 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytically-Driven Resource Management for Cloud-Native Microservices
Jan 05, 2024



Resource management for cloud-native microservices has attracted a lot of recent attention. Previous work has shown that machine learning (ML)-driven approaches outperform traditional techniques, such as autoscaling, in terms of both SLA maintenance and resource efficiency. However, ML-driven approaches also face challenges including lengthy data collection processes and limited scalability. We present Ursa, a lightweight resource management system for cloud-native microservices that addresses these challenges. Ursa uses an analytical model that decomposes the end-to-end SLA into per-service SLA, and maps per-service SLA to individual resource allocations per microservice tier. To speed up the exploration process and avoid prolonged SLA violations, Ursa explores each microservice individually, and swiftly stops exploration if latency exceeds its SLA. We evaluate Ursa on a set of representative and end-to-end microservice topologies, including a social network, media service and video processing pipeline, each consisting of multiple classes and priorities of requests with different SLAs, and compare it against two representative ML-driven systems, Sinan and Firm. Compared to these ML-driven approaches, Ursa provides significant advantages: It shortens the data collection process by more than 128x, and its control plane is 43x faster than ML-driven approaches. At the same time, Ursa does not sacrifice resource efficiency or SLAs. During online deployment, Ursa reduces the SLA violation rate by 9.0% up to 49.9%, and reduces CPU allocation by up to 86.2% compared to ML-driven approaches.
Sinan: Data-Driven, QoS-Aware Cluster Management for Microservices
May 27, 2021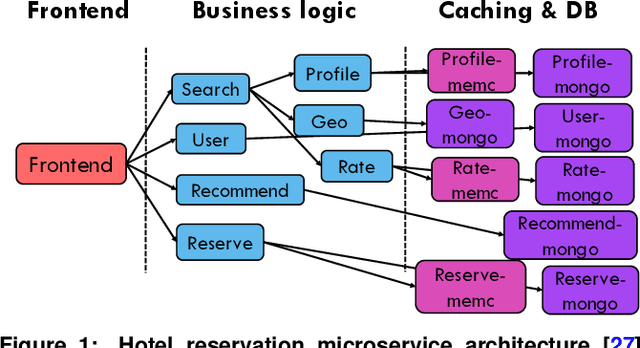
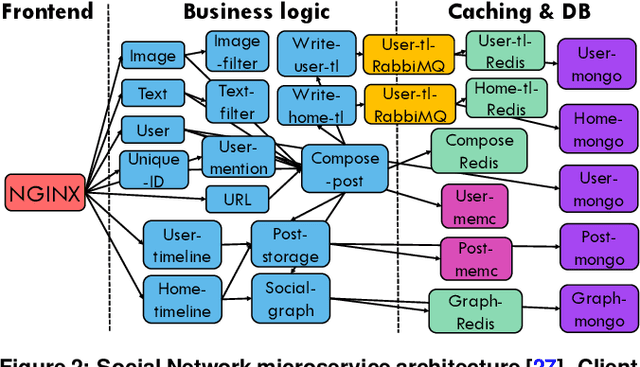

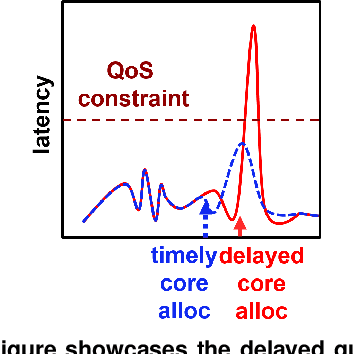
Cloud applications are increasingly shifting from large monolithic services, to large numbers of loosely-coupled, specialized microservices. Despite their advantages in terms of facilitating development, deployment, modularity, and isolation, microservices complicate resource management, as dependencies between them introduce backpressure effects and cascading QoS violations. We present Sinan, a data-driven cluster manager for interactive cloud microservices that is online and QoS-aware. Sinan leverages a set of scalable and validated machine learning models to determine the performance impact of dependencies between microservices, and allocate appropriate resources per tier in a way that preserves the end-to-end tail latency target. We evaluate Sinan both on dedicated local clusters and large-scale deployments on Google Compute Engine (GCE) across representative end-to-end applications built with microservices, such as social networks and hotel reservation sites. We show that Sinan always meets QoS, while also maintaining cluster utilization high, in contrast to prior work which leads to unpredictable performance or sacrifices resource efficiency. Furthermore, the techniques in Sinan are explainable, meaning that cloud operators can yield insights from the ML models on how to better deploy and design their applications to reduce unpredictable performance.