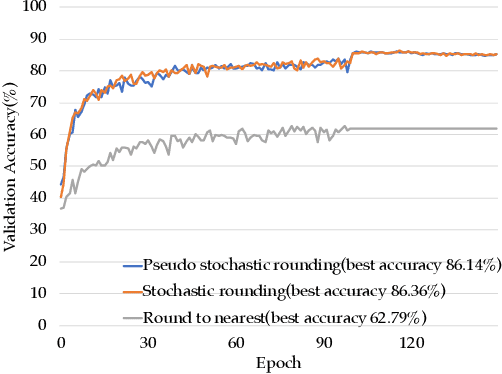

While integer arithmetic has been widely adopted for improved performance in deep quantized neural network inference, training remains a task primarily executed using floating point arithmetic. This is because both high dynamic range and numerical accuracy are central to the success of most modern training algorithms. However, due to its potential for computational, storage and energy advantages in hardware accelerators, neural network training methods that can be implemented with low precision integer-only arithmetic remains an active research challenge. In this paper, we present NITI, an efficient deep neural network training framework that stores all parameters and intermediate values as integers, and computes exclusively with integer arithmetic. A pseudo stochastic rounding scheme that eliminates the need for external random number generation is proposed to facilitate conversion from wider intermediate results to low precision storage. Furthermore, a cross-entropy loss backpropagation scheme computed with integer-only arithmetic is proposed. A proof-of-concept open-source software implementation of NITI that utilizes native 8-bit integer operations in modern GPUs to achieve end-to-end training is presented. When compared with an equivalent training setup implemented with floating point storage and arithmetic, NITI achieves negligible accuracy degradation on the MNIST and CIFAR10 datasets using 8-bit integer storage and computation. On ImageNet, 16-bit integers are needed for weight accumulation with an 8-bit datapath. This achieves training results comparable to all-floating-point implementations.
MajorityNets: BNNs Utilising Approximate Popcount for Improved Efficiency
Feb 27, 2020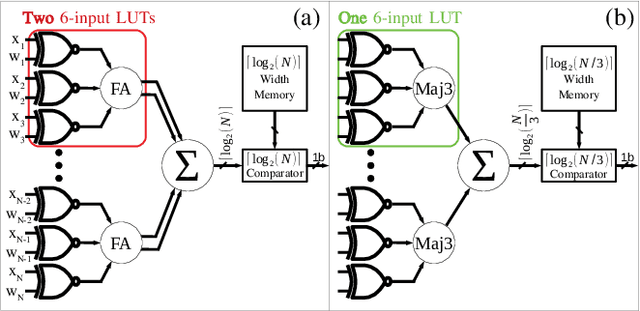
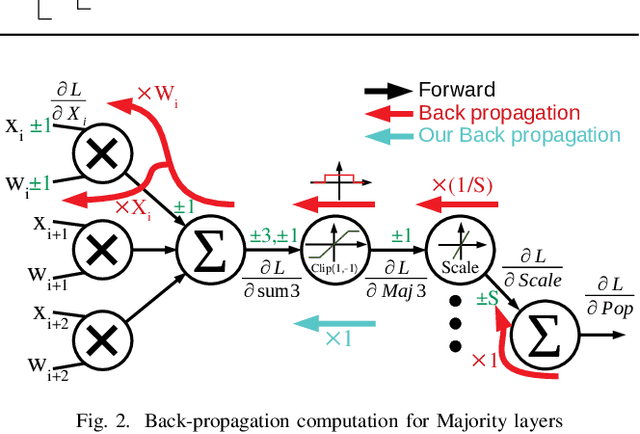
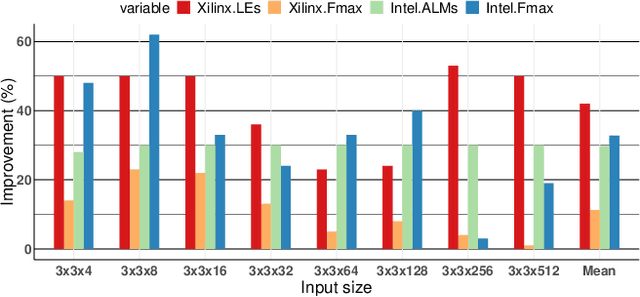
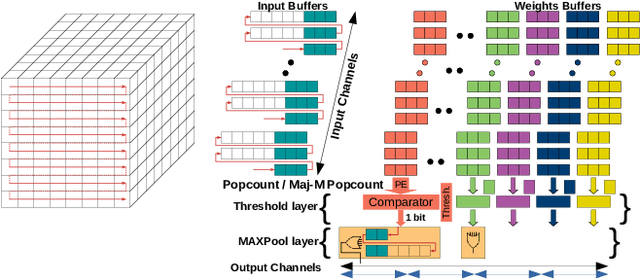
Binarized neural networks (BNNs) have shown exciting potential for utilising neural networks in embedded implementations where area, energy and latency constraints are paramount. With BNNs, multiply-accumulate (MAC) operations can be simplified to XnorPopcount operations, leading to massive reductions in both memory and computation resources. Furthermore, multiple efficient implementations of BNNs have been reported on field-programmable gate array (FPGA) implementations. This paper proposes a smaller, faster, more energy-efficient approximate replacement for the XnorPopcountoperation, called XNorMaj, inspired by state-of-the-art FPGAlook-up table schemes which benefit FPGA implementations. Weshow that XNorMaj is up to 2x more resource-efficient than the XnorPopcount operation. While the XNorMaj operation has a minor detrimental impact on accuracy, the resource savings enable us to use larger networks to recover the loss.
* 4 pages
AddNet: Deep Neural Networks Using FPGA-Optimized Multipliers
Nov 19, 2019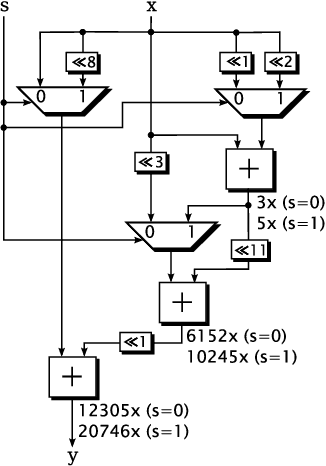
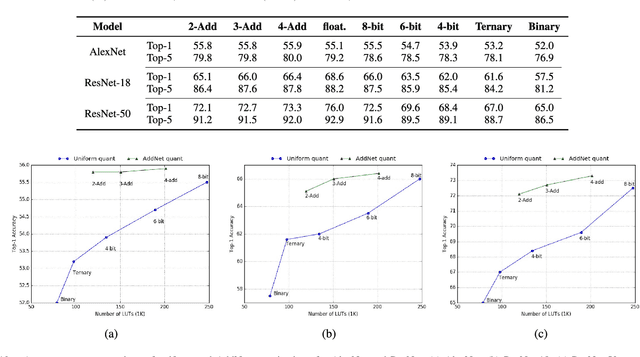
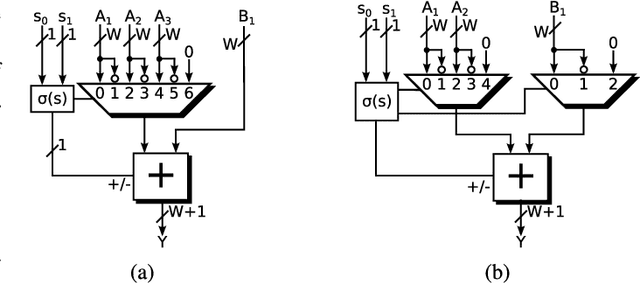
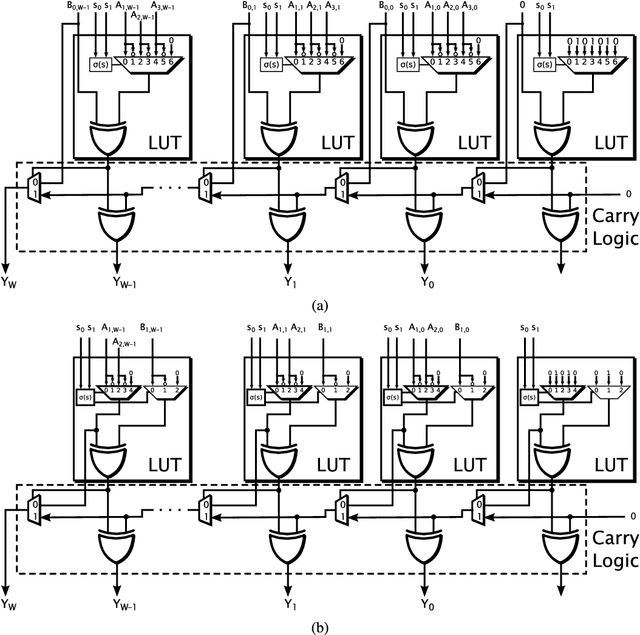
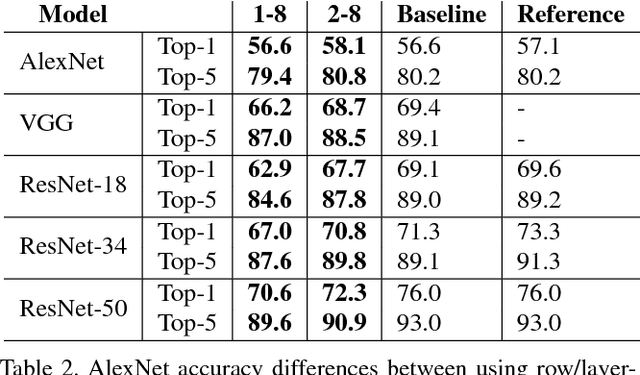
Low-precision arithmetic operations to accelerate deep-learning applications on field-programmable gate arrays (FPGAs) have been studied extensively, because they offer the potential to save silicon area or increase throughput. However, these benefits come at the cost of a decrease in accuracy. In this article, we demonstrate that reconfigurable constant coefficient multipliers (RCCMs) offer a better alternative for saving the silicon area than utilizing low-precision arithmetic. RCCMs multiply input values by a restricted choice of coefficients using only adders, subtractors, bit shifts, and multiplexers (MUXes), meaning that they can be heavily optimized for FPGAs. We propose a family of RCCMs tailored to FPGA logic elements to ensure their efficient utilization. To minimize information loss from quantization, we then develop novel training techniques that map the possible coefficient representations of the RCCMs to neural network weight parameter distributions. This enables the usage of the RCCMs in hardware, while maintaining high accuracy. We demonstrate the benefits of these techniques using AlexNet, ResNet-18, and ResNet-50 networks. The resulting implementations achieve up to 50% resource savings over traditional 8-bit quantized networks, translating to significant speedups and power savings. Our RCCM with the lowest resource requirements exceeds 6-bit fixed point accuracy, while all other implementations with RCCMs achieve at least similar accuracy to an 8-bit uniformly quantized design, while achieving significant resource savings.
Unrolling Ternary Neural Networks
Sep 09, 2019
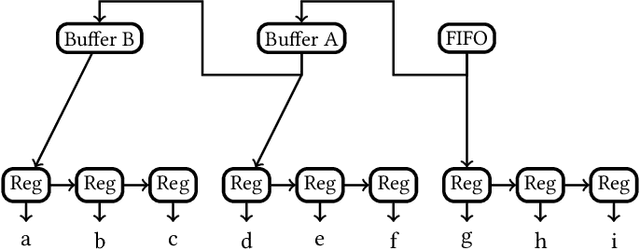
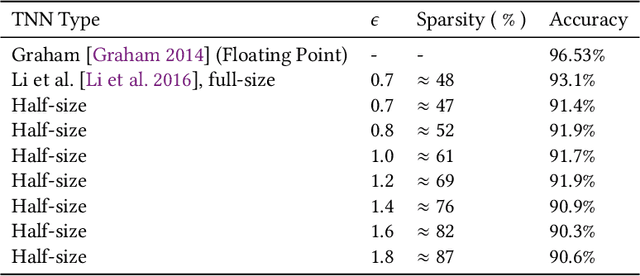
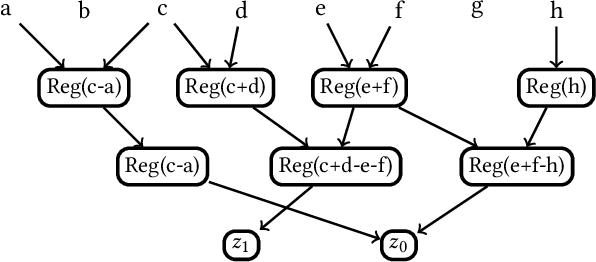
The computational complexity of neural networks for large scale or real-time applications necessitates hardware acceleration. Most approaches assume that the network architecture and parameters are unknown at design time, permitting usage in a large number of applications. This paper demonstrates, for the case where the neural network architecture and ternary weight values are known a priori, that extremely high throughput implementations of neural network inference can be made by customising the datapath and routing to remove unnecessary computations and data movement. This approach is ideally suited to FPGA implementations as a specialized implementation of a trained network improves efficiency while still retaining generality with the reconfigurability of an FPGA. A VGG style network with ternary weights and fixed point activations is implemented for the CIFAR10 dataset on Amazon's AWS F1 instance. This paper demonstrates how to remove 90% of the operations in convolutional layers by exploiting sparsity and compile-time optimizations. The implementation in hardware achieves 90.9 +/- 0.1% accuracy and 122 k frames per second, with a latency of only 29 us, which is the fastest CNN inference implementation reported so far on an FPGA.
SYQ: Learning Symmetric Quantization For Efficient Deep Neural Networks
Jul 01, 2018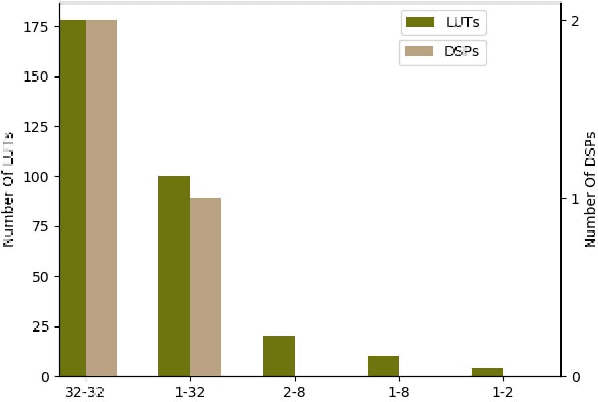
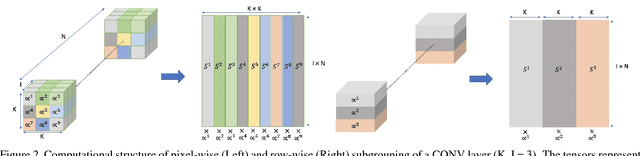
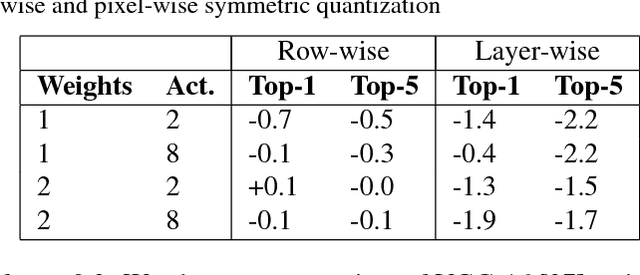
Inference for state-of-the-art deep neural networks is computationally expensive, making them difficult to deploy on constrained hardware environments. An efficient way to reduce this complexity is to quantize the weight parameters and/or activations during training by approximating their distributions with a limited entry codebook. For very low-precisions, such as binary or ternary networks with 1-8-bit activations, the information loss from quantization leads to significant accuracy degradation due to large gradient mismatches between the forward and backward functions. In this paper, we introduce a quantization method to reduce this loss by learning a symmetric codebook for particular weight subgroups. These subgroups are determined based on their locality in the weight matrix, such that the hardware simplicity of the low-precision representations is preserved. Empirically, we show that symmetric quantization can substantially improve accuracy for networks with extremely low-precision weights and activations. We also demonstrate that this representation imposes minimal or no hardware implications to more coarse-grained approaches. Source code is available at https://www.github.com/julianfaraone/SYQ.
Compressing Low Precision Deep Neural Networks Using Sparsity-Induced Regularization in Ternary Networks
Oct 10, 2017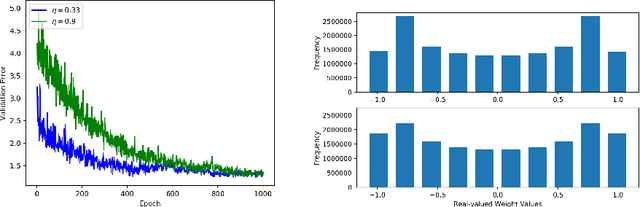
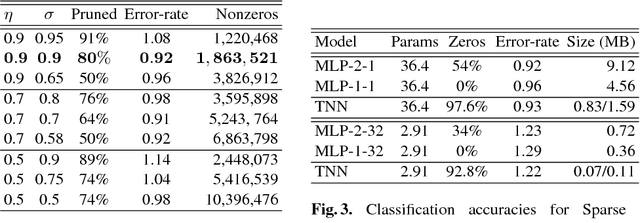
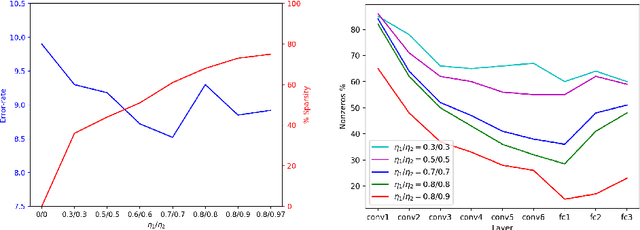
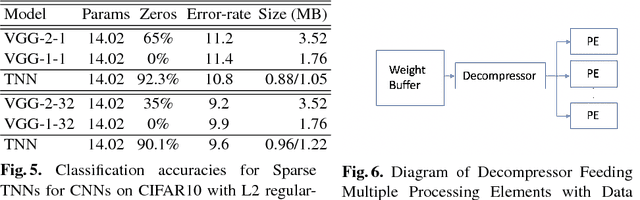
A low precision deep neural network training technique for producing sparse, ternary neural networks is presented. The technique incorporates hard- ware implementation costs during training to achieve significant model compression for inference. Training involves three stages: network training using L2 regularization and a quantization threshold regularizer, quantization pruning, and finally retraining. Resulting networks achieve improved accuracy, reduced memory footprint and reduced computational complexity compared with conventional methods, on MNIST and CIFAR10 datasets. Our networks are up to 98% sparse and 5 & 11 times smaller than equivalent binary and ternary models, translating to significant resource and speed benefits for hardware implementations.