 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiALS++: Speeding up Matrix Factorization with Subspace Optimization
Oct 26, 2021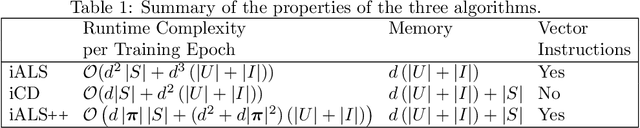
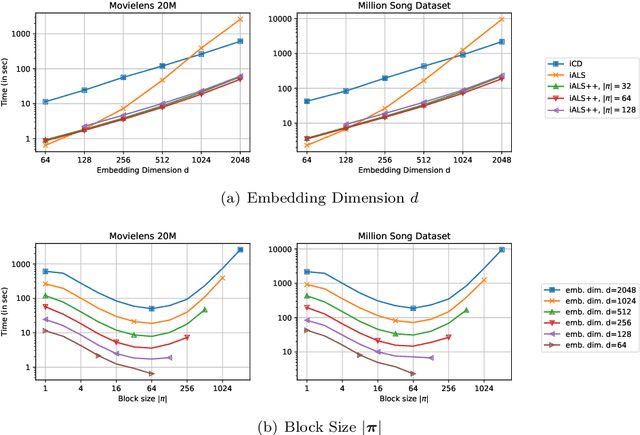

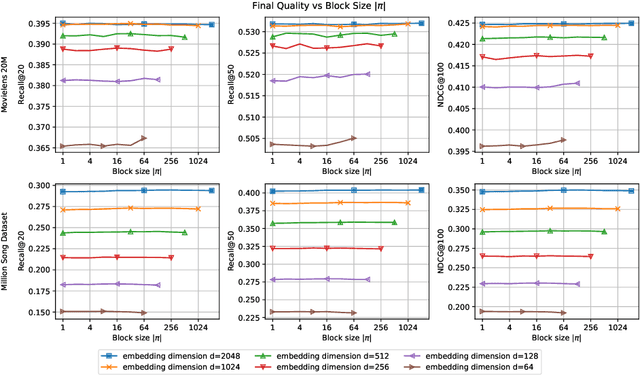
iALS is a popular algorithm for learning matrix factorization models from implicit feedback with alternating least squares. This algorithm was invented over a decade ago but still shows competitive quality compared to recent approaches like VAE, EASE, SLIM, or NCF. Due to a computational trick that avoids negative sampling, iALS is very efficient especially for large item catalogues. However, iALS does not scale well with large embedding dimensions, d, due to its cubic runtime dependency on d. Coordinate descent variations, iCD, have been proposed to lower the complexity to quadratic in d. In this work, we show that iCD approaches are not well suited for modern processors and can be an order of magnitude slower than a careful iALS implementation for small to mid scale embedding sizes (d ~ 100) and only perform better than iALS on large embeddings d ~ 1000. We propose a new solver iALS++ that combines the advantages of iALS in terms of vector processing with a low computational complexity as in iCD. iALS++ is an order of magnitude faster than iCD both for small and large embedding dimensions. It can solve benchmark problems like Movielens 20M or Million Song Dataset even for 1000 dimensional embedding vectors in a few minutes.
Revisiting the Performance of iALS on Item Recommendation Benchmarks
Oct 26, 2021
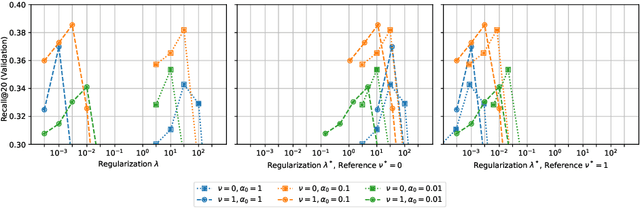


Matrix factorization learned by implicit alternating least squares (iALS) is a popular baseline in recommender system research publications. iALS is known to be one of the most computationally efficient and scalable collaborative filtering methods. However, recent studies suggest that its prediction quality is not competitive with the current state of the art, in particular autoencoders and other item-based collaborative filtering methods. In this work, we revisit the iALS algorithm and present a bag of tricks that we found useful when applying iALS. We revisit four well-studied benchmarks where iALS was reported to perform poorly and show that with proper tuning, iALS is highly competitive and outperforms any method on at least half of the comparisons. We hope that these high quality results together with iALS's known scalability spark new interest in applying and further improving this decade old technique.
On the Difficulty of Evaluating Baselines: A Study on Recommender Systems
May 04, 2019



Numerical evaluations with comparisons to baselines play a central role when judging research in recommender systems. In this paper, we show that running baselines properly is difficult. We demonstrate this issue on two extensively studied datasets. First, we show that results for baselines that have been used in numerous publications over the past five years for the Movielens 10M benchmark are suboptimal. With a careful setup of a vanilla matrix factorization baseline, we are not only able to improve upon the reported results for this baseline but even outperform the reported results of any newly proposed method. Secondly, we recap the tremendous effort that was required by the community to obtain high quality results for simple methods on the Netflix Prize. Our results indicate that empirical findings in research papers are questionable unless they were obtained on standardized benchmarks where baselines have been tuned extensively by the research community.
Recommender Systems for the Conference Paper Assignment Problem
Jun 22, 2009


Conference paper assignment, i.e., the task of assigning paper submissions to reviewers, presents multi-faceted issues for recommender systems research. Besides the traditional goal of predicting `who likes what?', a conference management system must take into account aspects such as: reviewer capacity constraints, adequate numbers of reviews for papers, expertise modeling, conflicts of interest, and an overall distribution of assignments that balances reviewer preferences with conference objectives. Among these, issues of modeling preferences and tastes in reviewing have traditionally been studied separately from the optimization of paper-reviewer assignment. In this paper, we present an integrated study of both these aspects. First, due to the paucity of data per reviewer or per paper (relative to other recommender systems applications) we show how we can integrate multiple sources of information to learn paper-reviewer preference models. Second, our models are evaluated not just in terms of prediction accuracy but in terms of the end-assignment quality. Using a linear programming-based assignment optimization formulation, we show how our approach better explores the space of unsupplied assignments to maximize the overall affinities of papers assigned to reviewers. We demonstrate our results on real reviewer preference data from the IEEE ICDM 2007 conference.