 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCocktail Party Attack: Breaking Aggregation-Based Privacy in Federated Learning using Independent Component Analysis
Sep 12, 2022


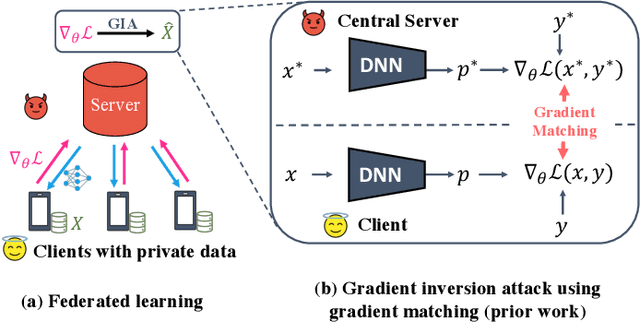
Federated learning (FL) aims to perform privacy-preserving machine learning on distributed data held by multiple data owners. To this end, FL requires the data owners to perform training locally and share the gradient updates (instead of the private inputs) with the central server, which are then securely aggregated over multiple data owners. Although aggregation by itself does not provably offer privacy protection, prior work showed that it may suffice if the batch size is sufficiently large. In this paper, we propose the Cocktail Party Attack (CPA) that, contrary to prior belief, is able to recover the private inputs from gradients aggregated over a very large batch size. CPA leverages the crucial insight that aggregate gradients from a fully connected layer is a linear combination of its inputs, which leads us to frame gradient inversion as a blind source separation (BSS) problem (informally called the cocktail party problem). We adapt independent component analysis (ICA)--a classic solution to the BSS problem--to recover private inputs for fully-connected and convolutional networks, and show that CPA significantly outperforms prior gradient inversion attacks, scales to ImageNet-sized inputs, and works on large batch sizes of up to 1024.
Gradient Inversion Attack: Leaking Private Labels in Two-Party Split Learning
Nov 25, 2021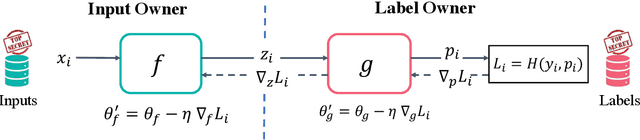
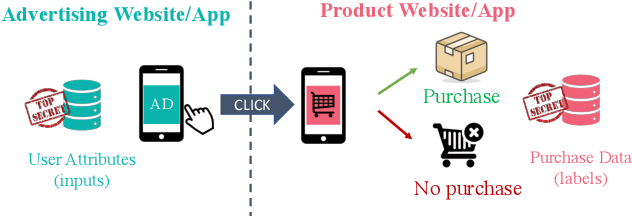
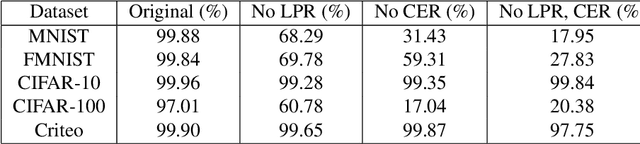
Split learning is a popular technique used to perform vertical federated learning, where the goal is to jointly train a model on the private input and label data held by two parties. To preserve privacy of the input and label data, this technique uses a split model and only requires the exchange of intermediate representations (IR) of the inputs and gradients of the IR between the two parties during the learning process. In this paper, we propose Gradient Inversion Attack (GIA), a label leakage attack that allows an adversarial input owner to learn the label owner's private labels by exploiting the gradient information obtained during split learning. GIA frames the label leakage attack as a supervised learning problem by developing a novel loss function using certain key properties of the dataset and models. Our attack can uncover the private label data on several multi-class image classification problems and a binary conversion prediction task with near-perfect accuracy (97.01% - 99.96%), demonstrating that split learning provides negligible privacy benefits to the label owner. Furthermore, we evaluate the use of gradient noise to defend against GIA. While this technique is effective for simpler datasets, it significantly degrades utility for datasets with higher input dimensionality. Our findings underscore the need for better privacy-preserving training techniques for vertically split data.
Enabling Inference Privacy with Adaptive Noise Injection
Apr 06, 2021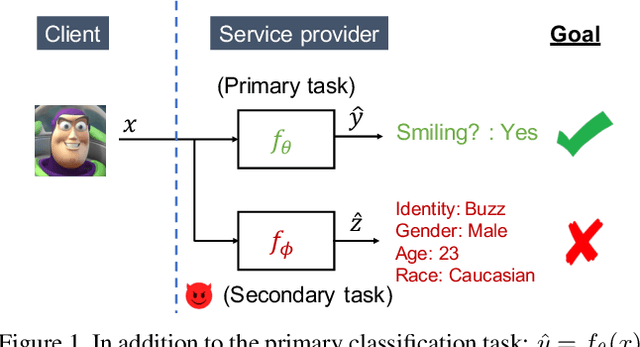



User-facing software services are becoming increasingly reliant on remote servers to host Deep Neural Network (DNN) models, which perform inference tasks for the clients. Such services require the client to send input data to the service provider, who processes it using a DNN and returns the output predictions to the client. Due to the rich nature of the inputs such as images and speech, the input often contains more information than what is necessary to perform the primary inference task. Consequently, in addition to the primary inference task, a malicious service provider could infer secondary (sensitive) attributes from the input, compromising the client's privacy. The goal of our work is to improve inference privacy by injecting noise to the input to hide the irrelevant features that are not conducive to the primary classification task. To this end, we propose Adaptive Noise Injection (ANI), which uses a light-weight DNN on the client-side to inject noise to each input, before transmitting it to the service provider to perform inference. Our key insight is that by customizing the noise to each input, we can achieve state-of-the-art trade-off between utility and privacy (up to 48.5% degradation in sensitive-task accuracy with <1% degradation in primary accuracy), significantly outperforming existing noise injection schemes. Our method does not require prior knowledge of the sensitive attributes and incurs minimal computational overheads.
Defending Against Model Stealing Attacks with Adaptive Misinformation
Nov 16, 2019

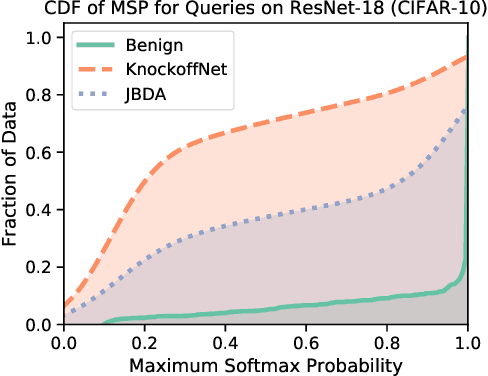
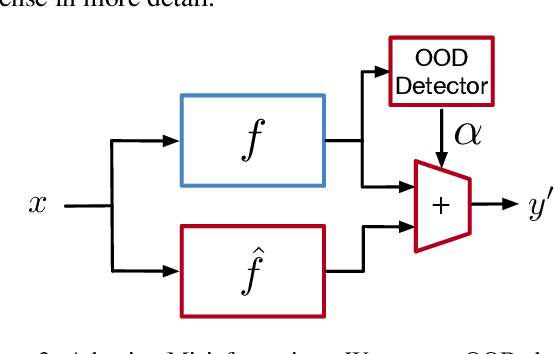
Deep Neural Networks (DNNs) are susceptible to model stealing attacks, which allows a data-limited adversary with no knowledge of the training dataset to clone the functionality of a target model, just by using black-box query access. Such attacks are typically carried out by querying the target model using inputs that are synthetically generated or sampled from a surrogate dataset to construct a labeled dataset. The adversary can use this labeled dataset to train a clone model, which achieves a classification accuracy comparable to that of the target model. We propose "Adaptive Misinformation" to defend against such model stealing attacks. We identify that all existing model stealing attacks invariably query the target model with Out-Of-Distribution (OOD) inputs. By selectively sending incorrect predictions for OOD queries, our defense substantially degrades the accuracy of the attacker's clone model (by up to 40%), while minimally impacting the accuracy (<0.5%) for benign users. Compared to existing defenses, our defense has a significantly better security vs accuracy trade-off and incurs minimal computational overhead.