 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Image Classification from Features
Paper and Code

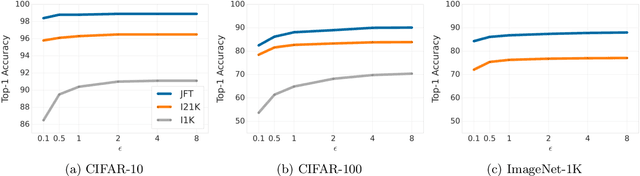
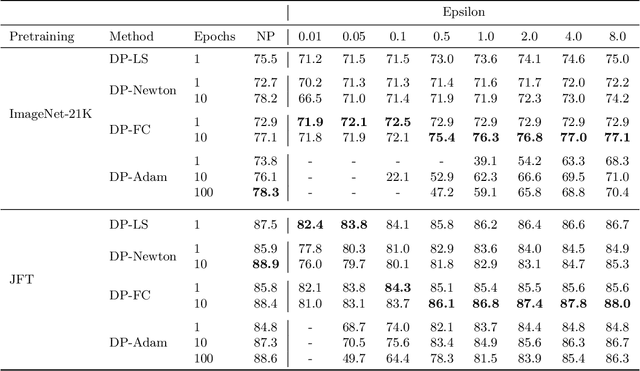
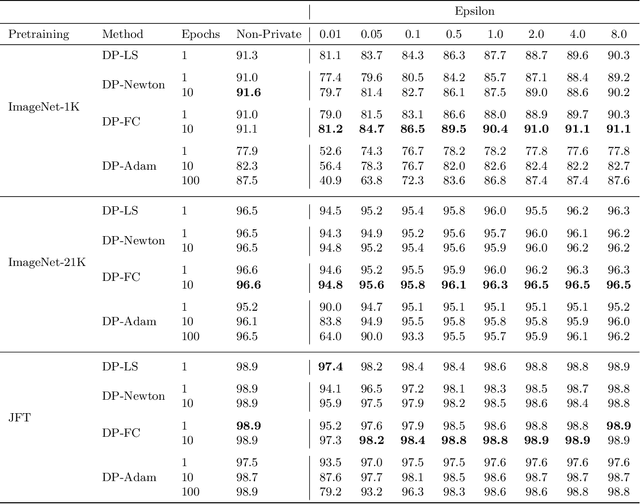
Leveraging transfer learning has recently been shown to be an effective strategy for training large models with Differential Privacy (DP). Moreover, somewhat surprisingly, recent works have found that privately training just the last layer of a pre-trained model provides the best utility with DP. While past studies largely rely on algorithms like DP-SGD for training large models, in the specific case of privately learning from features, we observe that computational burden is low enough to allow for more sophisticated optimization schemes, including second-order methods. To that end, we systematically explore the effect of design parameters such as loss function and optimization algorithm. We find that, while commonly used logistic regression performs better than linear regression in the non-private setting, the situation is reversed in the private setting. We find that linear regression is much more effective than logistic regression from both privacy and computational aspects, especially at stricter epsilon values ($\epsilon < 1$). On the optimization side, we also explore using Newton's method, and find that second-order information is quite helpful even with privacy, although the benefit significantly diminishes with stricter privacy guarantees. While both methods use second-order information, least squares is effective at lower epsilons while Newton's method is effective at larger epsilon values. To combine the benefits of both, we propose a novel algorithm called DP-FC, which leverages feature covariance instead of the Hessian of the logistic regression loss and performs well across all $\epsilon$ values we tried. With this, we obtain new SOTA results on ImageNet-1k, CIFAR-100 and CIFAR-10 across all values of $\epsilon$ typically considered. Most remarkably, on ImageNet-1K, we obtain top-1 accuracy of 88\% under (8, $8 * 10^{-7}$)-DP and 84.3\% under (0.1, $8 * 10^{-7}$)-DP.