 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymGS : Leveraging Local Symmetries for 3D Gaussian Splatting Compression
Nov 19, 2025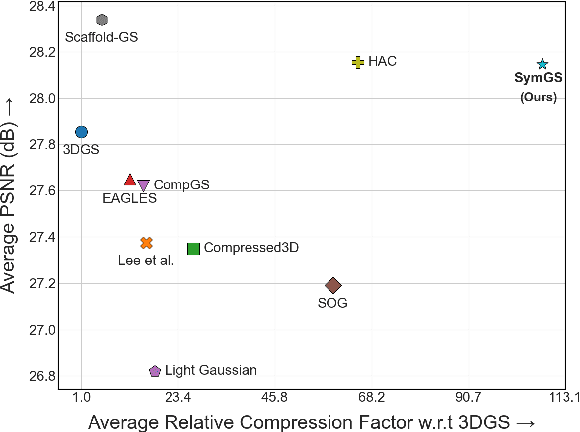



3D Gaussian Splatting has emerged as a transformative technique in novel view synthesis, primarily due to its high rendering speed and photorealistic fidelity. However, its memory footprint scales rapidly with scene complexity, often reaching several gigabytes. Existing methods address this issue by introducing compression strategies that exploit primitive-level redundancy through similarity detection and quantization. We aim to surpass the compression limits of such methods by incorporating symmetry-aware techniques, specifically targeting mirror symmetries to eliminate redundant primitives. We propose a novel compression framework, SymGS, introducing learnable mirrors into the scene, thereby eliminating local and global reflective redundancies for compression. Our framework functions as a plug-and-play enhancement to state-of-the-art compression methods, (e.g. HAC) to achieve further compression. Compared to HAC, we achieve $1.66 \times$ compression across benchmark datasets (upto $3\times$ on large-scale scenes). On an average, SymGS enables $\bf{108\times}$ compression of a 3DGS scene, while preserving rendering quality. The project page and supplementary can be found at symgs.github.io
LightHeadEd: Relightable & Editable Head Avatars from a Smartphone
Apr 13, 2025Creating photorealistic, animatable, and relightable 3D head avatars traditionally requires expensive Lightstage with multiple calibrated cameras, making it inaccessible for widespread adoption. To bridge this gap, we present a novel, cost-effective approach for creating high-quality relightable head avatars using only a smartphone equipped with polaroid filters. Our approach involves simultaneously capturing cross-polarized and parallel-polarized video streams in a dark room with a single point-light source, separating the skin's diffuse and specular components during dynamic facial performances. We introduce a hybrid representation that embeds 2D Gaussians in the UV space of a parametric head model, facilitating efficient real-time rendering while preserving high-fidelity geometric details. Our learning-based neural analysis-by-synthesis pipeline decouples pose and expression-dependent geometrical offsets from appearance, decomposing the surface into albedo, normal, and specular UV texture maps, along with the environment maps. We collect a unique dataset of various subjects performing diverse facial expressions and head movements.
SynthForge: Synthesizing High-Quality Face Dataset with Controllable 3D Generative Models
Jun 12, 2024



Recent advancements in generative models have unlocked the capabilities to render photo-realistic data in a controllable fashion. Trained on the real data, these generative models are capable of producing realistic samples with minimal to no domain gap, as compared to the traditional graphics rendering. However, using the data generated using such models for training downstream tasks remains under-explored, mainly due to the lack of 3D consistent annotations. Moreover, controllable generative models are learned from massive data and their latent space is often too vast to obtain meaningful sample distributions for downstream task with limited generation. To overcome these challenges, we extract 3D consistent annotations from an existing controllable generative model, making the data useful for downstream tasks. Our experiments show competitive performance against state-of-the-art models using only generated synthetic data, demonstrating potential for solving downstream tasks. Project page: https://synth-forge.github.io
WordRobe: Text-Guided Generation of Textured 3D Garments
Mar 26, 2024In this paper, we tackle a new and challenging problem of text-driven generation of 3D garments with high-quality textures. We propose "WordRobe", a novel framework for the generation of unposed & textured 3D garment meshes from user-friendly text prompts. We achieve this by first learning a latent representation of 3D garments using a novel coarse-to-fine training strategy and a loss for latent disentanglement, promoting better latent interpolation. Subsequently, we align the garment latent space to the CLIP embedding space in a weakly supervised manner, enabling text-driven 3D garment generation and editing. For appearance modeling, we leverage the zero-shot generation capability of ControlNet to synthesize view-consistent texture maps in a single feed-forward inference step, thereby drastically decreasing the generation time as compared to existing methods. We demonstrate superior performance over current SOTAs for learning 3D garment latent space, garment interpolation, and text-driven texture synthesis, supported by quantitative evaluation and qualitative user study. The unposed 3D garment meshes generated using WordRobe can be directly fed to standard cloth simulation & animation pipelines without any post-processing.
Dress-Me-Up: A Dataset & Method for Self-Supervised 3D Garment Retargeting
Jan 06, 2024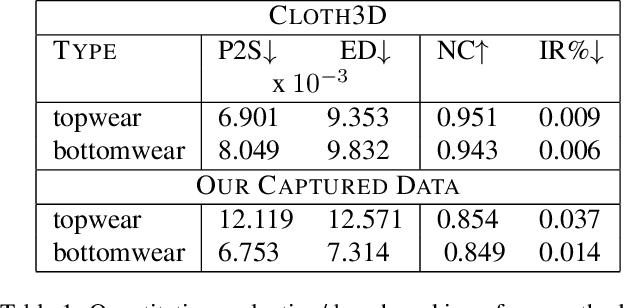
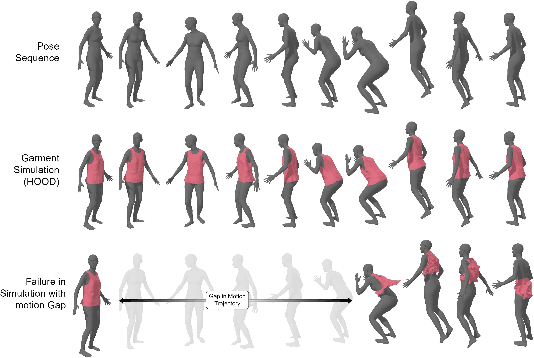
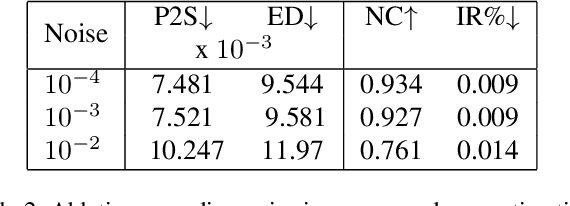
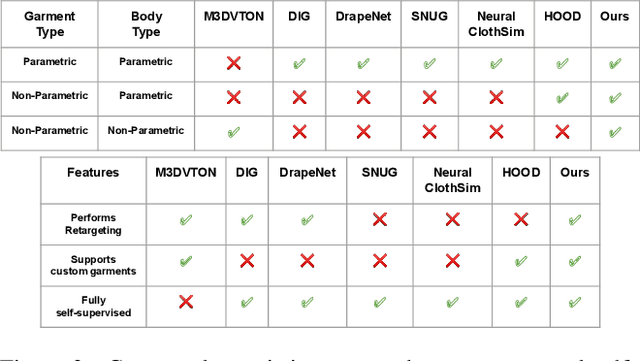
We propose a novel self-supervised framework for retargeting non-parameterized 3D garments onto 3D human avatars of arbitrary shapes and poses, enabling 3D virtual try-on (VTON). Existing self-supervised 3D retargeting methods only support parametric and canonical garments, which can only be draped over parametric body, e.g. SMPL. To facilitate the non-parametric garments and body, we propose a novel method that introduces Isomap Embedding based correspondences matching between the garment and the human body to get a coarse alignment between the two meshes. We perform neural refinement of the coarse alignment in a self-supervised setting. Further, we leverage a Laplacian detail integration method for preserving the inherent details of the input garment. For evaluating our 3D non-parametric garment retargeting framework, we propose a dataset of 255 real-world garments with realistic noise and topological deformations. The dataset contains $44$ unique garments worn by 15 different subjects in 5 distinctive poses, captured using a multi-view RGBD capture setup. We show superior retargeting quality on non-parametric garments and human avatars over existing state-of-the-art methods, acting as the first-ever baseline on the proposed dataset for non-parametric 3D garment retargeting.
xCloth: Extracting Template-free Textured 3D Clothes from a Monocular Image
Aug 27, 2022

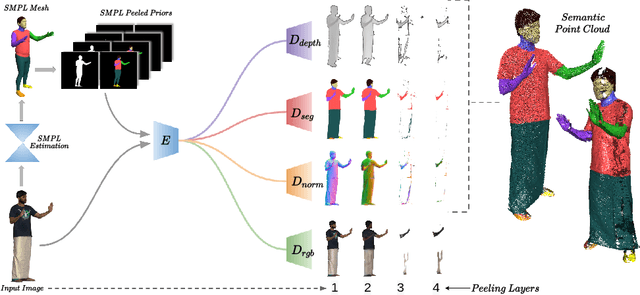
Existing approaches for 3D garment reconstruction either assume a predefined template for the garment geometry (restricting them to fixed clothing styles) or yield vertex colored meshes (lacking high-frequency textural details). Our novel framework co-learns geometric and semantic information of garment surface from the input monocular image for template-free textured 3D garment digitization. More specifically, we propose to extend PeeledHuman representation to predict the pixel-aligned, layered depth and semantic maps to extract 3D garments. The layered representation is further exploited to UV parametrize the arbitrary surface of the extracted garment without any human intervention to form a UV atlas. The texture is then imparted on the UV atlas in a hybrid fashion by first projecting pixels from the input image to UV space for the visible region, followed by inpainting the occluded regions. Thus, we are able to digitize arbitrarily loose clothing styles while retaining high-frequency textural details from a monocular image. We achieve high-fidelity 3D garment reconstruction results on three publicly available datasets and generalization on internet images.
SHARP: Shape-Aware Reconstruction of People in Loose Clothing
May 24, 2022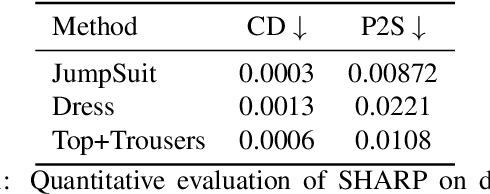
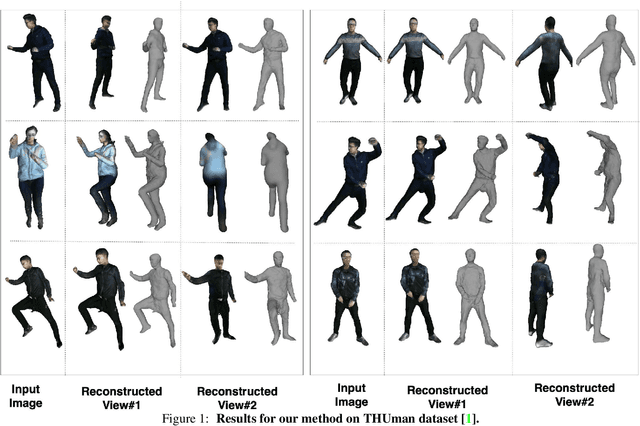
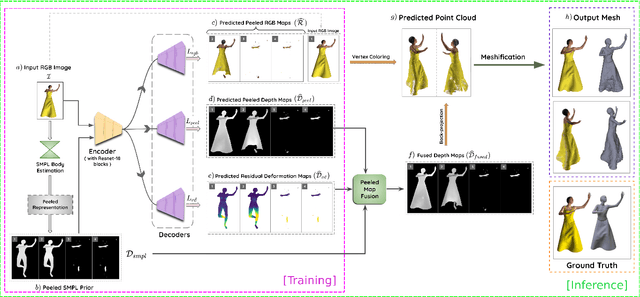
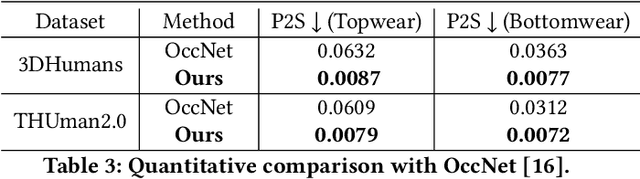
Recent advancements in deep learning have enabled 3D human body reconstruction from a monocular image, which has broad applications in multiple domains. In this paper, we propose SHARP (SHape Aware Reconstruction of People in loose clothing), a novel end-to-end trainable network that accurately recovers the 3D geometry and appearance of humans in loose clothing from a monocular image. SHARP uses a sparse and efficient fusion strategy to combine parametric body prior with a non-parametric 2D representation of clothed humans. The parametric body prior enforces geometrical consistency on the body shape and pose, while the non-parametric representation models loose clothing and handle self-occlusions as well. We also leverage the sparseness of the non-parametric representation for faster training of our network while using losses on 2D maps. Another key contribution is 3DHumans, our new life-like dataset of 3D human body scans with rich geometrical and textural details. We evaluate SHARP on 3DHumans and other publicly available datasets and show superior qualitative and quantitative performance than existing state-of-the-art methods.
Robust 3D Garment Digitization from Monocular 2D Images for 3D Virtual Try-On Systems
Nov 30, 2021

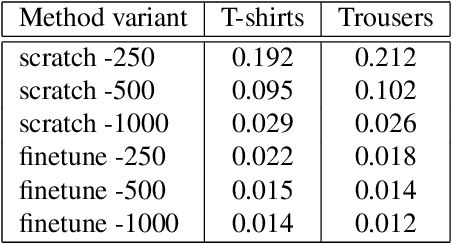

In this paper, we develop a robust 3D garment digitization solution that can generalize well on real-world fashion catalog images with cloth texture occlusions and large body pose variations. We assumed fixed topology parametric template mesh models for known types of garments (e.g., T-shirts, Trousers) and perform mapping of high-quality texture from an input catalog image to UV map panels corresponding to the parametric mesh model of the garment. We achieve this by first predicting a sparse set of 2D landmarks on the boundary of the garments. Subsequently, we use these landmarks to perform Thin-Plate-Spline-based texture transfer on UV map panels. Subsequently, we employ a deep texture inpainting network to fill the large holes (due to view variations & self-occlusions) in TPS output to generate consistent UV maps. Furthermore, to train the supervised deep networks for landmark prediction & texture inpainting tasks, we generated a large set of synthetic data with varying texture and lighting imaged from various views with the human present in a wide variety of poses. Additionally, we manually annotated a small set of fashion catalog images crawled from online fashion e-commerce platforms to finetune. We conduct thorough empirical evaluations and show impressive qualitative results of our proposed 3D garment texture solution on fashion catalog images. Such 3D garment digitization helps us solve the challenging task of enabling 3D Virtual Try-on.
SHARP: Shape-Aware Reconstruction of People In Loose Clothing
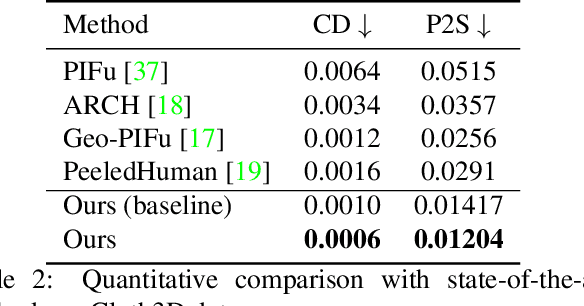
Jun 17, 20213D human body reconstruction from monocular images is an interesting and ill-posed problem in computer vision with wider applications in multiple domains. In this paper, we propose SHARP, a novel end-to-end trainable network that accurately recovers the detailed geometry and appearance of 3D people in loose clothing from a monocular image. We propose a sparse and efficient fusion of a parametric body prior with a non-parametric peeled depth map representation of clothed models. The parametric body prior constraints our model in two ways: first, the network retains geometrically consistent body parts that are not occluded by clothing, and second, it provides a body shape context that improves prediction of the peeled depth maps. This enables SHARP to recover fine-grained 3D geometrical details with just L1 losses on the 2D maps, given an input image. We evaluate SHARP on publicly available Cloth3D and THuman datasets and report superior performance to state-of-the-art approaches.