 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairedGTA: Generating Driving Datasets for Controlled Photometric Shift Analysis
May 31, 2026Evaluating the performance of visual perception systems for autonomous driving is essential to ensure reliable operation across diverse environmental scenarios. Ideally, a balanced and fair analysis across different adverse conditions would require perfectly paired images of the same scene under different weather or illumination changes. This would allow evaluating the effect of photometric shifts independently of geometry and semantic changes. Unfortunately, real-world datasets rarely provide images of the same scene under different environmental conditions, because, normally, camera pose, traffic, and locations of dynamic objects (vehicles, pedestrians, etc.) vary over time, thus yielding only coarsely paired data. To address this challenge, this work introduces a data generation framework based on a high-fidelity game engine for extracting perfectly paired images. By leveraging software APIs that communicate with the GTA game engine, the framework modifies illumination and weather conditions while preserving scene geometry, camera pose, and the identity and placement of dynamic objects. For each sampled location, it procedurally instantiates dynamic entities and renders pixel-aligned images under diverse adverse conditions. The benefit of the proposed generation framework in driving scenarios is demonstrated through a systematic analysis of semantic segmentation models, whose output degradation can be attributed more directly to photometric shifts rather than to uncontrolled semantic or geometric factors.
Exploiting Edge Features for Transferable Adversarial Attacks in Distributed Machine Learning
Jul 09, 2025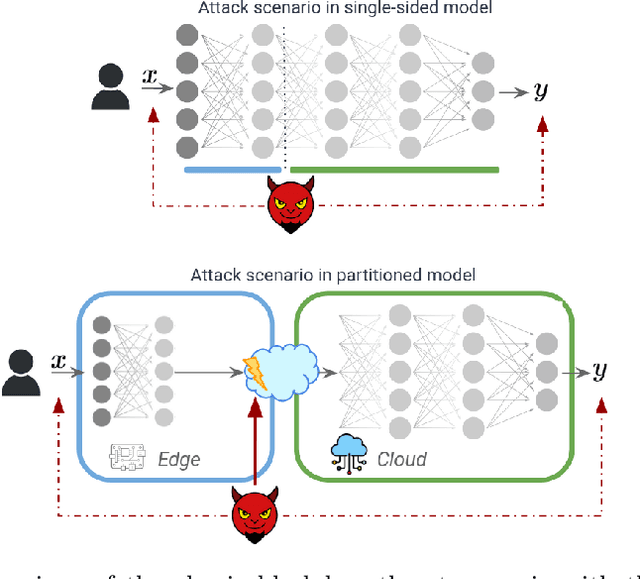
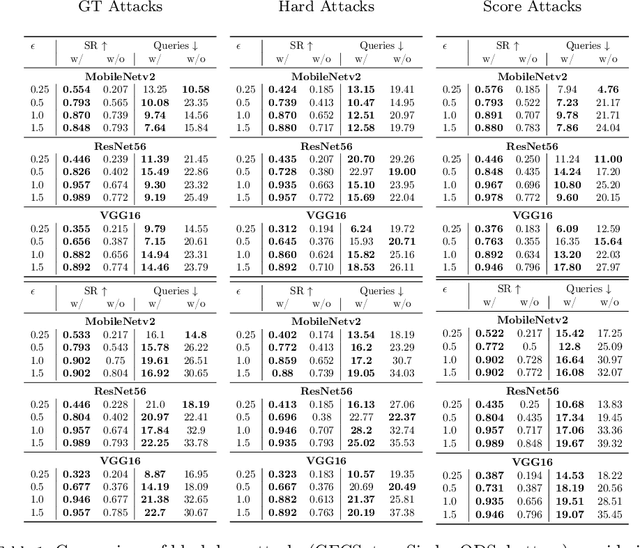
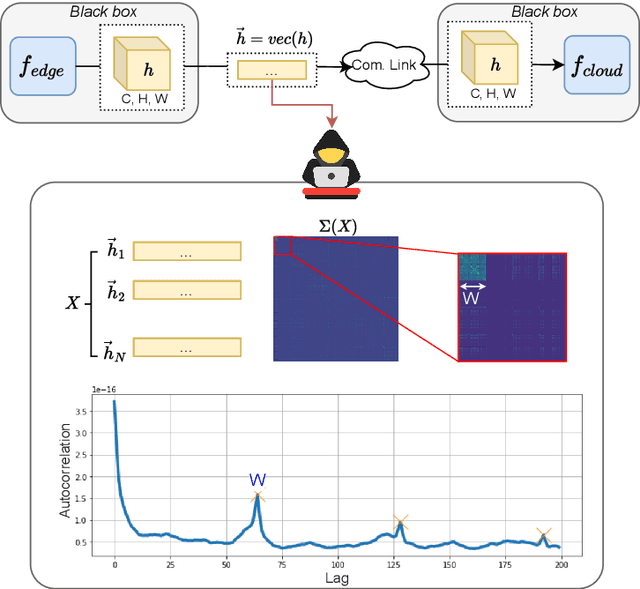
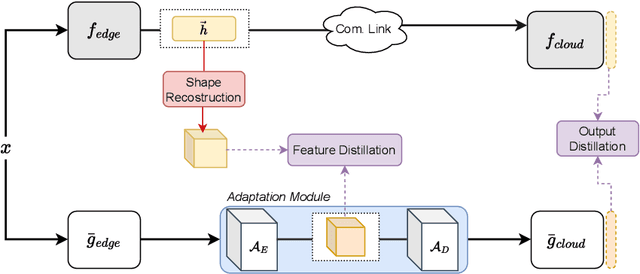
As machine learning models become increasingly deployed across the edge of internet of things environments, a partitioned deep learning paradigm in which models are split across multiple computational nodes introduces a new dimension of security risk. Unlike traditional inference setups, these distributed pipelines span the model computation across heterogeneous nodes and communication layers, thereby exposing a broader attack surface to potential adversaries. Building on these motivations, this work explores a previously overlooked vulnerability: even when both the edge and cloud components of the model are inaccessible (i.e., black-box), an adversary who intercepts the intermediate features transmitted between them can still pose a serious threat. We demonstrate that, under these mild and realistic assumptions, an attacker can craft highly transferable proxy models, making the entire deep learning system significantly more vulnerable to evasion attacks. In particular, the intercepted features can be effectively analyzed and leveraged to distill surrogate models capable of crafting highly transferable adversarial examples against the target model. To this end, we propose an exploitation strategy specifically designed for distributed settings, which involves reconstructing the original tensor shape from vectorized transmitted features using simple statistical analysis, and adapting surrogate architectures accordingly to enable effective feature distillation. A comprehensive and systematic experimental evaluation has been conducted to demonstrate that surrogate models trained with the proposed strategy, i.e., leveraging intermediate features, tremendously improve the transferability of adversarial attacks. These findings underscore the urgent need to account for intermediate feature leakage in the design of secure distributed deep learning systems.
Benchmarking the Spatial Robustness of DNNs via Natural and Adversarial Localized Corruptions
Apr 02, 2025
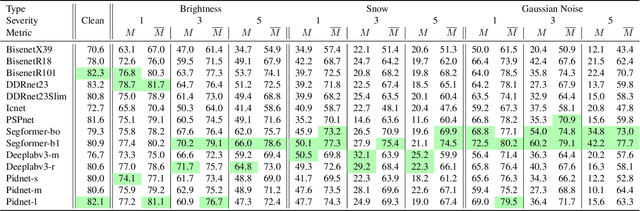
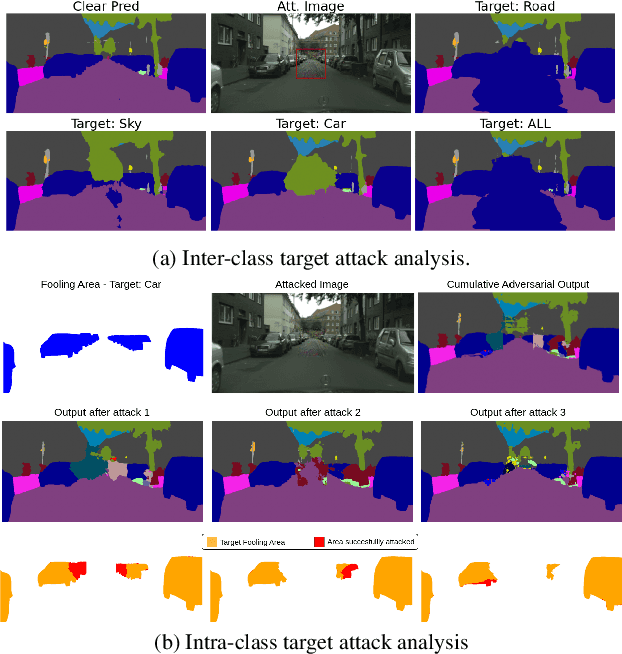

The robustness of DNNs is a crucial factor in safety-critical applications, particularly in complex and dynamic environments where localized corruptions can arise. While previous studies have evaluated the robustness of semantic segmentation (SS) models under whole-image natural or adversarial corruptions, a comprehensive investigation into the spatial robustness of dense vision models under localized corruptions remained underexplored. This paper fills this gap by introducing specialized metrics for benchmarking the spatial robustness of segmentation models, alongside with an evaluation framework to assess the impact of localized corruptions. Furthermore, we uncover the inherent complexity of characterizing worst-case robustness using a single localized adversarial perturbation. To address this, we propose region-aware multi-attack adversarial analysis, a method that enables a deeper understanding of model robustness against adversarial perturbations applied to specific regions. The proposed metrics and analysis were evaluated on 15 segmentation models in driving scenarios, uncovering key insights into the effects of localized corruption in both natural and adversarial forms. The results reveal that models respond to these two types of threats differently; for instance, transformer-based segmentation models demonstrate notable robustness to localized natural corruptions but are highly vulnerable to adversarial ones and vice-versa for CNN-based models. Consequently, we also address the challenge of balancing robustness to both natural and adversarial localized corruptions by means of ensemble models, thereby achieving a broader threat coverage and improved reliability for dense vision tasks.
Loss Landscape Analysis for Reliable Quantized ML Models for Scientific Sensing
Feb 12, 2025In this paper, we propose a method to perform empirical analysis of the loss landscape of machine learning (ML) models. The method is applied to two ML models for scientific sensing, which necessitates quantization to be deployed and are subject to noise and perturbations due to experimental conditions. Our method allows assessing the robustness of ML models to such effects as a function of quantization precision and under different regularization techniques -- two crucial concerns that remained underexplored so far. By investigating the interplay between performance, efficiency, and robustness by means of loss landscape analysis, we both established a strong correlation between gently-shaped landscapes and robustness to input and weight perturbations and observed other intriguing and non-obvious phenomena. Our method allows a systematic exploration of such trade-offs a priori, i.e., without training and testing multiple models, leading to more efficient development workflows. This work also highlights the importance of incorporating robustness into the Pareto optimization of ML models, enabling more reliable and adaptive scientific sensing systems.
Edge-Only Universal Adversarial Attacks in Distributed Learning
Nov 15, 2024



Distributed learning frameworks, which partition neural network models across multiple computing nodes, enhance efficiency in collaborative edge-cloud systems but may also introduce new vulnerabilities. In this work, we explore the feasibility of generating universal adversarial attacks when an attacker has access to the edge part of the model only, which consists in the first network layers. Unlike traditional universal adversarial perturbations (UAPs) that require full model knowledge, our approach shows that adversaries can induce effective mispredictions in the unknown cloud part by leveraging key features on the edge side. Specifically, we train lightweight classifiers from intermediate features available at the edge, i.e., before the split point, and use them in a novel targeted optimization to craft effective UAPs. Our results on ImageNet demonstrate strong attack transferability to the unknown cloud part. Additionally, we analyze the capability of an attacker to achieve targeted adversarial effect with edge-only knowledge, revealing intriguing behaviors. By introducing the first adversarial attacks with edge-only knowledge in split inference, this work underscores the importance of addressing partial model access in adversarial robustness, encouraging further research in this area.
Attention-Based Real-Time Defenses for Physical Adversarial Attacks in Vision Applications
Nov 19, 2023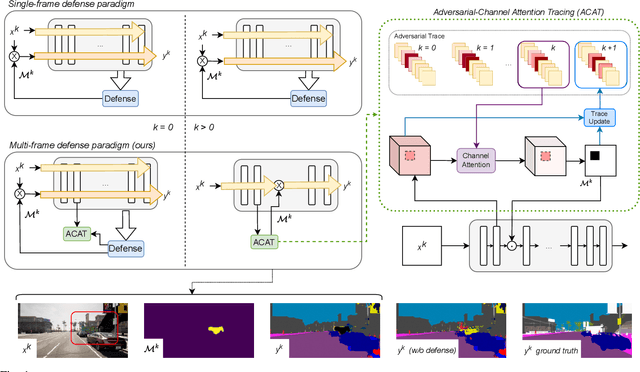
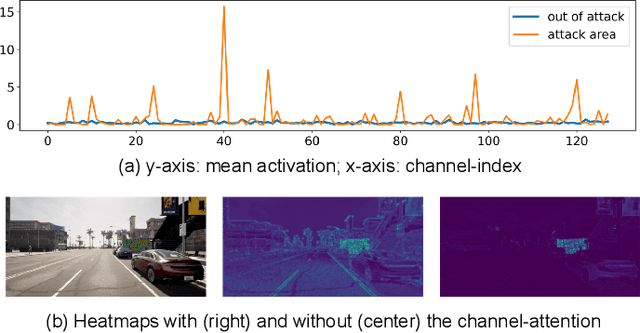
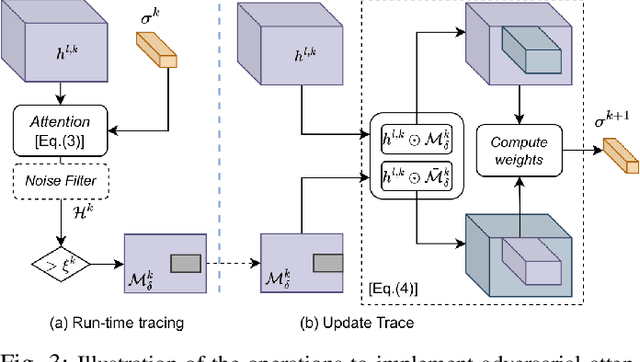
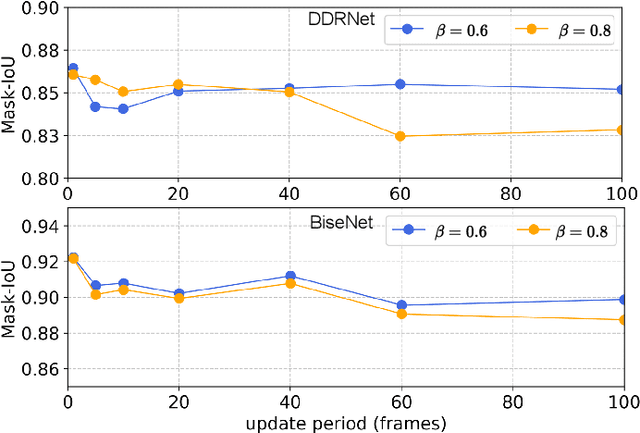
Deep neural networks exhibit excellent performance in computer vision tasks, but their vulnerability to real-world adversarial attacks, achieved through physical objects that can corrupt their predictions, raises serious security concerns for their application in safety-critical domains. Existing defense methods focus on single-frame analysis and are characterized by high computational costs that limit their applicability in multi-frame scenarios, where real-time decisions are crucial. To address this problem, this paper proposes an efficient attention-based defense mechanism that exploits adversarial channel-attention to quickly identify and track malicious objects in shallow network layers and mask their adversarial effects in a multi-frame setting. This work advances the state of the art by enhancing existing over-activation techniques for real-world adversarial attacks to make them usable in real-time applications. It also introduces an efficient multi-frame defense framework, validating its efficacy through extensive experiments aimed at evaluating both defense performance and computational cost.
Robust-by-Design Classification via Unitary-Gradient Neural Networks
Sep 09, 2022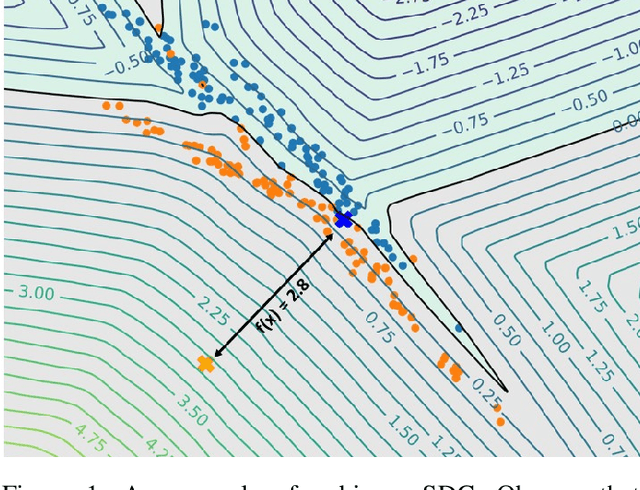

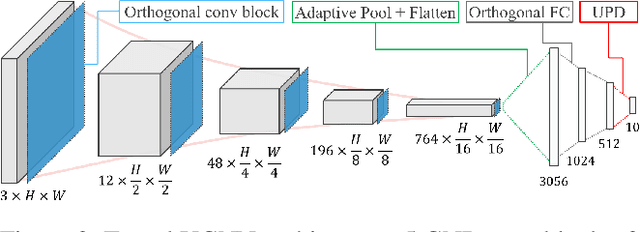
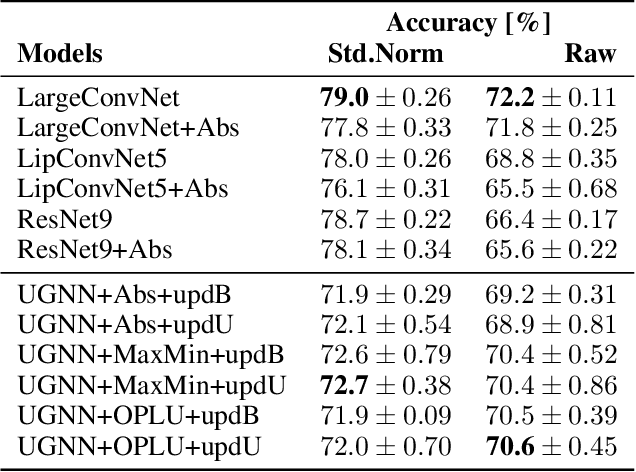
The use of neural networks in safety-critical systems requires safe and robust models, due to the existence of adversarial attacks. Knowing the minimal adversarial perturbation of any input x, or, equivalently, knowing the distance of x from the classification boundary, allows evaluating the classification robustness, providing certifiable predictions. Unfortunately, state-of-the-art techniques for computing such a distance are computationally expensive and hence not suited for online applications. This work proposes a novel family of classifiers, namely Signed Distance Classifiers (SDCs), that, from a theoretical perspective, directly output the exact distance of x from the classification boundary, rather than a probability score (e.g., SoftMax). SDCs represent a family of robust-by-design classifiers. To practically address the theoretical requirements of a SDC, a novel network architecture named Unitary-Gradient Neural Network is presented. Experimental results show that the proposed architecture approximates a signed distance classifier, hence allowing an online certifiable classification of x at the cost of a single inference.
CARLA-GeAR: a Dataset Generator for a Systematic Evaluation of Adversarial Robustness of Vision Models
Jun 09, 2022
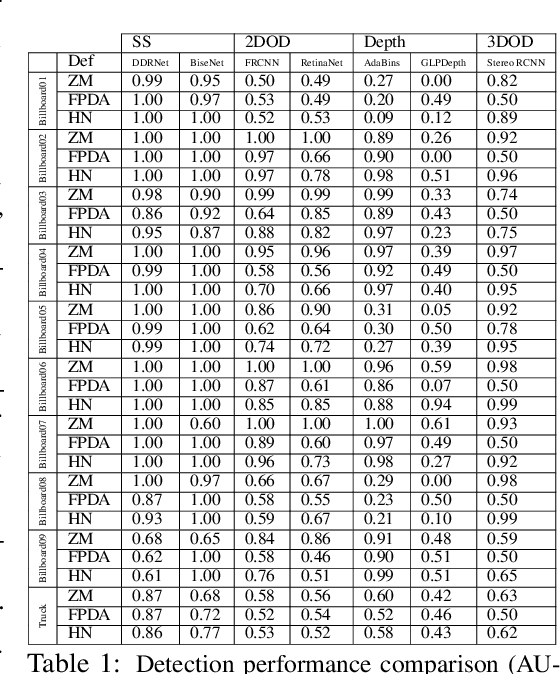
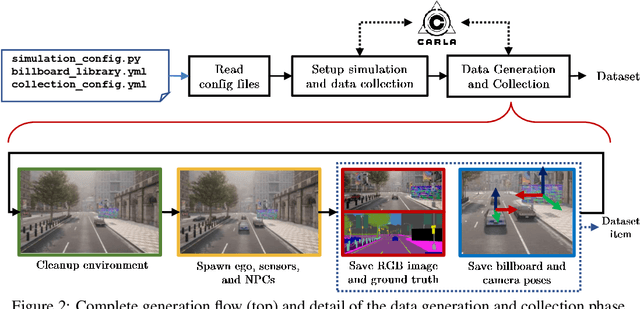
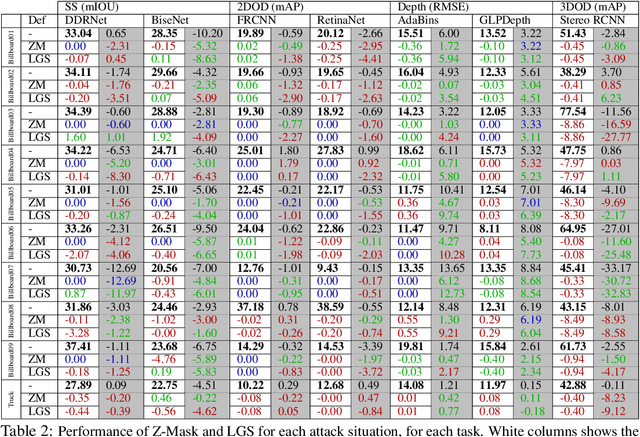
Adversarial examples represent a serious threat for deep neural networks in several application domains and a huge amount of work has been produced to investigate them and mitigate their effects. Nevertheless, no much work has been devoted to the generation of datasets specifically designed to evaluate the adversarial robustness of neural models. This paper presents CARLA-GeAR, a tool for the automatic generation of photo-realistic synthetic datasets that can be used for a systematic evaluation of the adversarial robustness of neural models against physical adversarial patches, as well as for comparing the performance of different adversarial defense/detection methods. The tool is built on the CARLA simulator, using its Python API, and allows the generation of datasets for several vision tasks in the context of autonomous driving. The adversarial patches included in the generated datasets are attached to billboards or the back of a truck and are crafted by using state-of-the-art white-box attack strategies to maximize the prediction error of the model under test. Finally, the paper presents an experimental study to evaluate the performance of some defense methods against such attacks, showing how the datasets generated with CARLA-GeAR might be used in future work as a benchmark for adversarial defense in the real world. All the code and datasets used in this paper are available at http://carlagear.retis.santannapisa.it.
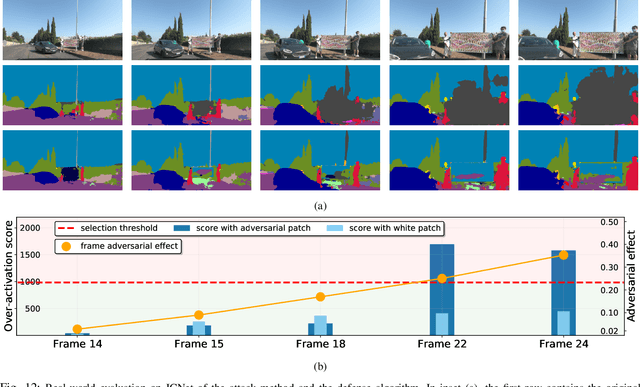
Defending From Physically-Realizable Adversarial Attacks Through Internal Over-Activation Analysis
Mar 14, 2022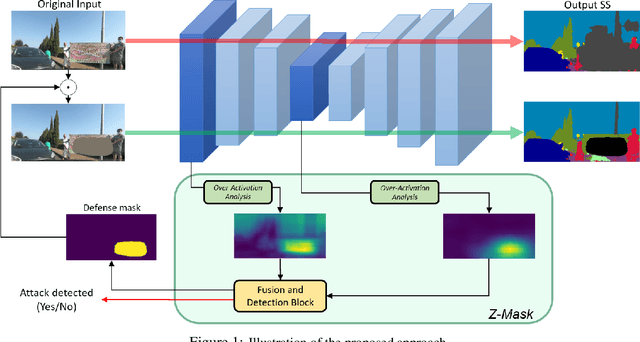

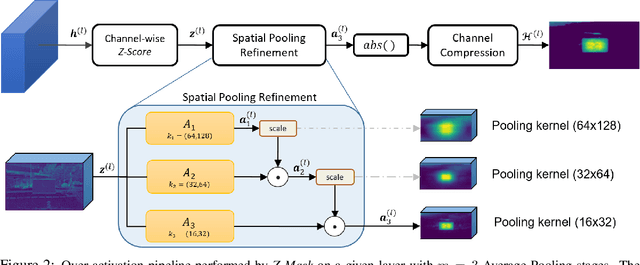
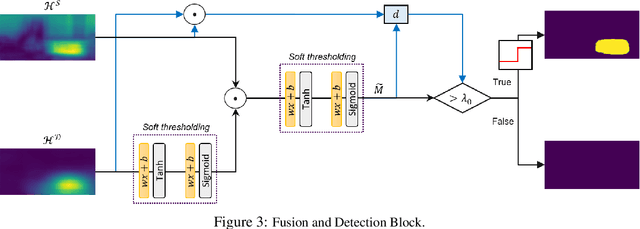
This work presents Z-Mask, a robust and effective strategy to improve the adversarial robustness of convolutional networks against physically-realizable adversarial attacks. The presented defense relies on specific Z-score analysis performed on the internal network features to detect and mask the pixels corresponding to adversarial objects in the input image. To this end, spatially contiguous activations are examined in shallow and deep layers to suggest potential adversarial regions. Such proposals are then aggregated through a multi-thresholding mechanism. The effectiveness of Z-Mask is evaluated with an extensive set of experiments carried out on models for both semantic segmentation and object detection. The evaluation is performed with both digital patches added to the input images and printed patches positioned in the real world. The obtained results confirm that Z-Mask outperforms the state-of-the-art methods in terms of both detection accuracy and overall performance of the networks under attack. Additional experiments showed that Z-Mask is also robust against possible defense-aware attacks.
On the Real-World Adversarial Robustness of Real-Time Semantic Segmentation Models for Autonomous Driving
Jan 05, 2022
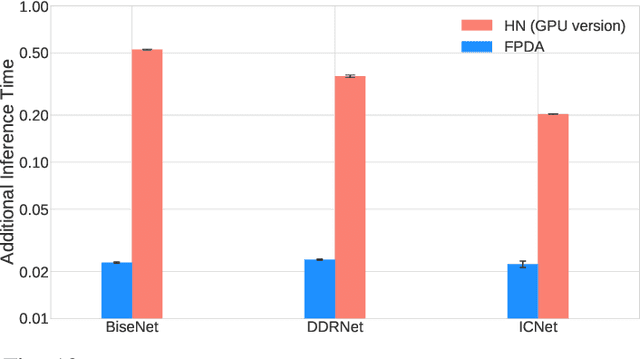
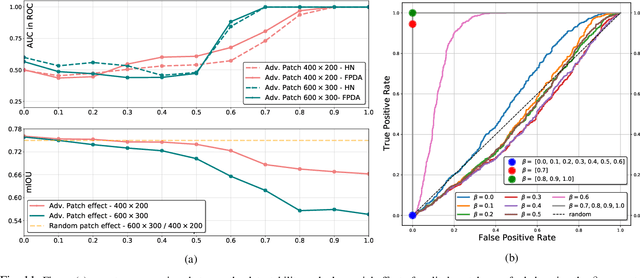
The existence of real-world adversarial examples (commonly in the form of patches) poses a serious threat for the use of deep learning models in safety-critical computer vision tasks such as visual perception in autonomous driving. This paper presents an extensive evaluation of the robustness of semantic segmentation models when attacked with different types of adversarial patches, including digital, simulated, and physical ones. A novel loss function is proposed to improve the capabilities of attackers in inducing a misclassification of pixels. Also, a novel attack strategy is presented to improve the Expectation Over Transformation method for placing a patch in the scene. Finally, a state-of-the-art method for detecting adversarial patch is first extended to cope with semantic segmentation models, then improved to obtain real-time performance, and eventually evaluated in real-world scenarios. Experimental results reveal that, even though the adversarial effect is visible with both digital and real-world attacks, its impact is often spatially confined to areas of the image around the patch. This opens to further questions about the spatial robustness of real-time semantic segmentation models.