 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthForge: Synthesizing High-Quality Face Dataset with Controllable 3D Generative Models
Jun 12, 2024



Recent advancements in generative models have unlocked the capabilities to render photo-realistic data in a controllable fashion. Trained on the real data, these generative models are capable of producing realistic samples with minimal to no domain gap, as compared to the traditional graphics rendering. However, using the data generated using such models for training downstream tasks remains under-explored, mainly due to the lack of 3D consistent annotations. Moreover, controllable generative models are learned from massive data and their latent space is often too vast to obtain meaningful sample distributions for downstream task with limited generation. To overcome these challenges, we extract 3D consistent annotations from an existing controllable generative model, making the data useful for downstream tasks. Our experiments show competitive performance against state-of-the-art models using only generated synthetic data, demonstrating potential for solving downstream tasks. Project page: https://synth-forge.github.io
Semi-Supervised Domain Adaptation by Similarity based Pseudo-label Injection
Sep 05, 2022One of the primary challenges in Semi-supervised Domain Adaptation (SSDA) is the skewed ratio between the number of labeled source and target samples, causing the model to be biased towards the source domain. Recent works in SSDA show that aligning only the labeled target samples with the source samples potentially leads to incomplete domain alignment of the target domain to the source domain. In our approach, to align the two domains, we leverage contrastive losses to learn a semantically meaningful and a domain agnostic feature space using the supervised samples from both domains. To mitigate challenges caused by the skewed label ratio, we pseudo-label the unlabeled target samples by comparing their feature representation to those of the labeled samples from both the source and target domains. Furthermore, to increase the support of the target domain, these potentially noisy pseudo-labels are gradually injected into the labeled target dataset over the course of training. Specifically, we use a temperature scaled cosine similarity measure to assign a soft pseudo-label to the unlabeled target samples. Additionally, we compute an exponential moving average of the soft pseudo-labels for each unlabeled sample. These pseudo-labels are progressively injected or removed) into the (from) the labeled target dataset based on a confidence threshold to supplement the alignment of the source and target distributions. Finally, we use a supervised contrastive loss on the labeled and pseudo-labeled datasets to align the source and target distributions. Using our proposed approach, we showcase state-of-the-art performance on SSDA benchmarks - Office-Home, DomainNet and Office-31.
ViTOL: Vision Transformer for Weakly Supervised Object Localization
Apr 14, 2022
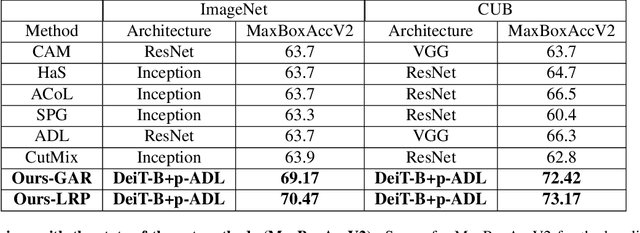
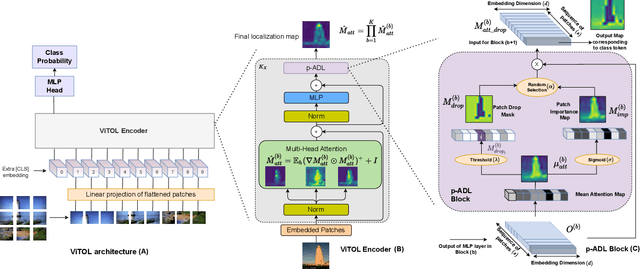
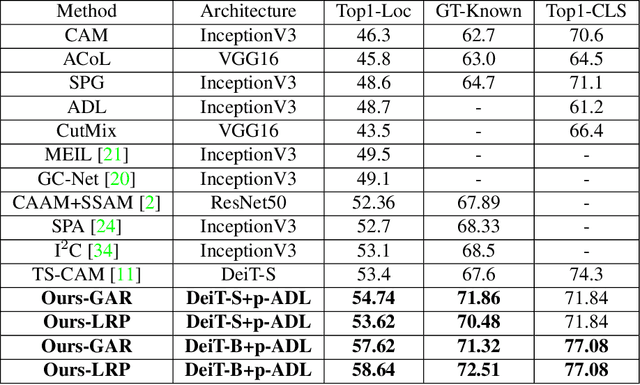
Weakly supervised object localization (WSOL) aims at predicting object locations in an image using only image-level category labels. Common challenges that image classification models encounter when localizing objects are, (a) they tend to look at the most discriminative features in an image that confines the localization map to a very small region, (b) the localization maps are class agnostic, and the models highlight objects of multiple classes in the same image and, (c) the localization performance is affected by background noise. To alleviate the above challenges we introduce the following simple changes through our proposed method ViTOL. We leverage the vision-based transformer for self-attention and introduce a patch-based attention dropout layer (p-ADL) to increase the coverage of the localization map and a gradient attention rollout mechanism to generate class-dependent attention maps. We conduct extensive quantitative, qualitative and ablation experiments on the ImageNet-1K and CUB datasets. We achieve state-of-the-art MaxBoxAcc-V2 localization scores of 70.47% and 73.17% on the two datasets respectively. Code is available on https://github.com/Saurav-31/ViTOL
Multi-Robot Formation Control Using Reinforcement Learning
Jan 13, 2020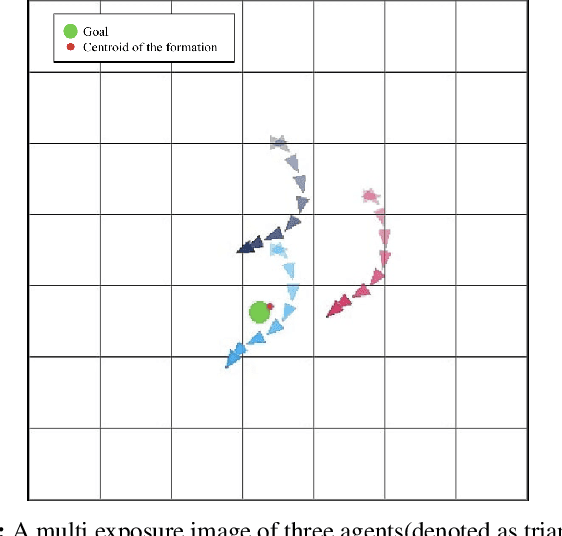
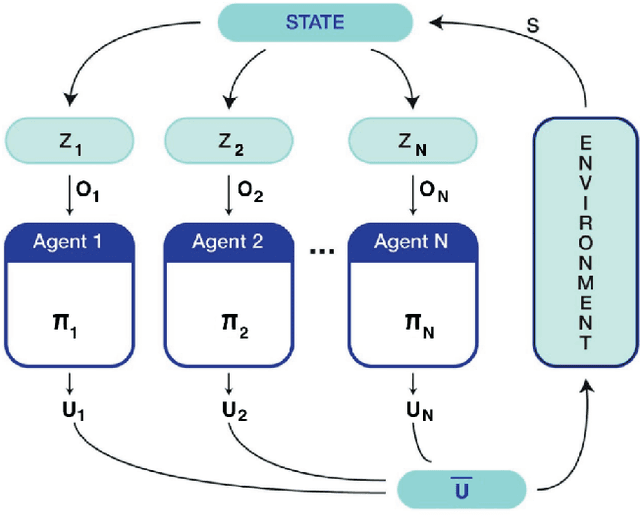
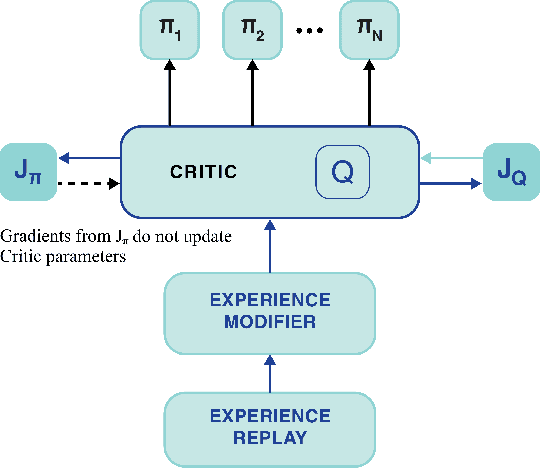
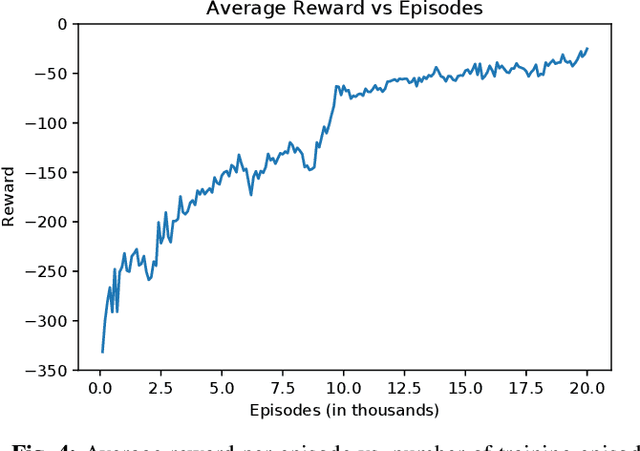
In this paper, we present a machine learning approach to move a group of robots in a formation. We model the problem as a multi-agent reinforcement learning problem. Our aim is to design a control policy for maintaining a desired formation among a number of agents (robots) while moving towards a desired goal. This is achieved by training our agents to track two agents of the group and maintain the formation with respect to those agents. We consider all agents to be homogeneous and model them as unicycle [1]. In contrast to the leader-follower approach, where each agent has an independent goal, our approach aims to train the agents to be cooperative and work towards the common goal. Our motivation to use this method is to make a fully decentralized multi-agent formation system and scalable for a number of agents.
Loosely Coupled Payload Transport System with Robot Replacement
Apr 05, 2019
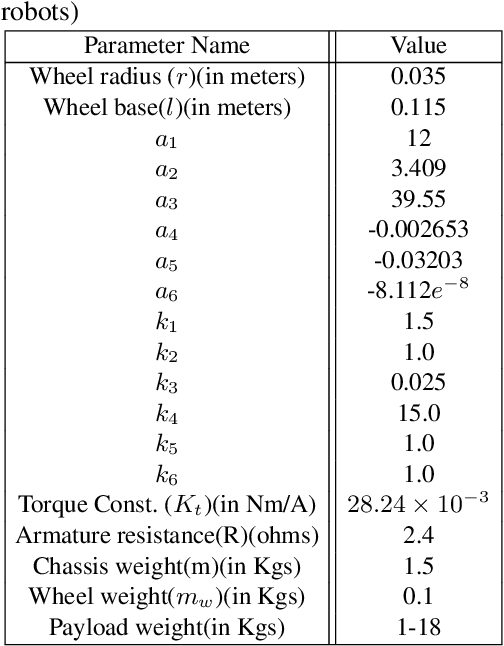
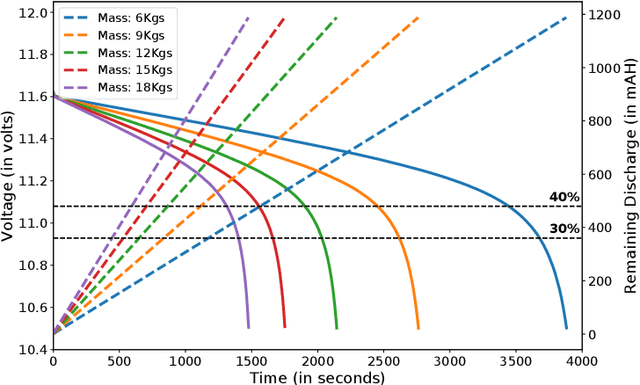
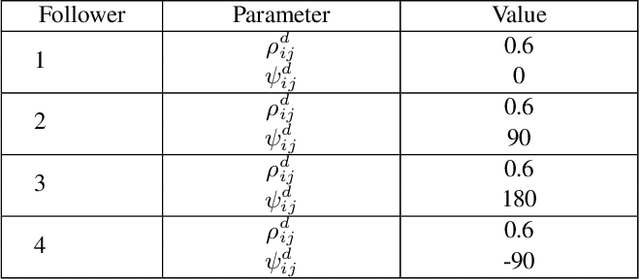
In this work, we present an algorithm for robot replacement to increase the operational time of a multi-robot payload transport system. Our system comprises a group of nonholonomic wheeled mobile robots traversing on a known trajectory. We design a multi-robot system with loosely coupled robots that ensures the system lasts much longer than the battery life of an individual robot. A system level optimization is presented, to decide on the operational state (charging or discharging) of each robot in the system. The charging state implies that the robot is not in a formation and is kept on charge whereas the discharging state implies that the robot is a part of the formation. Robot battery recharge hubs are present along the trajectory. Robots in the formation can be replaced at these hub locations with charged robots using a replacement mechanism. We showcase the efficacy of the proposed scheduling framework through simulations and experiments with real robots.
* 20 Pages