 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Open-source End-to-End Logic Optimization Framework for Large-scale Boolean Network with Reinforcement Learning
Mar 26, 2024



We propose an open-source end-to-end logic optimization framework for large-scale boolean network with reinforcement learning.
Multi-view Inverse Rendering for Large-scale Real-world Indoor Scenes
Nov 22, 2022



We present a multi-view inverse rendering method for large-scale real-world indoor scenes that reconstructs global illumination and physically-reasonable SVBRDFs. Unlike previous representations, where the global illumination of large scenes is simplified as multiple environment maps, we propose a compact representation called Texture-based Lighting (TBL). It consists of 3D meshs and HDR textures, and efficiently models direct and infinite-bounce indirect lighting of the entire large scene. Based on TBL, we further propose a hybrid lighting representation with precomputed irradiance, which significantly improves the efficiency and alleviate the rendering noise in the material optimization. To physically disentangle the ambiguity between materials, we propose a three-stage material optimization strategy based on the priors of semantic segmentation and room segmentation. Extensive experiments show that the proposed method outperforms the state-of-the-arts quantitatively and qualitatively, and enables physically-reasonable mixed-reality applications such as material editing, editable novel view synthesis and relighting. The project page is at https://lzleejean.github.io/IRTex.
Low Error-Rate Approximate Multiplier Design for DNNs with Hardware-Driven Co-Optimization
Oct 08, 2022
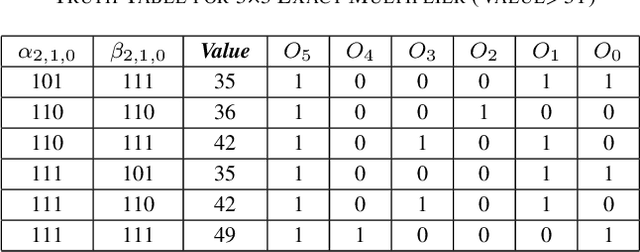
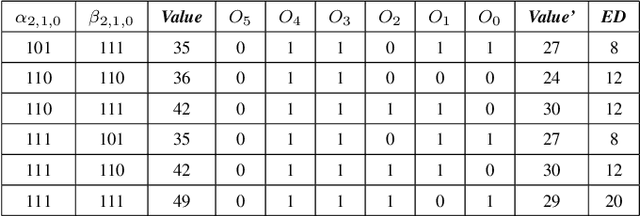
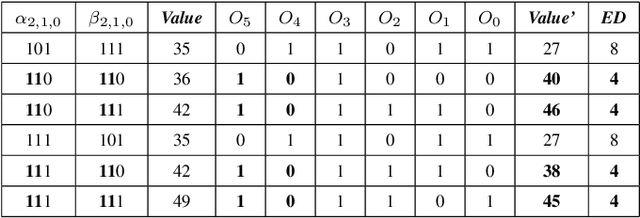
In this paper, two approximate 3*3 multipliers are proposed and the synthesis results of the ASAP-7nm process library justify that they can reduce the area by 31.38% and 36.17%, and the power consumption by 36.73% and 35.66% compared with the exact multiplier, respectively. They can be aggregated with a 2*2 multiplier to produce an 8*8 multiplier with low error rate based on the distribution of DNN weights. We propose a hardware-driven software co-optimization method to improve the DNN accuracy by retraining. Based on the proposed two approximate 3-bit multipliers, three approximate 8-bit multipliers with low error-rate are designed for DNNs. Compared with the exact 8-bit unsigned multiplier, our design can achieve a significant advantage over other approximate multipliers on the public dataset.
HEAM: High-Efficiency Approximate Multiplier Optimization for Deep Neural Networks
Jan 25, 2022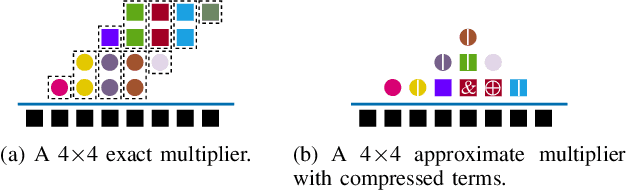

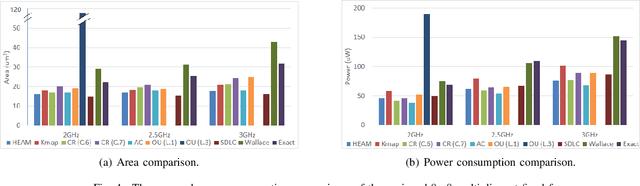

We propose an optimization method for the automatic design of approximate multipliers, which minimizes the average error according to the operand distributions. Our multiplier achieves up to 50.24% higher accuracy than the best reproduced approximate multiplier in DNNs, with 15.76% smaller area, 25.05% less power consumption, and 3.50% shorter delay. Compared with an exact multiplier, our multiplier reduces the area, power consumption, and delay by 44.94%, 47.63%, and 16.78%, respectively, with negligible accuracy losses. The tested DNN accelerator modules with our multiplier obtain up to 18.70% smaller area and 9.99% less power consumption than the original modules.
MajorityNets: BNNs Utilising Approximate Popcount for Improved Efficiency
Feb 27, 2020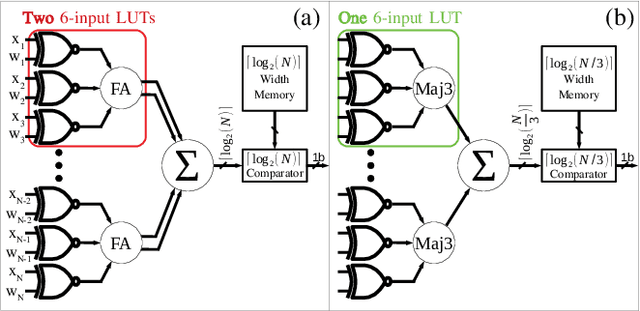
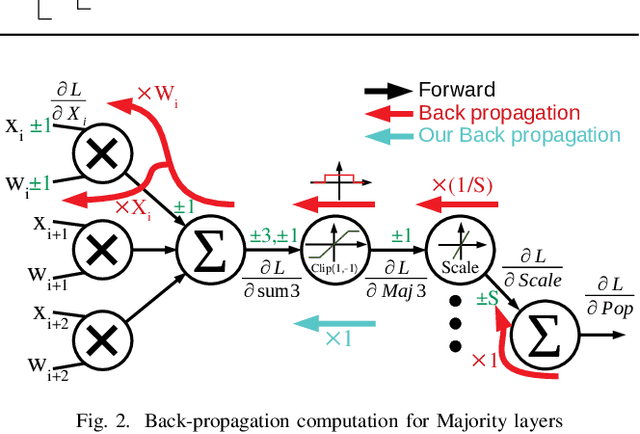
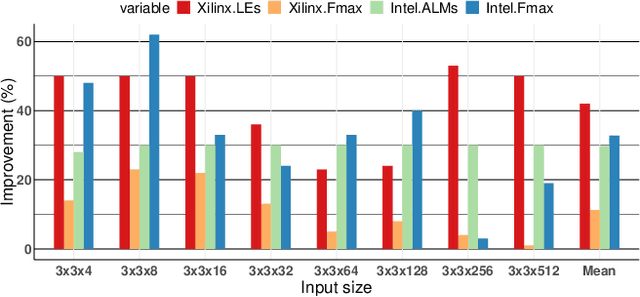
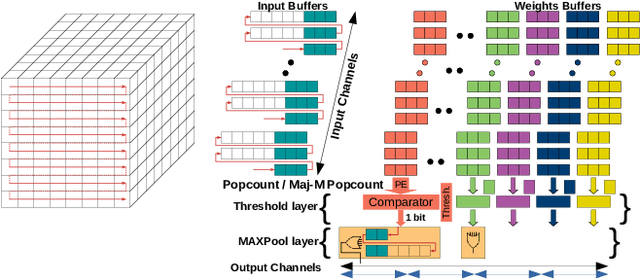
Binarized neural networks (BNNs) have shown exciting potential for utilising neural networks in embedded implementations where area, energy and latency constraints are paramount. With BNNs, multiply-accumulate (MAC) operations can be simplified to XnorPopcount operations, leading to massive reductions in both memory and computation resources. Furthermore, multiple efficient implementations of BNNs have been reported on field-programmable gate array (FPGA) implementations. This paper proposes a smaller, faster, more energy-efficient approximate replacement for the XnorPopcountoperation, called XNorMaj, inspired by state-of-the-art FPGAlook-up table schemes which benefit FPGA implementations. Weshow that XNorMaj is up to 2x more resource-efficient than the XnorPopcount operation. While the XNorMaj operation has a minor detrimental impact on accuracy, the resource savings enable us to use larger networks to recover the loss.
* 4 pages