 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel Gating Neural Networks
Paper and Code
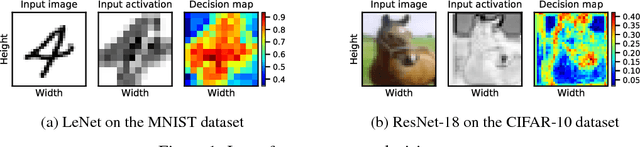
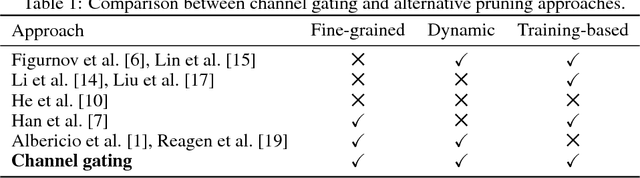
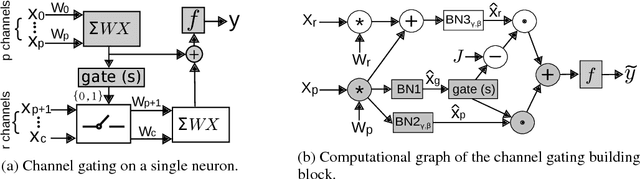
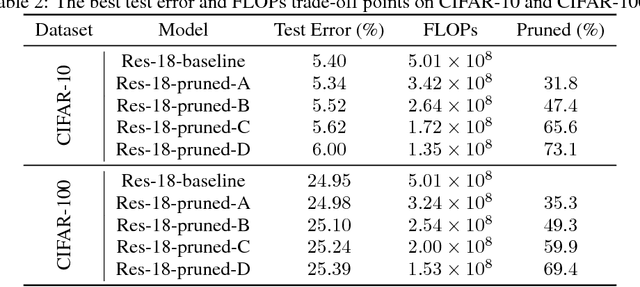
Employing deep neural networks to obtain state-of-the-art performance on computer vision tasks can consume billions of floating point operations and several Joules of energy per evaluation. Network pruning, which statically removes unnecessary features and weights, has emerged as a promising way to reduce this computation cost. In this paper, we propose channel gating, a dynamic, fine-grained, training-based computation-cost-reduction scheme. Channel gating works by identifying the regions in the features which contribute less to the classification result and turning off a subset of the channels for computing the pixels within these uninteresting regions. Unlike static network pruning, the channel gating optimizes computations exploiting characteristics specific to each input at run-time. We show experimentally that applying channel gating in state-of-the-art networks can achieve 66% and 60% reduction in FLOPs with 0.22% and 0.29% accuracy loss on the CIFAR-10 and CIFAR-100 datasets, respectively.