 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexCloth: Extracting Template-free Textured 3D Clothes from a Monocular Image
Aug 27, 2022

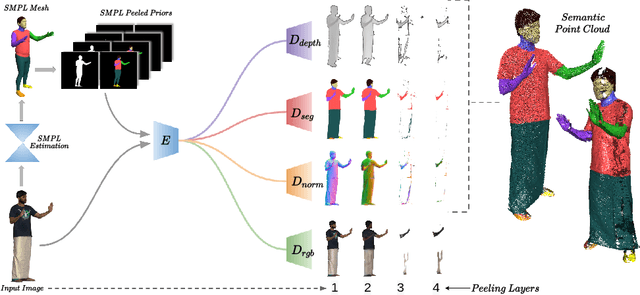
Existing approaches for 3D garment reconstruction either assume a predefined template for the garment geometry (restricting them to fixed clothing styles) or yield vertex colored meshes (lacking high-frequency textural details). Our novel framework co-learns geometric and semantic information of garment surface from the input monocular image for template-free textured 3D garment digitization. More specifically, we propose to extend PeeledHuman representation to predict the pixel-aligned, layered depth and semantic maps to extract 3D garments. The layered representation is further exploited to UV parametrize the arbitrary surface of the extracted garment without any human intervention to form a UV atlas. The texture is then imparted on the UV atlas in a hybrid fashion by first projecting pixels from the input image to UV space for the visible region, followed by inpainting the occluded regions. Thus, we are able to digitize arbitrarily loose clothing styles while retaining high-frequency textural details from a monocular image. We achieve high-fidelity 3D garment reconstruction results on three publicly available datasets and generalization on internet images.
SHARP: Shape-Aware Reconstruction of People in Loose Clothing
May 24, 2022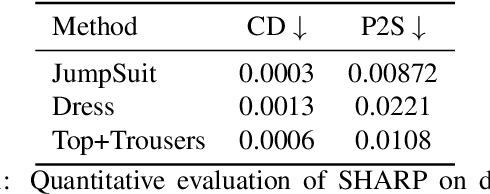
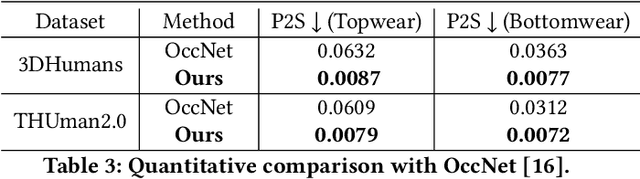
Recent advancements in deep learning have enabled 3D human body reconstruction from a monocular image, which has broad applications in multiple domains. In this paper, we propose SHARP (SHape Aware Reconstruction of People in loose clothing), a novel end-to-end trainable network that accurately recovers the 3D geometry and appearance of humans in loose clothing from a monocular image. SHARP uses a sparse and efficient fusion strategy to combine parametric body prior with a non-parametric 2D representation of clothed humans. The parametric body prior enforces geometrical consistency on the body shape and pose, while the non-parametric representation models loose clothing and handle self-occlusions as well. We also leverage the sparseness of the non-parametric representation for faster training of our network while using losses on 2D maps. Another key contribution is 3DHumans, our new life-like dataset of 3D human body scans with rich geometrical and textural details. We evaluate SHARP on 3DHumans and other publicly available datasets and show superior qualitative and quantitative performance than existing state-of-the-art methods.
SHARP: Shape-Aware Reconstruction of People In Loose Clothing
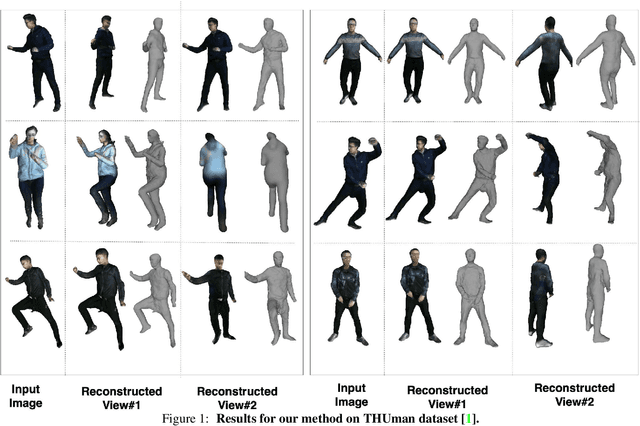
Jun 17, 20213D human body reconstruction from monocular images is an interesting and ill-posed problem in computer vision with wider applications in multiple domains. In this paper, we propose SHARP, a novel end-to-end trainable network that accurately recovers the detailed geometry and appearance of 3D people in loose clothing from a monocular image. We propose a sparse and efficient fusion of a parametric body prior with a non-parametric peeled depth map representation of clothed models. The parametric body prior constraints our model in two ways: first, the network retains geometrically consistent body parts that are not occluded by clothing, and second, it provides a body shape context that improves prediction of the peeled depth maps. This enables SHARP to recover fine-grained 3D geometrical details with just L1 losses on the 2D maps, given an input image. We evaluate SHARP on publicly available Cloth3D and THuman datasets and report superior performance to state-of-the-art approaches.
PeelNet: Textured 3D reconstruction of human body using single view RGB image
Feb 16, 2020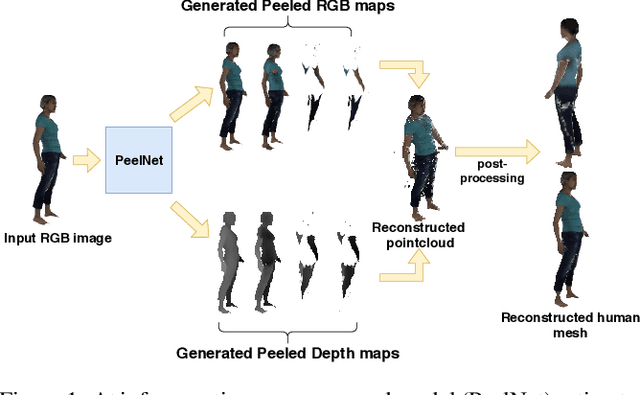


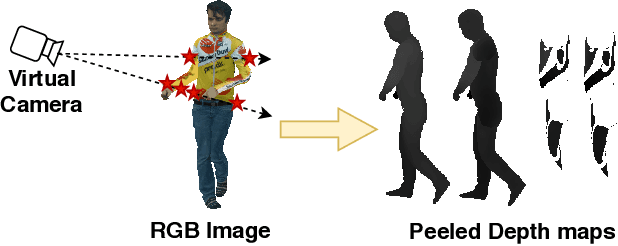
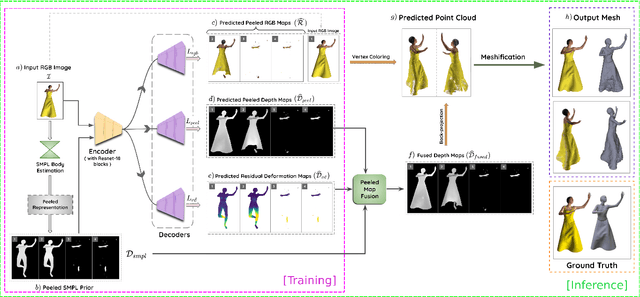
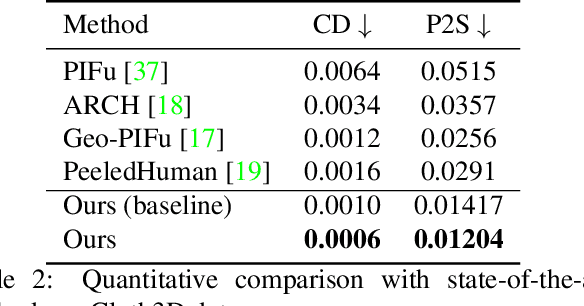
Reconstructing human shape and pose from a single image is a challenging problem due to issues like severe self-occlusions, clothing variations, and changes in lighting to name a few. Many applications in the entertainment industry, e-commerce, health-care (physiotherapy), and mobile-based AR/VR platforms can benefit from recovering the 3D human shape, pose, and texture. In this paper, we present PeelNet, an end-to-end generative adversarial framework to tackle the problem of textured 3D reconstruction of the human body from a single RGB image. Motivated by ray tracing for generating realistic images of a 3D scene, we tackle this problem by representing the human body as a set of peeled depth and RGB maps which are obtained by extending rays beyond the first intersection with the 3D object. This formulation allows us to handle self-occlusions efficiently. Current parametric model-based approaches fail to model loose clothing and surface-level details and are proposed for the underlying naked human body. Majority of non-parametric approaches are either computationally expensive or provide unsatisfactory results. We present a simple non-parametric solution where the peeled maps are generated from a single RGB image as input. Our proposed peeled depth maps are back-projected to 3D volume to obtain a complete 3D shape. The corresponding RGB maps provide vertex-level texture details. We compare our method against current state-of-the-art methods in 3D reconstruction and demonstrate the effectiveness of our method on BUFF and MonoPerfCap datasets.
Deep Textured 3D Reconstruction of Human Bodies
Sep 18, 2018
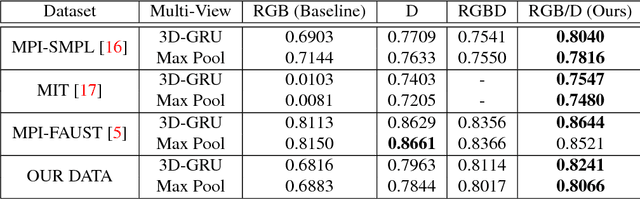


Recovering textured 3D models of non-rigid human body shapes is challenging due to self-occlusions caused by complex body poses and shapes, clothing obstructions, lack of surface texture, background clutter, sparse set of cameras with non-overlapping fields of view, etc. Further, a calibration-free environment adds additional complexity to both - reconstruction and texture recovery. In this paper, we propose a deep learning based solution for textured 3D reconstruction of human body shapes from a single view RGB image. This is achieved by first recovering the volumetric grid of the non-rigid human body given a single view RGB image followed by orthographic texture view synthesis using the respective depth projection of the reconstructed (volumetric) shape and input RGB image. We propose to co-learn the depth information readily available with affordable RGBD sensors (e.g., Kinect) while showing multiple views of the same object during the training phase. We show superior reconstruction performance in terms of quantitative and qualitative results, on both, publicly available datasets (by simulating the depth channel with virtual Kinect) as well as real RGBD data collected with our calibrated multi Kinect setup.