 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPGA-based AI Smart NICs for Scalable Distributed AI Training Systems
Apr 22, 2022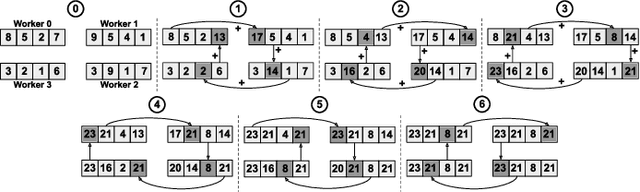
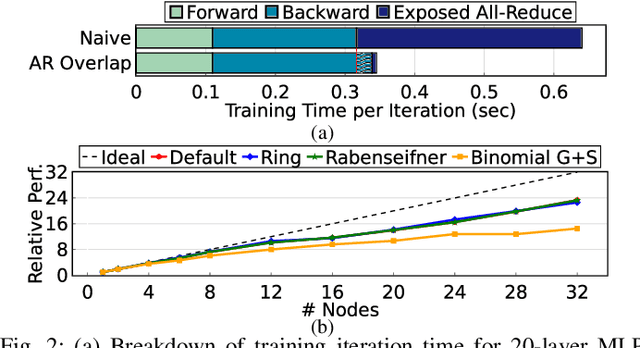
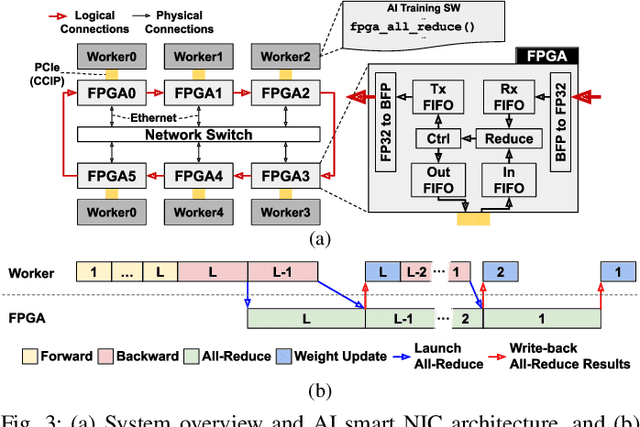
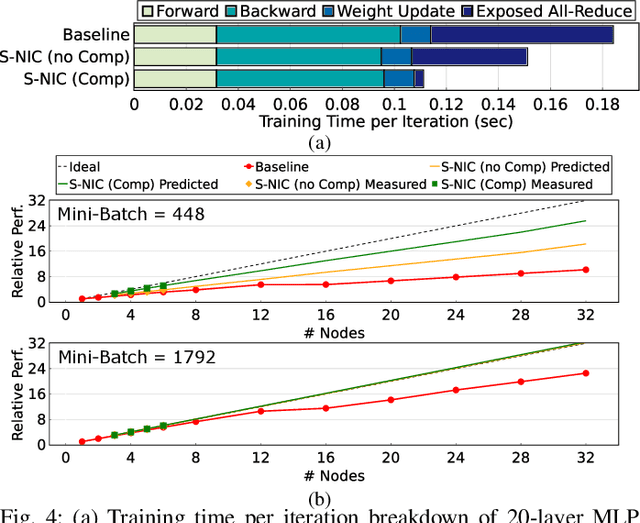
Rapid advances in artificial intelligence (AI) technology have led to significant accuracy improvements in a myriad of application domains at the cost of larger and more compute-intensive models. Training such models on massive amounts of data typically requires scaling to many compute nodes and relies heavily on collective communication algorithms, such as all-reduce, to exchange the weight gradients between different nodes. The overhead of these collective communication operations in a distributed AI training system can bottleneck its performance, with more pronounced effects as the number of nodes increases. In this paper, we first characterize the all-reduce operation overhead by profiling distributed AI training. Then, we propose a new smart network interface card (NIC) for distributed AI training systems using field-programmable gate arrays (FPGAs) to accelerate all-reduce operations and optimize network bandwidth utilization via data compression. The AI smart NIC frees up the system's compute resources to perform the more compute-intensive tensor operations and increases the overall node-to-node communication efficiency. We perform real measurements on a prototype distributed AI training system comprised of 6 compute nodes to evaluate the performance gains of our proposed FPGA-based AI smart NIC compared to a baseline system with regular NICs. We also use these measurements to validate an analytical model that we formulate to predict performance when scaling to larger systems. Our proposed FPGA-based AI smart NIC enhances overall training performance by 1.6x at 6 nodes, with an estimated 2.5x performance improvement at 32 nodes, compared to the baseline system using conventional NICs.
Neighbors From Hell: Voltage Attacks Against Deep Learning Accelerators on Multi-Tenant FPGAs
Dec 14, 2020



Field-programmable gate arrays (FPGAs) are becoming widely used accelerators for a myriad of datacenter applications due to their flexibility and energy efficiency. Among these applications, FPGAs have shown promising results in accelerating low-latency real-time deep learning (DL) inference, which is becoming an indispensable component of many end-user applications. With the emerging research direction towards virtualized cloud FPGAs that can be shared by multiple users, the security aspect of FPGA-based DL accelerators requires careful consideration. In this work, we evaluate the security of DL accelerators against voltage-based integrity attacks in a multitenant FPGA scenario. We first demonstrate the feasibility of such attacks on a state-of-the-art Stratix 10 card using different attacker circuits that are logically and physically isolated in a separate attacker role, and cannot be flagged as malicious circuits by conventional bitstream checkers. We show that aggressive clock gating, an effective power-saving technique, can also be a potential security threat in modern FPGAs. Then, we carry out the attack on a DL accelerator running ImageNet classification in the victim role to evaluate the inherent resilience of DL models against timing faults induced by the adversary. We find that even when using the strongest attacker circuit, the prediction accuracy of the DL accelerator is not compromised when running at its safe operating frequency. Furthermore, we can achieve 1.18-1.31x higher inference performance by over-clocking the DL accelerator without affecting its prediction accuracy.