 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplications and Techniques for Fast Machine Learning in Science
Oct 25, 2021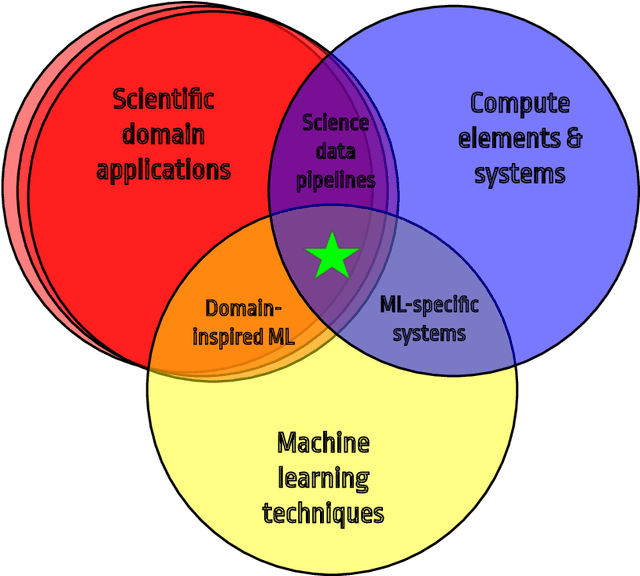
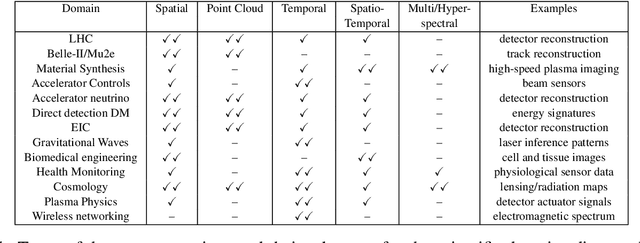
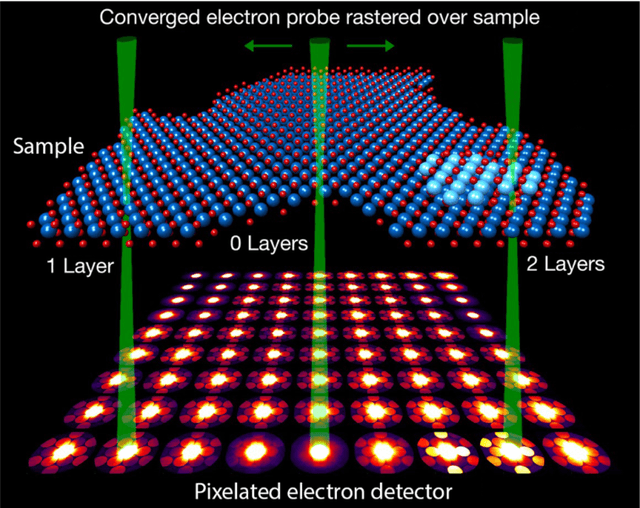
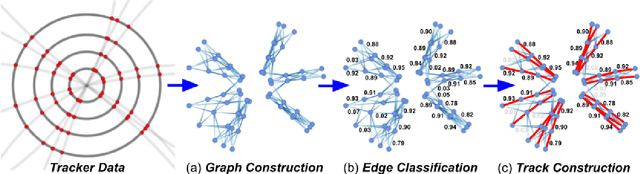
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.
NITI: Training Integer Neural Networks Using Integer-only Arithmetic
Sep 28, 2020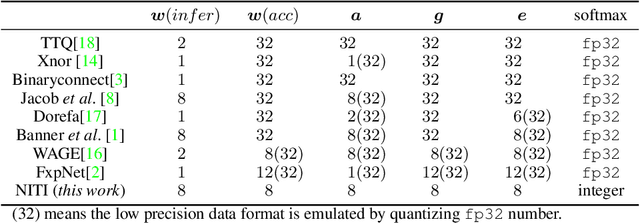
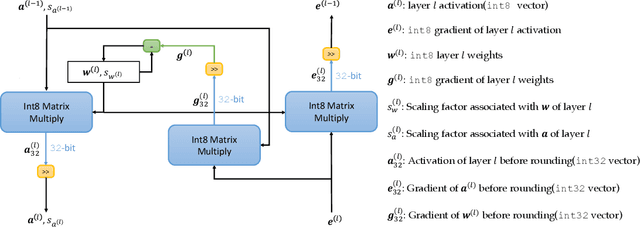
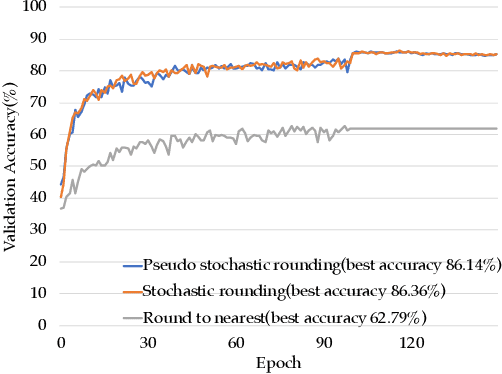

While integer arithmetic has been widely adopted for improved performance in deep quantized neural network inference, training remains a task primarily executed using floating point arithmetic. This is because both high dynamic range and numerical accuracy are central to the success of most modern training algorithms. However, due to its potential for computational, storage and energy advantages in hardware accelerators, neural network training methods that can be implemented with low precision integer-only arithmetic remains an active research challenge. In this paper, we present NITI, an efficient deep neural network training framework that stores all parameters and intermediate values as integers, and computes exclusively with integer arithmetic. A pseudo stochastic rounding scheme that eliminates the need for external random number generation is proposed to facilitate conversion from wider intermediate results to low precision storage. Furthermore, a cross-entropy loss backpropagation scheme computed with integer-only arithmetic is proposed. A proof-of-concept open-source software implementation of NITI that utilizes native 8-bit integer operations in modern GPUs to achieve end-to-end training is presented. When compared with an equivalent training setup implemented with floating point storage and arithmetic, NITI achieves negligible accuracy degradation on the MNIST and CIFAR10 datasets using 8-bit integer storage and computation. On ImageNet, 16-bit integers are needed for weight accumulation with an 8-bit datapath. This achieves training results comparable to all-floating-point implementations.
MajorityNets: BNNs Utilising Approximate Popcount for Improved Efficiency
Feb 27, 2020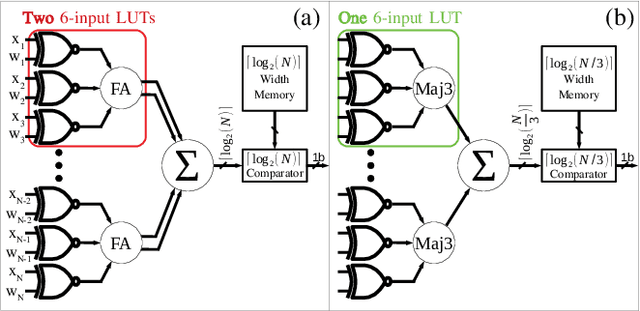
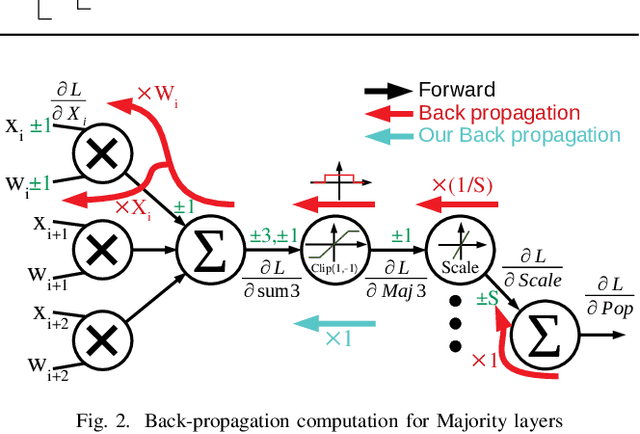
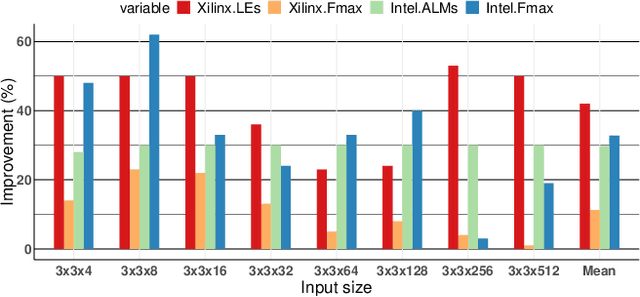
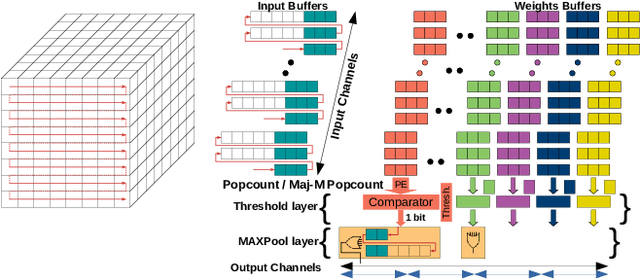
Binarized neural networks (BNNs) have shown exciting potential for utilising neural networks in embedded implementations where area, energy and latency constraints are paramount. With BNNs, multiply-accumulate (MAC) operations can be simplified to XnorPopcount operations, leading to massive reductions in both memory and computation resources. Furthermore, multiple efficient implementations of BNNs have been reported on field-programmable gate array (FPGA) implementations. This paper proposes a smaller, faster, more energy-efficient approximate replacement for the XnorPopcountoperation, called XNorMaj, inspired by state-of-the-art FPGAlook-up table schemes which benefit FPGA implementations. Weshow that XNorMaj is up to 2x more resource-efficient than the XnorPopcount operation. While the XNorMaj operation has a minor detrimental impact on accuracy, the resource savings enable us to use larger networks to recover the loss.
* 4 pages