 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropBack: Continuous Pruning During Training
Paper and Code
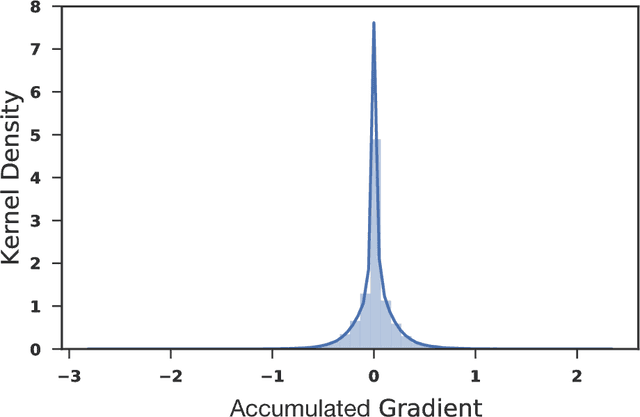
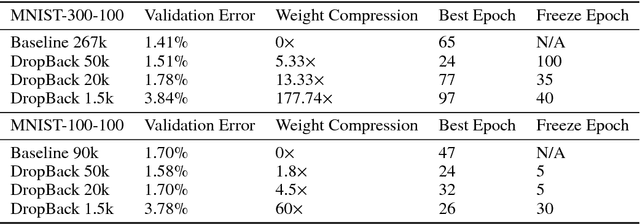
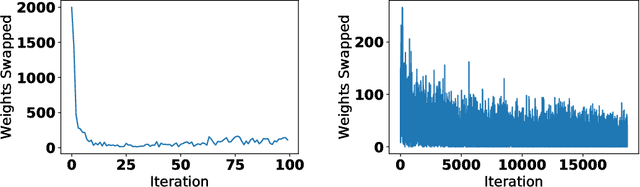
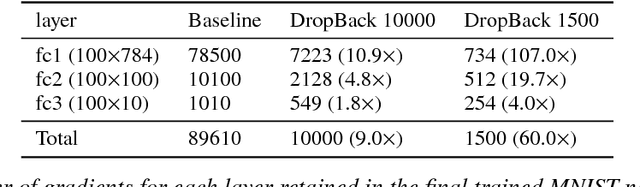
We introduce a technique that compresses deep neural networks both during and after training by constraining the total number of weights updated during backpropagation to those with the highest total gradients. The remaining weights are forgotten and their initial value is regenerated at every access to avoid storing them in memory. This dramatically reduces the number of off-chip memory accesses during both training and inference, a key component of the energy needs of DNN accelerators. By ensuring that the total weight diffusion remains close to that of baseline unpruned SGD, networks pruned using DropBack are able to maintain high accuracy across network architectures. We observe weight compression of 25x with LeNet-300-100 on MNIST while maintaining accuracy. On CIFAR-10, we see an approximately 5x weight compression on 3 models: an already 9x-reduced VGG-16, Densenet, and WRN-28-10 - all with zero or negligible accuracy loss. On Densenet and WRN, which are particularly challenging to compress, Both Densenet and WRN improve on the state of the art, achieving higher compression with better accuracy than prior pruning techniques.