 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Minimal Adversarial Perturbation for Deep Neural Networks with Provable Estimation Error
Paper and Code
Jan 04, 2022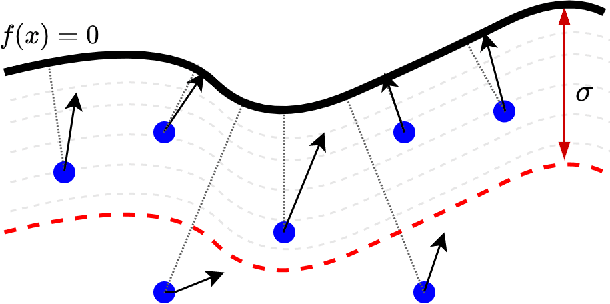
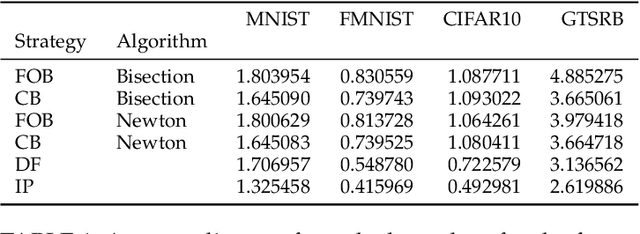
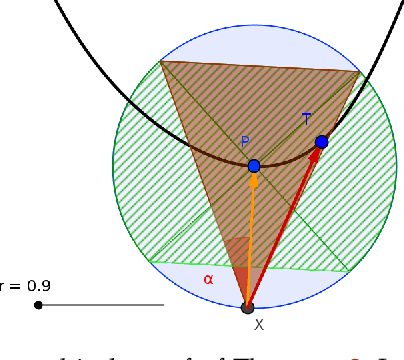
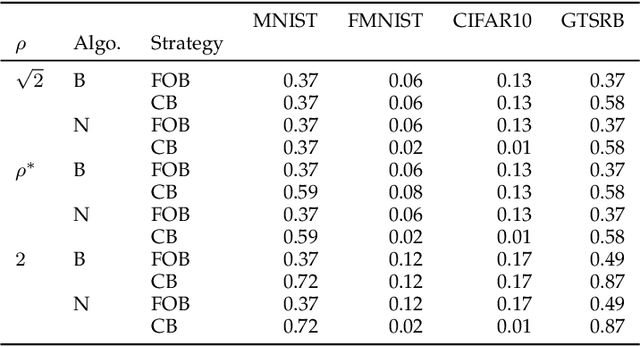
Although Deep Neural Networks (DNNs) have shown incredible performance in perceptive and control tasks, several trustworthy issues are still open. One of the most discussed topics is the existence of adversarial perturbations, which has opened an interesting research line on provable techniques capable of quantifying the robustness of a given input. In this regard, the Euclidean distance of the input from the classification boundary denotes a well-proved robustness assessment as the minimal affordable adversarial perturbation. Unfortunately, computing such a distance is highly complex due the non-convex nature of NNs. Despite several methods have been proposed to address this issue, to the best of our knowledge, no provable results have been presented to estimate and bound the error committed. This paper addresses this issue by proposing two lightweight strategies to find the minimal adversarial perturbation. Differently from the state-of-the-art, the proposed approach allows formulating an error estimation theory of the approximate distance with respect to the theoretical one. Finally, a substantial set of experiments is reported to evaluate the performance of the algorithms and support the theoretical findings. The obtained results show that the proposed strategies approximate the theoretical distance for samples close to the classification boundary, leading to provable robustness guarantees against any adversarial attacks.