 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Weight Regularization for Large Minibatch SGD
Nov 17, 2020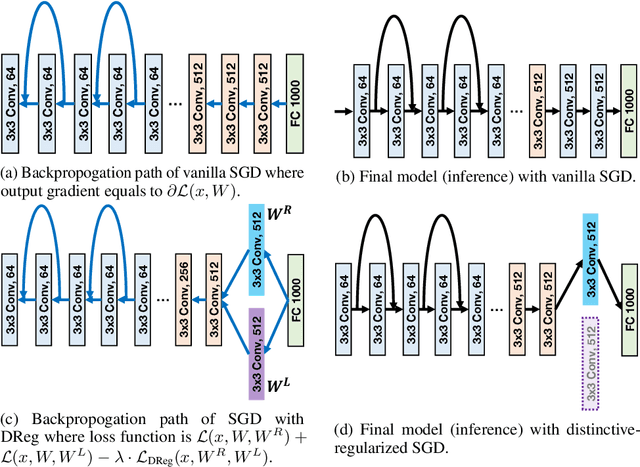
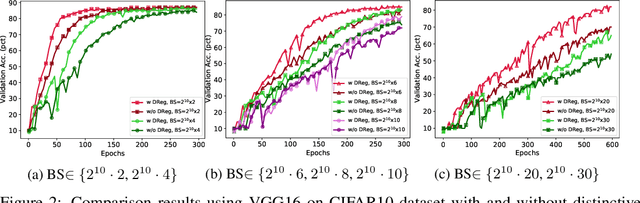
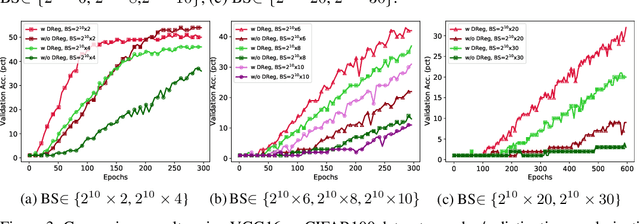
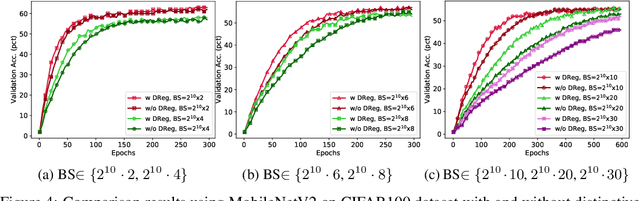
The minibatch stochastic gradient descent method (SGD) is widely applied in deep learning due to its efficiency and scalability that enable training deep networks with a large volume of data. Particularly in the distributed setting, SGD is usually applied with large batch size. However, as opposed to small-batch SGD, neural network models trained with large-batch SGD can hardly generalize well, i.e., the validation accuracy is low. In this work, we introduce a novel regularization technique, namely distinctive regularization (DReg), which replicates a certain layer of the deep network and encourages the parameters of both layers to be diverse. The DReg technique introduces very little computation overhead. Moreover, we empirically show that optimizing the neural network with DReg using large-batch SGD achieves a significant boost in the convergence and improved generalization performance. We also demonstrate that DReg can boost the convergence of large-batch SGD with momentum. We believe that DReg can be used as a simple regularization trick to accelerate large-batch training in deep learning.