 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Real-World Adversarial Robustness of Real-Time Semantic Segmentation Models for Autonomous Driving
Paper and Code

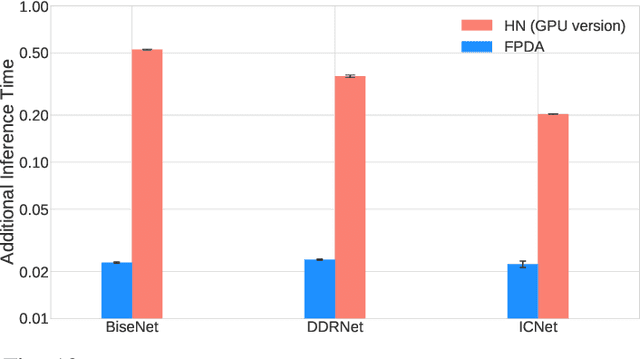
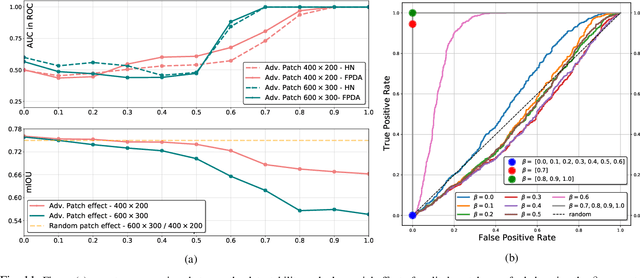
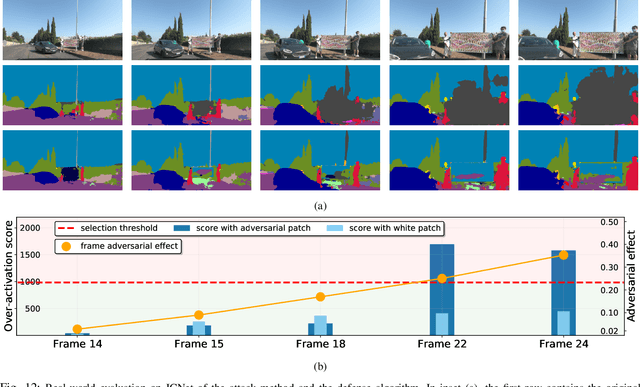
The existence of real-world adversarial examples (commonly in the form of patches) poses a serious threat for the use of deep learning models in safety-critical computer vision tasks such as visual perception in autonomous driving. This paper presents an extensive evaluation of the robustness of semantic segmentation models when attacked with different types of adversarial patches, including digital, simulated, and physical ones. A novel loss function is proposed to improve the capabilities of attackers in inducing a misclassification of pixels. Also, a novel attack strategy is presented to improve the Expectation Over Transformation method for placing a patch in the scene. Finally, a state-of-the-art method for detecting adversarial patch is first extended to cope with semantic segmentation models, then improved to obtain real-time performance, and eventually evaluated in real-world scenarios. Experimental results reveal that, even though the adversarial effect is visible with both digital and real-world attacks, its impact is often spatially confined to areas of the image around the patch. This opens to further questions about the spatial robustness of real-time semantic segmentation models.