 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential Privacy Personalized Federated Learning Based on Dynamically Sparsified Client Updates
Mar 12, 2025Personalized federated learning is extensively utilized in scenarios characterized by data heterogeneity, facilitating more efficient and automated local training on data-owning terminals. This includes the automated selection of high-performance model parameters for upload, thereby enhancing the overall training process. However, it entails significant risks of privacy leakage. Existing studies have attempted to mitigate these risks by utilizing differential privacy. Nevertheless, these studies present two major limitations: (1) The integration of differential privacy into personalized federated learning lacks sufficient personalization, leading to the introduction of excessive noise into the model. (2) It fails to adequately control the spatial scope of model update information, resulting in a suboptimal balance between data privacy and model effectiveness in differential privacy federated learning. In this paper, we propose a differentially private personalized federated learning approach that employs dynamically sparsified client updates through reparameterization and adaptive norm(DP-pFedDSU). Reparameterization training effectively selects personalized client update information, thereby reducing the quantity of updates. This approach minimizes the introduction of noise to the greatest extent possible. Additionally, dynamic adaptive norm refers to controlling the norm space of model updates during the training process, mitigating the negative impact of clipping on the update information. These strategies substantially enhance the effective integration of differential privacy and personalized federated learning. Experimental results on EMNIST, CIFAR-10, and CIFAR-100 demonstrate that our proposed scheme achieves superior performance and is well-suited for more complex personalized federated learning scenarios.
ParetoRAG: Leveraging Sentence-Context Attention for Robust and Efficient Retrieval-Augmented Generation
Feb 12, 2025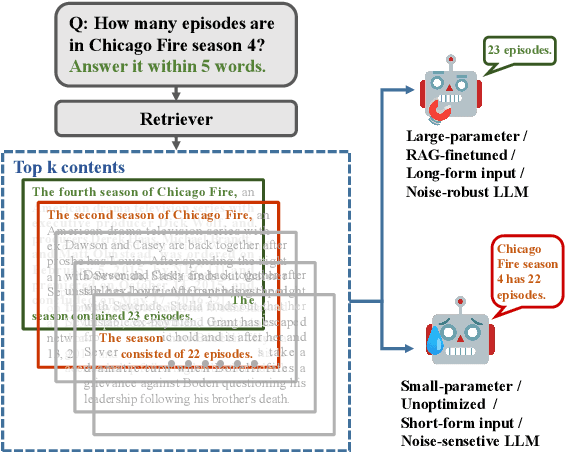



While Retrieval-Augmented Generation (RAG) systems enhance Large Language Models (LLMs) by incorporating external knowledge, they still face persistent challenges in retrieval inefficiency and the inability of LLMs to filter out irrelevant information. We present ParetoRAG, an unsupervised framework that optimizes RAG systems through sentence-level refinement guided by the Pareto principle. By decomposing paragraphs into sentences and dynamically re-weighting core content while preserving contextual coherence, ParetoRAG achieves dual improvements in both retrieval precision and generation quality without requiring additional training or API resources. This framework has been empirically validated across various datasets, LLMs, and retrievers.
Learning to Select Prototypical Parts for Interpretable Sequential Data Modeling
Dec 07, 2022
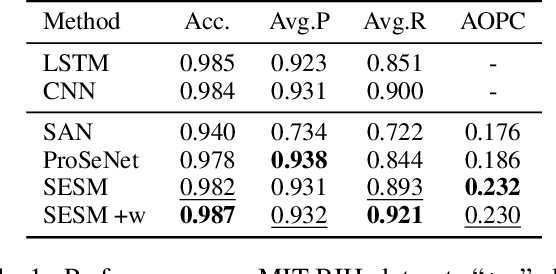

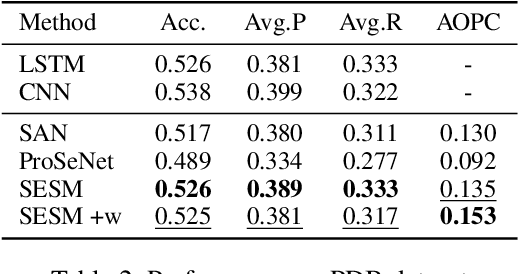
Prototype-based interpretability methods provide intuitive explanations of model prediction by comparing samples to a reference set of memorized exemplars or typical representatives in terms of similarity. In the field of sequential data modeling, similarity calculations of prototypes are usually based on encoded representation vectors. However, due to highly recursive functions, there is usually a non-negligible disparity between the prototype-based explanations and the original input. In this work, we propose a Self-Explaining Selective Model (SESM) that uses a linear combination of prototypical concepts to explain its own predictions. The model employs the idea of case-based reasoning by selecting sub-sequences of the input that mostly activate different concepts as prototypical parts, which users can compare to sub-sequences selected from different example inputs to understand model decisions. For better interpretability, we design multiple constraints including diversity, stability, and locality as training objectives. Extensive experiments in different domains demonstrate that our method exhibits promising interpretability and competitive accuracy.