 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss Landscape Analysis for Reliable Quantized ML Models for Scientific Sensing
Feb 12, 2025In this paper, we propose a method to perform empirical analysis of the loss landscape of machine learning (ML) models. The method is applied to two ML models for scientific sensing, which necessitates quantization to be deployed and are subject to noise and perturbations due to experimental conditions. Our method allows assessing the robustness of ML models to such effects as a function of quantization precision and under different regularization techniques -- two crucial concerns that remained underexplored so far. By investigating the interplay between performance, efficiency, and robustness by means of loss landscape analysis, we both established a strong correlation between gently-shaped landscapes and robustness to input and weight perturbations and observed other intriguing and non-obvious phenomena. Our method allows a systematic exploration of such trade-offs a priori, i.e., without training and testing multiple models, leading to more efficient development workflows. This work also highlights the importance of incorporating robustness into the Pareto optimization of ML models, enabling more reliable and adaptive scientific sensing systems.
End-to-end workflow for machine learning-based qubit readout with QICK and hls4ml
Jan 24, 2025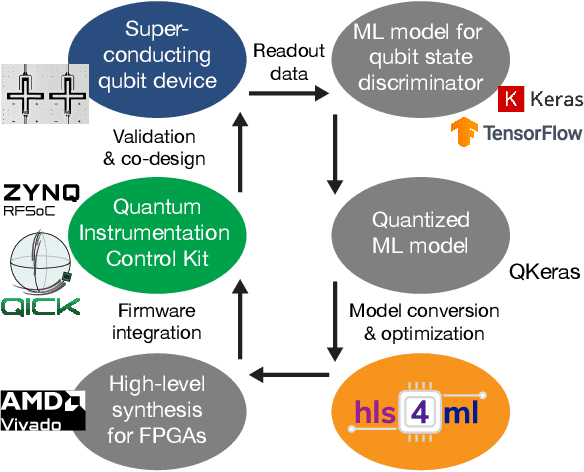
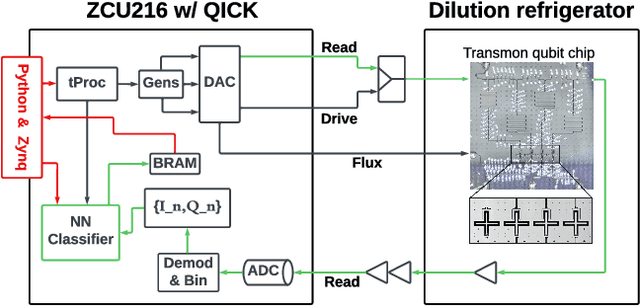
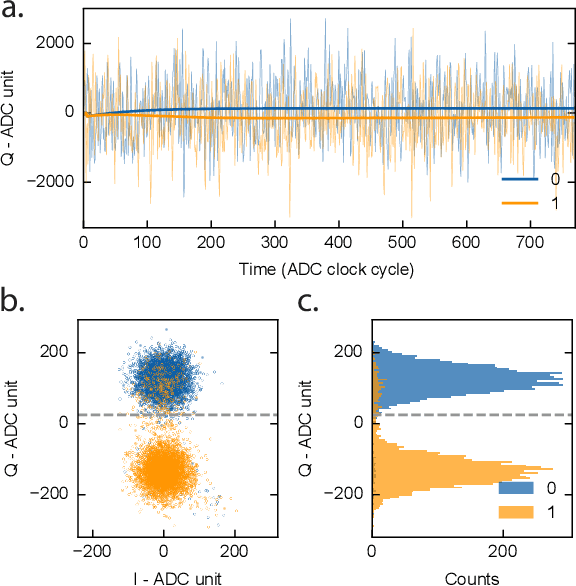

We present an end-to-end workflow for superconducting qubit readout that embeds co-designed Neural Networks (NNs) into the Quantum Instrumentation Control Kit (QICK). Capitalizing on the custom firmware and software of the QICK platform, which is built on Xilinx RFSoC FPGAs, we aim to leverage machine learning (ML) to address critical challenges in qubit readout accuracy and scalability. The workflow utilizes the hls4ml package and employs quantization-aware training to translate ML models into hardware-efficient FPGA implementations via user-friendly Python APIs. We experimentally demonstrate the design, optimization, and integration of an ML algorithm for single transmon qubit readout, achieving 96% single-shot fidelity with a latency of 32ns and less than 16% FPGA look-up table resource utilization. Our results offer the community an accessible workflow to advance ML-driven readout and adaptive control in quantum information processing applications.
Reliable edge machine learning hardware for scientific applications
Jun 27, 2024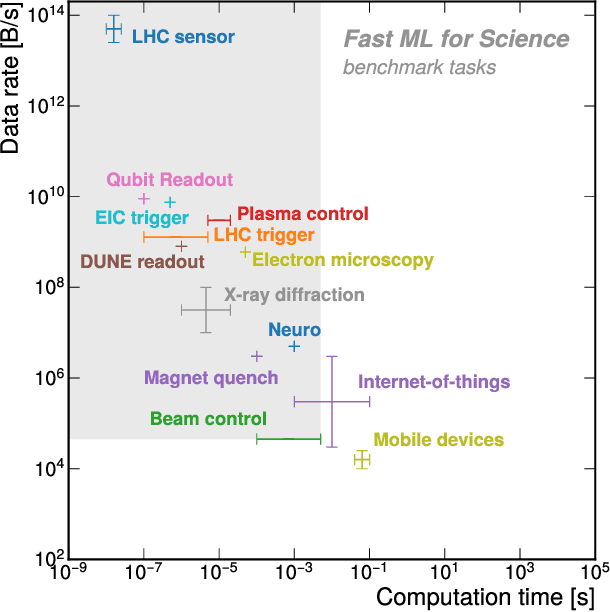
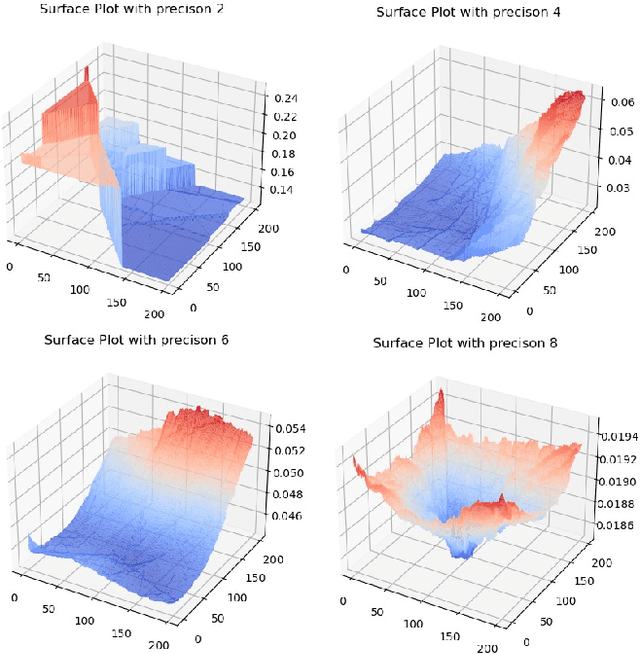
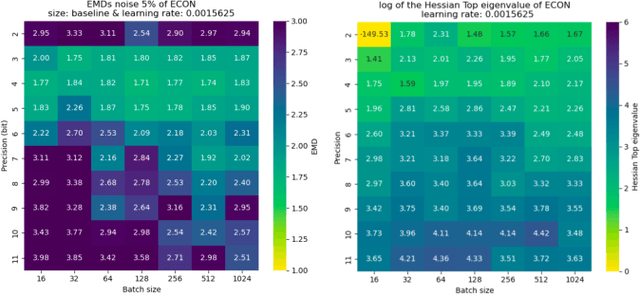
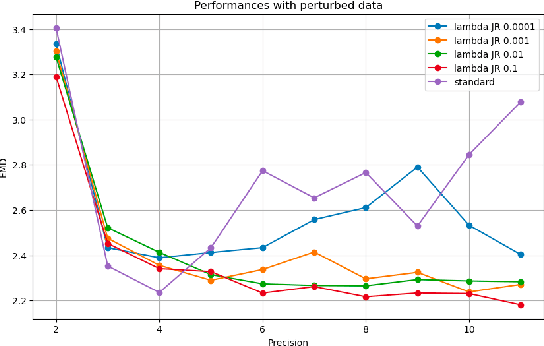
Extreme data rate scientific experiments create massive amounts of data that require efficient ML edge processing. This leads to unique validation challenges for VLSI implementations of ML algorithms: enabling bit-accurate functional simulations for performance validation in experimental software frameworks, verifying those ML models are robust under extreme quantization and pruning, and enabling ultra-fine-grained model inspection for efficient fault tolerance. We discuss approaches to developing and validating reliable algorithms at the scientific edge under such strict latency, resource, power, and area requirements in extreme experimental environments. We study metrics for developing robust algorithms, present preliminary results and mitigation strategies, and conclude with an outlook of these and future directions of research towards the longer-term goal of developing autonomous scientific experimentation methods for accelerated scientific discovery.
End-to-end codesign of Hessian-aware quantized neural networks for FPGAs and ASICs
Apr 13, 2023We develop an end-to-end workflow for the training and implementation of co-designed neural networks (NNs) for efficient field-programmable gate array (FPGA) and application-specific integrated circuit (ASIC) hardware. Our approach leverages Hessian-aware quantization (HAWQ) of NNs, the Quantized Open Neural Network Exchange (QONNX) intermediate representation, and the hls4ml tool flow for transpiling NNs into FPGA and ASIC firmware. This makes efficient NN implementations in hardware accessible to nonexperts, in a single open-sourced workflow that can be deployed for real-time machine learning applications in a wide range of scientific and industrial settings. We demonstrate the workflow in a particle physics application involving trigger decisions that must operate at the 40 MHz collision rate of the CERN Large Hadron Collider (LHC). Given the high collision rate, all data processing must be implemented on custom ASIC and FPGA hardware within a strict area and latency. Based on these constraints, we implement an optimized mixed-precision NN classifier for high-momentum particle jets in simulated LHC proton-proton collisions.